문과 아재도 쉽게하는 R 데이터 분석 – (6) 군집(K means Clustering)
클러스터링을 통한 데이터 세분화 이해
마케팅 분야에서는 시장세분화를 통해 각 단계별로 마케팅해서 고객에게 빠르게 노출시키고 이들을 돈을 쓰게 만드는것이 중요합니다. 경영학 서적을 들춰보면 여러 인구통계학적 변수(연령, 성별, 지역 등)과 심리분석적 변수(사회계층, 심리분석적 등)에 따라 나눠서 시장을 진출하라 말합니다.
하지만 실무자가 시장을 세분화하기에는 다음의 문제에 봉착합니다.
- 어떤 기준으로 시장을 나눌것인가? 대리가 구글링해서? 경험많은 부장이 감으로?
- 나누긴 나눴는데 정말 맞게 나눈것인가?
- 필요없는 마케팅 변수들을 엑셀로 나열해놓고 일 열심히 했다고 스스로 만족감에 흡족한것이 아닌가?
실무입장에서는 시장세분화까지만 이야기 하고 떠나는 경영학원론이 원망스러울수밖에 없습니다. 그리고 모든걸 설문조사로 할수도 없는 노릇입니다. 이럴 때 데이터를 분석해서 시장을 세분화해서 들어간다면 실용적이고 업무의사결정도 근거가 탄탄해질 것입니다.
쉽게 게임회사를 예로 들어봅시다. 핵과금유저, 소과금유저, 무과금유저.. 모바일게임 산업이 급성장하면서, 컨텐츠를 무료로 제공하는 대신 게임 내 결제 기능을 특수화 한 게임들이 대부분을 차지하고 있습니다. 모바일 게임은 그 완성도도 완성도지만 무조건 초기 마케팅과 물들어올때 노젓는 타이밍 공략이 중요합니다. 그렇다면 어떻게 공략을 해야할까요? 일단 지금까지의 모바일 게임 데이터가 축적되어있다면 고객을 일단 나눠보는것(Segmentation)도 중요할것입니다.
K-means 이해하기
K-means는 대표적인 군집화 모델입니다. 짧게 말하면 몇개로 나눌것인지만 정한 후 데이터를 흩뿌려놓고 제일 가까운것끼리 짝지어주는 것입니다. 아래와 같이 데이터가 있다고 한번 생각해봅니다. 다른 훈련알고리즘과는 다르게 굳이 라벨링을 해줄 필요가 없습니다. 컴퓨터가 알아서 계산을 하면서 다 나눠줄것이기 때문이죠. 우리가 할건 몇개로 나눌것인가만 설정해주는것입니다.

이 중, 우리는 K값을 3으로 정했는데 K-means에는 처음 데이터중 아무 데이터를 임의로 잡게됩니다. (이 점을 잡는 몇가지 방법이 더 있기는 합니다.)
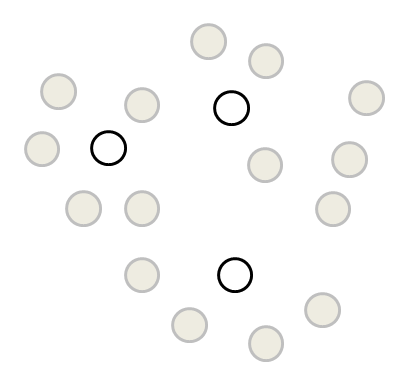
그리고 일단 각각의 점에 가까운 점들의 거리를 계산하여 제일 가까운 곳으로 1차로 군집화합니다.
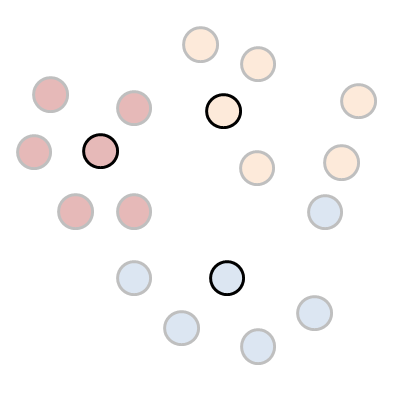
하지만 이렇게 간단하면 데이터분석이라고 말할수도 없을것입니다. 일단, 구별된 각각의 클러스터의 평균 (Means) 를 구합니다.
