문과 아재도 쉽게하는 R 데이터 분석 – (4) 결정나무(Decision Tree)
결정나무(Decision Tree)
Decision Tree라고 부르는 결정나무도 실질적으로 이해하기 너무 쉬운 방법의 기법입니다. 일반적인 소개팅도 머릿속에는 이런 과정이 흘러가고 있습니다.
머신러닝을 통해 이러한 결정나무를 자동생성할수 있습니다. 생성 알고리즘은 복잡한 편이나, 워낙 결과물이 직관적이라 모델을 가지고 결정을 함에 있어 이에대한 설명을 잘 해야 할 경우 유용하게 쓰일수 있습니다.
직장상사가, 얌마 왜 너 이렇게 결정했어? 라고 물어보면, 아 네, 디시전트리에 따라 이 수치는 50이상이며, 이중에서도 저 수치는 10이하라 이렇게 결정했습니다! 라고 말할수도 있고, 이는 사실 우리가 보통 삶을 살아가면서 결정하는 방법과 가장 비슷한 편입니다.
예를 들면, 실제적으로 채무 불이행에 대한 것들을 예측하는데 유용하게 쓰일수 있는데, 고객에게 왜 추가적인 대출이 불가능한지 쉽게 설명이 가능하기 때문입니다.
데이터준비
함부르크 대학 한스 호프만의 신용대출을 기준으로 진행합니다. 데이터는 아래의 주소에서 받으면 됩니다.
https://github.com/stedy/Machine-Learning-with-R-datasets/blob/master/credit.csv
credit <- read.csv("credit.csv")
str(credit)
'data.frame': 1000 obs. of 17 variables:
$ checking_balance : Factor w/ 4 levels "< 0 DM","> 200 DM",..: 1 3 4 1 1 4 4 3 4 3 ...
$ months_loan_duration: int 6 48 12 42 24 36 24 36 12 30 ...
$ credit_history : Factor w/ 5 levels "critical","good",..: 1 2 1 2 4 2 2 2 2 1 ...
$ purpose : Factor w/ 6 levels "business","car",..: 5 5 4 5 2 4 5 2 5 2 ...
$ amount : int 1169 5951 2096 7882 4870 9055 2835 6948 3059 5234 ...
$ savings_balance : Factor w/ 5 levels "< 100 DM","> 1000 DM",..: 5 1 1 1 1 5 4 1 2 1 ...
$ employment_duration : Factor w/ 5 levels "< 1 year","> 7 years",..: 2 3 4 4 3 3 2 3 4 5 ...
$ percent_of_income : int 4 2 2 2 3 2 3 2 2 4 ...
$ years_at_residence : int 4 2 3 4 4 4 4 2 4 2 ...
$ age : int 67 22 49 45 53 35 53 35 61 28 ...
$ other_credit : Factor w/ 3 levels "bank","none",..: 2 2 2 2 2 2 2 2 2 2 ...
$ housing : Factor w/ 3 levels "other","own",..: 2 2 2 1 1 1 2 3 2 2 ...
$ existing_loans_count: int 2 1 1 1 2 1 1 1 1 2 ...
$ job : Factor w/ 4 levels "management","skilled",..: 2 2 4 2 2 4 2 1 4 1 ...
$ dependents : int 1 1 2 2 2 2 1 1 1 1 ...
$ phone : Factor w/ 2 levels "no","yes": 2 1 1 1 1 2 1 2 1 1 ...
$ default : Factor w/ 2 levels "no","yes": 1 2 1 1 2 1 1 1 1 2 ...
여기서 하나 습관적으로 해두면 좋을것은 데이터를 섞는 것입니다. 보통 데이터는 시간순서로 저장되어있기 때문에 아래에 쌓인 데이터의 내용과 위에쌓인 데이터의 내용이 어떤 경향성을 띌수가 있습니다.
creditr <- credit[order(runif(nrow(credit))),]
nrow로 행의 갯수를 세고, 이를통해 랜덤한 숫자를 추출하고, 이를 바탕으로 랭킹을 매겨본뒤, 다시한번 무작위로 뒤섞인 데이터를 저장하는 과정입니다. 이렇게 랜덤하게 섞는 방법을 이용하면, 샘플링할때도 단순하게 위에서 몇개는 훈련용, 그 나머지는 테스트용으로 간단하게 나눠볼수 있습니다.
train <- creditr[1:900,]
test <- creditr[901:1000,]
혹은 더 간단하게, sample()메서드를 이용하는 방법도 있습니다.
index <- sample(1:nrow(creditr), nrow(creditr) * 0.7, replace = F)
train <- creditr[index,]
train <- creditr[-index,]
편한 방법으로 이용하도록 합니다.
C5.0으로 모델 만들기
결정나무를 지원하는 라이브러리는 이것저것 많습니다.
rpart, c5.0 ..등등. 그리고 내부 구현체도 각각의 다른 논문에 기초해 있습니다. 사실 구현체도 없는 결정트리 알고리즘들도 꽤나 많이 존재합니다.
