문과 아재도 쉽게하는 R 데이터 분석 – (7) 협업 필터링(Collaborative Filtering)
추천시스템 - 협업필터링
사람들의 입맛을 만족시키는 것은 굉장히 어렵습니다. 당장 점심메뉴만 해도 굉장히 선택하기 힘든데, 한끼한끼가 소중한 애인과의 데이트는 신중히 결정하여야 하는게 사실입니다.
하지만 당신은 굉장히 능숙한 애인 전문가이기 때문에 상당히 많은 사람과 데이트한 결과를 잘 정리해놓은 표가 있습니다. 이러한 상황에서 당신은 정말 마음에 드는 이상형과 소개팅을 하게 되었고 소개팅 이성은 태국음식인 똠양꿍을 나름 좋아하는것처럼 보였기에, 다음의 만남에서도 신중하게 음식을 고르기로 합니다.
현재 이상형 데이터베이스를 가지고 있는 뇌속의 구조는 이렇습니다.
|음식| 김태형 | 송혜형 | 전지형 | 설형 |한가형| 이상형 |
|---|---|---|---|---|---|---|
|짬뽕| 1 | 4 | 2 | 5 | 3 | ? |
|짜장면| 2 | 5 | 3 | 4 | 4 | 3 |
|탕수육| 1 | 5 | 3 | 1 | 1 | ? |
|한식| 5 | 2 | 5 | 1 | 5 | ? |
|똠양꿍| 4 | 2 | 5 | 1 | 3 | 5 |
|빅맥| 3 | 1 | 1 | 5 | 3 | ? |
스티밋은 advance markdown은 지원하지 않아 테이블형태로 예쁘게 나오진않네요..
자 현재의 이상형에 대한 데이터는 아직 썸만 타는 상황이기 때문에 충분하지는 않지만, 지금까지의 힌트를 보고 다시 예전에 만났던 사람들과의 비교를 통해 비슷하려니 하고 생각해볼 수 있습니다.
어떻게 보면, 새로운 사람을 봤을때 인상만으로 바로 '셀것같다, 성격이 좋을것같다'라고 빨리 결정하는 것처럼 지금까지의 데이터로 유추해보는 과정일수 있습니다.
보통의 사람들은 하나를 좋아하면 비스무리한 다른것도 좋아하는 경향이 있으며, 헙업필터링은 이를 이용해서 다른사람들이 사전에 해놓은 데이터를 배경으로 빠르게 다른 물건들을 해줍니다.
예를들어 인터넷 서점의 경우, 수많은 책들중에 내가 구입한건 거의 한두개인데 이를 바탕으로 빠르게 다른 비슷한 책들을 추천해야하는 인터넷 서점의 경우에 딱 들어맞게 사용할수 있는것입니다. 넷플릭스와 다른 컨텐츠 추천 서비스들도 비슷하게 돌아가고 있습니다.
arules 에서 제공하는 기능 쓰기
사실, 차있지 않은 행렬은 대부분 값이 NULL이나 0이 저장되어야하므로 공간만 차지하고 쓸모가 없어서 희소행렬이라는 특별한 행렬을 이용합니다.
데이터는 아래와 같습니다.
https://github.com/stedy/Machine-Learning-with-R-datasets/blob/master/groceries.csv
> library(arules)
> groceries <- read.transactions("groceries.csv", sep=",")
> summary(groceries)
transactions as itemMatrix in sparse format with
9835 rows (elements/itemsets/transactions) and
169 columns (items) and a density of 0.02609146
most frequent items:
whole milk other vegetables rolls/buns soda yogurt (Other)
2513 1903 1809 1715 1372 34055
element (itemset/transaction) length distribution:
sizes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
2159 1643 1299 1005 855 645 545 438 350 246 182 117 78 77 55 46 29 14 14 9 11
22 23 24 26 27 28 29 32
4 6 1 1 1 1 3 1
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 2.000 3.000 4.409 6.000 32.000
includes extended item information - examples:
labels
1 abrasive cleaner
2 artif. sweetener
3 baby cosmetics
arules 에서 제공하는 기능을 쓰면, 실제로 어떤 열에 어떤 데이터가 있는지, 몇개가 있는지 상관없이 한줄에 하나씩 쓰면 됩니다.
최대 32개를 한꺼번에 구매한 사람도 있으며, 딱 하나만 산 사람도 존재합니다. 어떻게 무슨 물품을 샀는지 확인하려면 아래와 같이 적습니다.