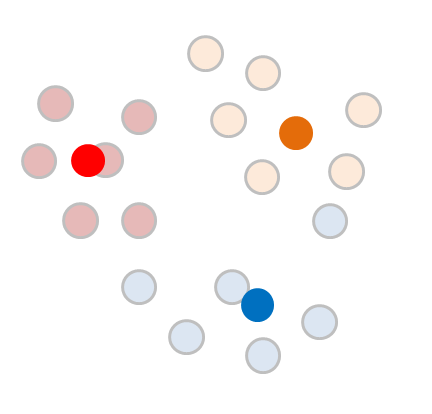
구해진 평균값을 다시한번 중심점(Centroid)로 두고 이를 중심으로 다시 군집(Cluster) 를 재조정합니다.
앗! 데이터중 하나는 바뀐 중심점때문에 클러스터가 파란색에서 주황색으로 바뀌었습니다. 그럼 여기서 땡일까요?
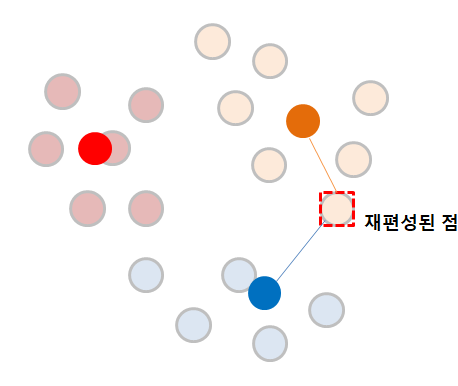
이제 이 점이 새롭게 다시 재편성이 되었으니, 다시한변 평균값을 또 구해야 합니다.
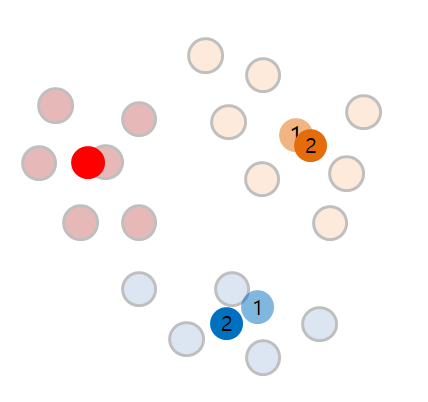
이제 다시 평균값은 1 -> 2로 바뀌게 되었습니다.
이제부터 계속 반복입니다.
이렇게, 바뀐 중심점을 기준으로 다시한번 거리를 계산하게 되어 계속해서 클러스터의 범위가 바뀌게 되며, 더이상 클러스터의 변동이 없는경우 최종적으로 클러스터를 확정짓게 합니다. 어때요? 참 쉽죠?
R을 통한 K-means 해보기
함수이용은 너무나도 쉽습니다. 아무런 라이브러리도 필요없고 kmeans()함수를 부르기만 하면 됩니다.
아래와 같이 간단한 데이터부터 시작해봅니다. 게임을 이용하는 사람들이 얼마나 돈을 쓰고(spent) 얼마나 시간을 투자(time)했는지에 대한 간단한 데이터입니다.
> member <- data.frame( spent = c(10,1,1,17,4,6,1,15,22,3,0,3,7,0,2),
time = c(15,2,10,7,5,7,1,10,18,3,1,3,7,10,2))
그리고 이 데이터를 3개의 군집으로 나눠본다면
> result <- kmeans(member, 3)
> result
K-means clustering with 3 clusters of sizes 6, 5, 4
Cluster means:
spent time
1 1.666667 2.0
2 3.600000 7.8
3 16.000000 12.5
Clustering vector:
[1] 3 1 2 3 2 2 1 3 3 1 1 1 2 2 1
Within cluster sum of squares by cluster:
[1] 11.33333 56.00000 147.00000
(between_SS / total_SS = 79.2 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault"
4,6,5씩 되는 클러스터가 생상되어있는것을 확인할 수 있습니다.