실제 널리 쓰이는 알고리즘 중 비교적 최근에 나온게 c5.0이며, rpart의 경우는 CART라 부르는 알고리즘의 구현체인데 여기저기 제일 많이 구현되어있습니다.
우리는 C5.0과 rpart를 이용해봅니다.
install.packages("C50")
library(C50)
#rpart를 쓴다면 아래와 같이.
install.packages("rpart")
library(rpart)
그리고 바로 훈련을 시키되, 특정한 열을 제외하여야 합니다. 변수들을 하나하나 언급하는 경우에는 상관이 없으나, 이러한 귀찮은 과정을 하지 않고 바로 모델 훈련에 이용하려면, default는 빼주고 나머지것으로 예측해보라고 던져야 합니다.
함수는 아래와 같이 만들면 됩니다.
C5.0(훈련데이터, 라벨)
credit_model <- C5.0(within(train, rm(default)), train$default)
within(train, rm(default))
은 train default라는 열을 없애라는 뜻이고, 좀더 쉽게 하려면 credit_train[-열넘버] 로 써주면 됩니다.
반면, rpart라이브러리의 사용법은 다음과 같습니다.
credit_model2 <- rpart(default ~. , data=train)
어댑티브 부스팅은, 여러 결정트리를 만들어 각각에 투표하는 방식인데 trials 옵션에 숫자만 넣으면 신기하게도 여러번 결정나무를 만드는 행위를 반복하면서 계속해서 성공률이 높아지는 것을 볼수있습니다.
credit_model <- C5.0(within(train, rm(default)), train$default, trials=10)
실제 훈련된 모델을 출력해보면, 아래와 같습니다. 정확도는 77%입니다.
table(test$default,predict(credit_model,newdata=test))
no yes
no 62 6
yes 17 15
rpart의 예측률은 어떤지 한번 살펴볼까요.
간략한 알고리즘 훈련 개념
정보 엔트로피라는 것을 이용합니다. 엔트로피는 혼돈을 나타내는 단어입니다.
장바구니 안에 복숭아와 사과가 반씩 담겨있다고 가정해보세요. 그렇다면 그 장바구니는 복숭아 바구니일까요? 사과 바구니일까요? 뭐라 말할수도 없기 때문에 엔트로피는 100%인 1이 됩니다.
만약 사과만 담겨있는 바구니면 그것은 사과바구니라고 확신할수 있습니다. 그렇다면 우리의 혼돈상태는 수치가 어떻게 될까요? 0입니다. 헷갈리는게 하나도 없으니까요.
결정나무는 하나하나 데이터를 구분해 나가는 과정을 이 혼돈을 없애는 과정으로 실행합니다.
party 패키지 이용하기.
C5.0은 강력하지만, 분류되는 값이 너무 적다면 적당한 그래프를 그려주지 못할때가 있습니다. 다른 패키지의 이용도 가능합니다.
library(party)
mm <- ctree(default ~ . , data = train)
plot(mm)
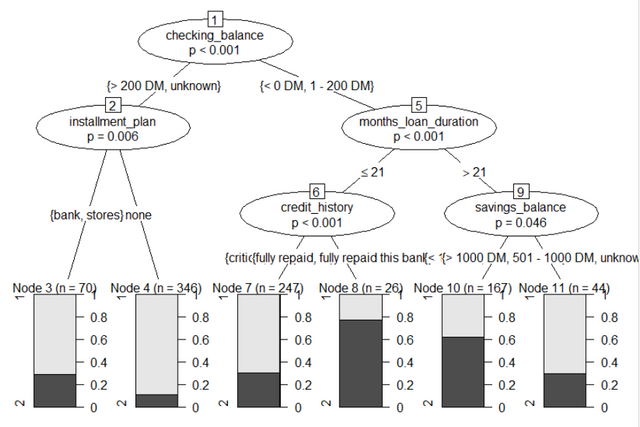
실제로 정확하게 예측할수 있을을지 살펴봅니다.
table(credit_test$default,predict(mm,newdata=credit_test))
no yes
no 62 6
yes 13 19
실제 정확도는 81%입니다. 위에서 진행했던 C5.0 패키지와 별 다른 결과는 없습니다.
결정나무는 너무 민감하다.
결정나무 하나를 이용하는것은 사실 그 민감도가 큽니다. 약간의 변경이 모델의 변화에 큰 영향을 미칠수도 있습니다.
결정나무는 한번에 한가지 판단밖에 하지 못한다.
결정나무는 기본적으로 YES, NO에 대한 분기입니다. 여러가지 조건이 복잡하게 얽혀 어떤 결과가 일어난다가 아닌, 한번에 하나씩 YES, NO에 대한 분기만 하며, 이를 축 평행 구별이라고 합니다.
사실 분기가 여러개로 나눠지는 결정트리도 존재하기는 하지만, 사실 오히려 단순할 때가 복잡할때보다 나은경우가 있습니다.