> inspect(groceries[1:5])
items
[1] {citrus fruit,
margarine,
ready soups,
semi-finished bread}
[2] {coffee,
tropical fruit,
yogurt}
[3] {whole milk}
[4] {cream cheese,
meat spreads,
pip fruit,
yogurt}
[5] {condensed milk,
long life bakery product,
other vegetables,
whole milk}
아이템별 빈도 확인과 시각화
> itemFrequency(groceries[,1:3])
abrasive cleaner artif. sweetener baby cosmetics
0.0035587189 0.0032536858 0.0006100661
> itemFrquencyPlot(groceries, support = 0.1)
> itemFrequencyPlot(groceries, topN = 20)
> image(groceries[1:5])
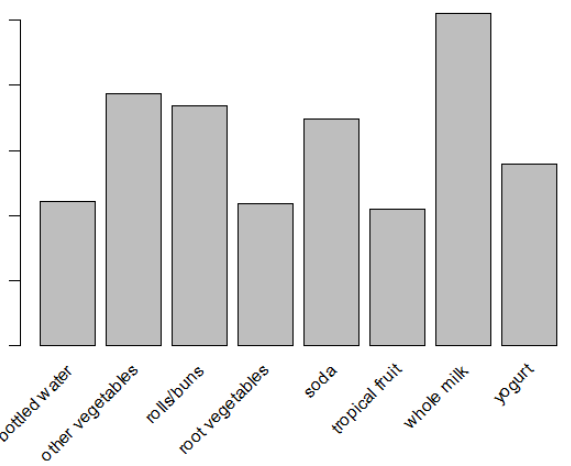
이는 지지도 0.1이상만 보여주는 시각화 자료로써, support는 전체 갯수중 몇개가 있나를 살펴볼수 있습니다. 전체 아이템이 아닌 전체 거래중 특정 아이템이 포함된 놈만 해당되는걸 알수있습니다.
다음 그래프는 희소행렬(대부분이 0인 행렬)의 시각화도 확인할수 있습니다.
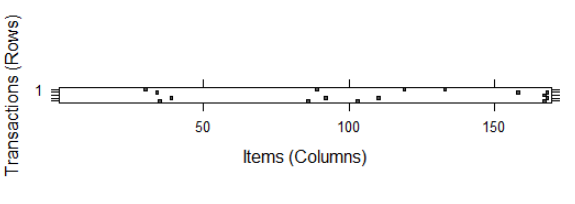
희소행렬은 실무에서 많이 접하는 경우로, 대부분의 데이터가 비어있는 상태를 뜻합니다. 장바구니 분석이라고 불리는 협업필터링 방식은 아무래도 한사람 한사람이 데이터 한줄로 들어가게 되는데, 대부분 엄청난 품목중에 몇가지만 사기 때문에 그것만 빼면 모두 0이 되는 데이터 형태겠죠? 그래서 데이터 공간이 낭비되지 않게 transaction이라는 특수한 함수로 데이터를 불러오게 되는것입니다.
지지도(support)
어떤 아이템을 구입했다면, 전체 N개의 거래중에 실제로 해당하는 아이템이 있는 거래가 몇건인지 알려줍니다. 어느정도 지지도를 확보하지 않으면, 얼마 팔리지도 않는 물건을 굳이 분석하려 됩니다. 우리가 원하는건 어느정도 팔리면서도 보이지 않는 관계, 인사이트를 발견하기 위해서니, 지지도는 일정 이상을 챙깁시다.
신뢰도(confidence)
어떤 A아이템이 포함된 거래중, A와 B거래가 모두 포함된 거래의 비율을 말합니다. 즉 어느정도의 지지도를 확보한 아이템A이 거래된 게 100건이라면, A,B가 동시에 거래된 건수가 80건이면 0.8이 됩니다.
리프트(lift)
사실 단순하게 생각하면 신뢰도까지만 구해서 제일 높은 것부터 내림차순 해서 보면 된다고 생각할수도 있는데, B가 원래 많이 구매되는 아이템이라면 높은 신뢰도가 필요가 없을겁니다. B가 마치 대형마트에 물같은 존재라면 굉장히 많은 사람들이 구매하는 품목이며 이는 신뢰도가 높을수밖에 없습니다.
이럴때는, 신뢰도를 지지도로 나눠주어 1보다 큰지 보는 방법을 이용합니다. 1보다 크면 A와 B가 연관이 있는것이고, A를 사면 B도 사는 확률이 높다고 좀더 자신감있게 말할수 있는겁니다.
apriori 함수
apriori(groceries)
를 통해 함수를 실행하면 set of 0 rules 라는 문구가 나옵니다. 이는 기본적으로 0.1의 지지도가 설정되어있는데, 하루에 0.1의 지지도를 나타내는 아이템은 아까 플롯에서 살펴보았듯이 몇개 되지도 않기 때문에 모수가 적어져 버리는 단점이 있습니다.