클러스터링 그래프 표현
fpc라는 라이브러리의 힘을 좀 빌리겠습니다. 언제나처럼 install.packages("fpc") 및 library(fpc) 로 사용을 준비할수 있습니다.
library(fpc)
plotcluster(member, result$cluster, color=TRUE, shade=TRUE)
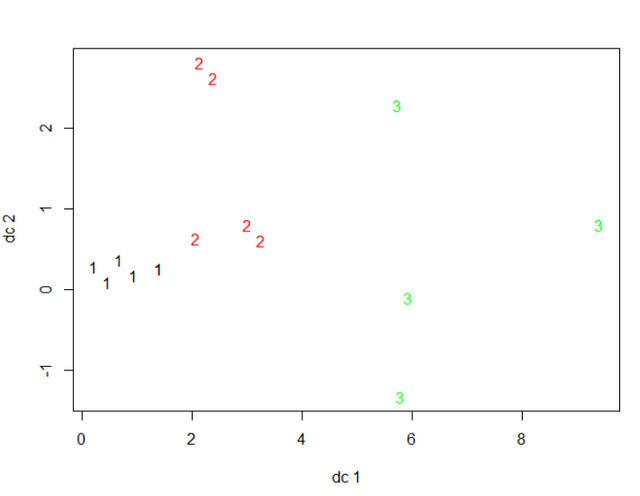
뭔가 허전해도, 거리에 맞게 잘 군집이 나뉜것을 확인할수 있습니다.
클러스터링 결과 살펴보기
kmeans과정이 끝난 결과값에는 다음과 같이 여러 분석결과가 들어있습니다.
위의 값은 아래와 같이 쉽게 접근이 가능합니다.
> result$withinss
[1] 11.33333 56.00000 147.00000
살펴볼수 있는 결과값은 아래와 같습니다.
- cluster : 어느 클러스터에 속해있는지
- centers : 각 클러스터의 센터가 어떻게 되는지
- totss : 총 sum of square
- withinss : 응집도. 같은 클러스터 안에 얼마나 데이터가 뭉쳐져있는지. 작아야 좋습니다!
- tot.withinss : withinss 모두 더한 값입니다.
- betweenss : 분리도. 다른 클러스터간 얼마나 떨어져 있는지. 커야 구분이 확실하단 거겠죠?
- size : 각 클러스터에 속한 데이터 갯수
- iter : 얼마나 반복을 했는지
분리도와 응집도를 살펴보면서, 여러 kmeans에 대한 결과값을 비교하면 되겠습니다.
몇개 데이터 인사이트 발견하기
바로 plot을 그리는것은 사실 데이터를 시각화하는 것 빼고는 별 의미가 없으니, 그룹별로 묶어서 몇가지 기본적인 계산을 해볼수도 있습니다.
> member$cluster <- result$cluster
> aggregate(data = member, spent ~ cluster, mean)
cluster spent
1 1 1.666667
2 2 3.600000
3 3 16.000000
> aggregate(data = member, spent ~ cluster, max)
cluster spent
1 1 3
2 2 7
3 3 22
혹시 클러스터를 몇개로 나눠야 할지 기준이 서지 않는다면?
그냥, 클러스터가 몇개 있으면 좋겠다고까지 추천을 하면 어떨까요? 클러스터를 하나 둘씩 만들어보면서 실제로 추천하는 라이브러리 또한 존재합니다. iris 데이터로 한번 추천 클러스터 수를 찾아봅니다.