> gr <- apriori(groceries, parameter = list(support = 0.006, confidence = 0.25, minlen = 2))
> inspect(sort(gr, by = "lift")[1:20])
lhs rhs support confidence
[1] {herbs} => {root vegetables} 0.007015760 0.4312500
[2] {berries} => {whipped/sour cream} 0.009049314 0.2721713
[3] {other vegetables,tropical fruit,whole milk} => {root vegetables} 0.007015760 0.4107143
[4] {beef,other vegetables} => {root vegetables} 0.007930859 0.4020619
[5] {other vegetables,tropical fruit} => {pip fruit} 0.009456024 0.2634561
[6] {beef,whole milk} => {root vegetables} 0.008032537 0.3779904
[7] {other vegetables,pip fruit} => {tropical fruit} 0.009456024 0.3618677
[8] {pip fruit,yogurt} => {tropical fruit} 0.006405694 0.3559322
[9] {citrus fruit,other vegetables} => {root vegetables} 0.010371124 0.3591549
[10] {other vegetables,whole milk,yogurt} => {tropical fruit} 0.007625826 0.3424658
[11] {other vegetables,whole milk,yogurt} => {root vegetables} 0.007829181 0.3515982
[12] {tropical fruit,whipped/sour cream} => {yogurt} 0.006202339 0.4485294
[13] {other vegetables,tropical fruit,whole milk} => {yogurt} 0.007625826 0.4464286
[14] {other vegetables,rolls/buns,whole milk} => {root vegetables} 0.006202339 0.3465909
[15] {frozen vegetables,other vegetables} => {root vegetables} 0.006100661 0.3428571
[16] {other vegetables,tropical fruit} => {root vegetables} 0.012302999 0.3427762
[17] {sliced cheese} => {sausage} 0.007015760 0.2863071
[18] {other vegetables,tropical fruit} => {citrus fruit} 0.009049314 0.2521246
[19] {beef} => {root vegetables} 0.017386884 0.3313953
[20] {citrus fruit,root vegetables} => {other vegetables} 0.010371124 0.5862069
lift count
[1] 3.956477 69
[2] 3.796886 89
[3] 3.768074 69
[4] 3.688692 78
[5] 3.482649 93
[6] 3.467851 79
[7] 3.448613 93
[8] 3.392048 63
[9] 3.295045 102
[10] 3.263712 75
[11] 3.225716 77
[12] 3.215224 61
[13] 3.200164 75
[14] 3.179778 61
[15] 3.145522 60
[16] 3.144780 121
[17] 3.047435 69
[18] 3.046248 89
[19] 3.040367 171
[20] 3.029608 102
특정한 물품이 포함된 것을 찾고싶으면 아래처럼 사용할수도 있습니다.
br <- subset(gr, items %in% "berries")
inspect(br)
lhs rhs support confidence lift count
[1] {berries} => {whipped/sour cream} 0.009049314 0.2721713 3.796886 89
[2] {berries} => {yogurt} 0.010574479 0.3180428 2.279848 104
[3] {berries} => {other vegetables} 0.010269446 0.3088685 1.596280 101
[4] {berries} => {whole milk} 0.011794611 0.3547401 1.388328 116
베리를 구입하면 사워크림을 구입하는 신기한 사실을 발견했습니다. 아마 빵을 발라먹을때 베리와 사워크림을 쟁여놓고 먹게 되겠죠? 만약 이를 확인한 마케팅 담당자라면 이를 확인하고 둘을 하나로 묶는 패키지를 만들어서 소비자의 편의나 추가 매출을 올릴수 있을것입니다.
치즈를 사면 햄을 사는 경우도 있네요. 안주를 한꺼번에 구비하려는 것일까요? 이렇게 협업필터링은 의외의 조합을 발견하기도, 당연한 조합을 발견하기도 합니다. 그 다음 액션은 아마 업종 전문가가 등장해서 여러가지 판단을 하면 되겠죠?
몇가지 마무리하면서 조심해야할 점을 말해보면, 지지도를 너무 높게 잡으면 왠만한 대상 아이템들이 다 쓸려나가며, 너무 낮게 잡으면 별로 중요하지 않은 아이템까지 고려대상이 되어 아무 인사이트를 발견하지 못할수도 있습니다. 이 숫자는 업종마다 다를수있을것입니다.
안녕하세요. 글 잘 읽고 있습니다. 혹시 'recommenderlab' 패키지를 이용한 방법은 없을까요?