> library(NbClust)
> nc <- NbClust(iris[,1:4], min.nc=2, max.nc=6, method="kmeans")
* Among all indices:
* 10 proposed 2 as the best number of clusters
* 8 proposed 3 as the best number of clusters
* 3 proposed 4 as the best number of clusters
* 1 proposed 5 as the best number of clusters
* 2 proposed 6 as the best number of clusters
***** Conclusion *****
* According to the majority rule, the best number of clusters is 2
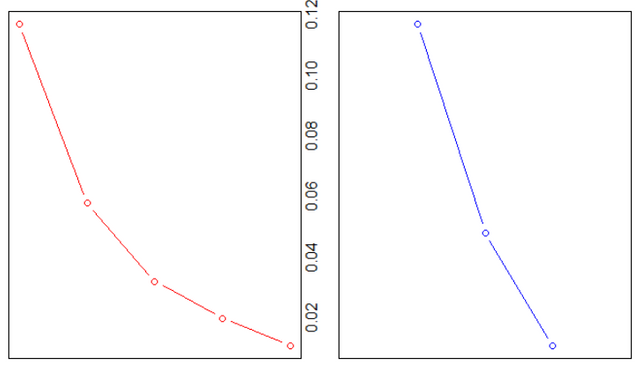
데이터를 이용한 결과 두개의 군집이 추천됩니다. 보통은 응집도와 분리도에 따라 여러가지 클러스터를 돌려보고 사용자에게 추천하는 과정이 됩니다.
추가적으로 K-means이용시 상기해야 하는점
K-means가 잘 작동을 하지 않는경우
- k가 틀린경우 - 실제로는 뚜렷한 3개의 군집인데 k를 5개로 설정해놓는경우 어쨌든 컴퓨터는 5개로 나눠야하기 때문에 현실을 잘 설명하지 못할수가 있습니다.
- 지역 최소값(Local Optimum) - 사실 전체적인 그림으로 보면 데이터가 몰려있는 곳이 다른곳인데 군데군데 더이상 변하지 않는 점들로 고착되어 버릴 경우가 있습니다.
- 이상값(Outlier)의 영향을 받는 경우 - 너무나도 중심에서 떨어져 있으면 평균을 계산하는 과정에서 중심점이 다른곳으로 튕겨져 나갈 경우가 있습니다.
- 원래 데이터들이 중앙에 원형으로 잘 모여져 있지 않는 경우 - DBSCAN, Mean-Shift등의 방법을 이용합니다. 이러한 방법들은 점들의 중간값으로부터 단순 계산하는게 아니라, 어떤군집은 길쭉하게, 어떤군집은 짜리몽땅하게 모아야 하는경우 유용할 수 있습니다.
- 여러번 kmeans를 돌린결과중 제일 그럴듯한 결과를 뽑고싶은 경우 - ykmeans패키지 이용할 수 있습니다.
- k-means는 NA값이 있을경우, 제대로 분류하지 못하기 때문에 미리미리 전처리를 해놓아야 합니다.
더 알고싶으신 분들은.. 이런것도 있습니다.
- K-medoid Clustering, K-median Clustering : 중간값등으로 클러스터링하는 다른 방법.
- 주성분분석(Principal Component Analysis) : 변수들을 제일 설명력이 높은 것으로 재편성. PCA는 나중에 다른 챕터에서 다시 설명됩니다.
- EM (Expectation Maximization) : 클러스터의 소속 여부를 해당 클러스터에서 데이터가 나타날 확률값으로 판단
- DBSCAN (Density-based spatial clustering of applications with noise) : 밀도가 높은 부분을 클러스터링함. 둥근 곳이 아니고 길쭉해도 연결하는 식으로 클러스터링 가능
- Mean-Shift : 무게중심을 분포로 옮기는 방법, 영상 물체 추적에서 쓰임
- 가우시안 혼합모델(Gaussian Mixture)
- MDS(Multi Dimensional Scaling)
- Conjoint 분석
K means Clustering 관련 내용 재밌는 글이네요.좋은글이네요.
i need a translator with you XD
big UP