문과 아재도 쉽게하는 R 데이터 분석 – (10) Support Vector Machine
서포트 벡터 머신 (Support Vector Machine)
서포트 벡터 머신은 상당히 유용한 방법이면서도 이름으로는 쉽게 그 역할을 가늠할수 없는 방법이기도 합니다.
사실, 서포트 벡터를 이름만으로 느끼기는 힘드니, 그래프를 하나 봅시다
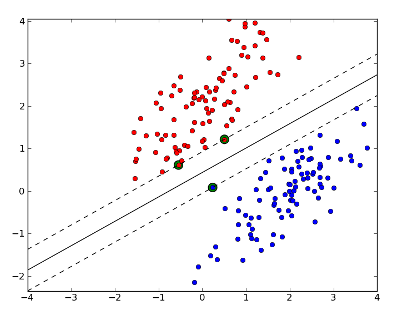
여기서, 서포트 벡터는 최대 간격에 제일 가까워서 두꺼운 경계선을 만드는데 도움을 주는 녀석들을 말합니다. 어때요 참 쉽죠? 이 서포트 벡터를 잘 따라서 그리면, 제일 구분선을 예쁘게 그을 수 있습니다.
사실 우리가 무언가를 구별하는 문제에 있어서 사실은 어디엔가 선을 그어야 하는 문제가 있습니다. 예를들어, 2차원 산점도에서 어떤곳에 직선을 그어야 될는지 판단해서 한쪽은 복숭아로, 한쪽은 사과로 판단해야 하는 문제가 있는데, 서포트 벡터 머신은 구별하는 선을 잘 그릴수 있게 도와주는 역할을 합니다. 제일 그럴듯한 구분선을 찾아주기 때문입니다.
차원을 늘려야 할때도 있다!
PCA의 경우는 차원을 필요한만큼 줄여버렸지만, SVM은 내부적으로 필요한경우 직선으로 안될것 같으면 아예 차원을 높여버립니다.
2차원에서의 구분선은 직선(1차원)이고, 3차원에서의 구분은 면(2차원)이라고 한다면, 4차원에서의 구분선은.. 5차원에서의 구분선은.. 머리가 돌아가지 않으니 초평면(Hyperplane)이라는 그럴듯한 말을 붙입니다.
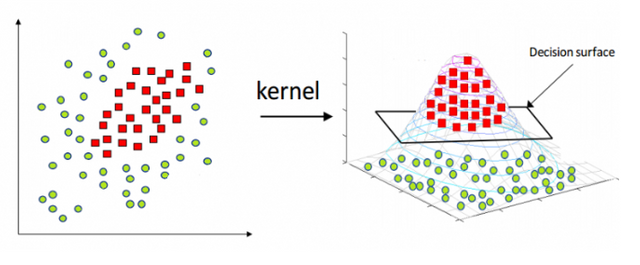
출처 : https://www.hackerearth.com/blog/machine-learning/simple-tutorial-svm-parameter-tuning-python-r/
실생활의 예에서는, 미세먼지의 풍향을 보고 미세먼지량을 맞춰야 되는 모델을 한번 생각해보세요. 풍향은 360도로 바뀌기 때문에 직선으로 나타내기가 힘든 부분이 있습니다. 이러한 경우는 생각보다 많기 때문에 차원의 변환을 통해 뭔가를 더 성취할수 있는겁니다.
간단하게 이용해보기
사용할수 있는 라이브러리는 kernlab 패키지, e1071패키지 등이 있습니다. 여기서는 e1071패키지를 이용해봅니다.
여기서는 대표적인 iris를 가지고 웜업을 해봅니다.
library(e1071)
svm_model <- svm(Species ~ ., data=iris)
svm_model
Call:
svm(formula = Species ~ ., data = iris)
Parameters:
SVM-Type: C-classification
SVM-Kernel: radial
cost: 1
gamma: 0.25
Number of Support Vectors: 51
예측하기
svm을 이용하기 위해서는 여러가지 하이퍼파라미터 (사용자가 튜닝을 해야하는값)을 조정해 최대의 효과를 측정해보아야 하는데, 위의 설명에서 Parameter가 이를 뜻합니다. 서포트 벡터의 수도 나와있습니다.
간단하게 훈련했고, 이를 통해 결과를 예측해 보겠습니다.
s <- subset(iris, select=-Species)
table(predict(svm_model,s), iris$Species)
setosa versicolor virginica
setosa 50 0 0
versicolor 0 48 2
virginica 0 2 48
물론 테스트데이터셋을 따로 만들지는 않았지만 상당히 예측이 잘되고있다는 것을 확인할수 있습니다.
튜닝하기
SVM은 일반적인 일반선형회귀 모델이나 결정나무보다 더 나은 성능을 보이는것 같이 보이기도 합니다.(보통은 맞습니다) 게다가 SVM은 여기서 끝이 아니고, 파라미터가 많은 이유로, 튜닝할수 있는 여지가 많이 남아있기는 합니다. tune()함수를 이용하면 됩니다.
svm_tune <- tune(svm, train.x=subset(iris, select=-Species), train.y=iris$Species, kernel="radial", ranges=list(cost=10^(-1:2), gamma=c(.5,1,2)))
svm_tune
Parameter tuning of ‘svm’:
- sampling method: 10-fold cross validation
- best parameters:
cost gamma
1 0.5
- best performance: 0.04666667
커널과 cost, gamma값을 여러가지로 주어서 구별을 해낼수가 있습니다. 이 tune을 가지고 찾아낸 파라미터를 옵션으로 주고 다시한번 예측해볼수도 있습니다.
svm_model_after_tune <- svm(Species ~ ., data=iris, kernel="radial", cost=1, gamma=0.5)
pred <- predict(svm_model_after_tune,subset(iris, select=-Species))
table(pred,iris$Species)
pred setosa versicolor virginica
setosa 50 0 0
versicolor 0 48 2
virginica 0 2 48
사실은 결과가 거의 완벽하게 나와있었기때문에 별 의미는 없으나, 조금 더 큰 데이터셋을 가지고 커널과 여러 파라미터를 바꾸면서 시도하면 모델의 향상이 이뤄집니다. SVM은 단순히 옛날 방법이 아닌, 최근에서도 계속해서 딥러닝 계층에서 종종 보이는 방법입니다.
SVM은 구분 문제뿐만 아니라 수치를 예측하는 방법으로도 쓰여서 그 쓰임새가 굉장히 많은 편입니다. 성능도 보장하지만, 내부적으로 왜 이렇게 되었는지 설명하기 힘든 블랙박스 모델이라, 설명력이 굉장히 중요한 실무에서는 용도가 맞는지 다시한번 확인하면 될 듯 합니다.
계속 올려 주셔서 감사합니다. 시간 내서 한꺼번에 보려고 저장해 놓는 통에 보팅을 제 때 못 드렸네요.
아녜요 별거아닌내용이라 ㅎㅎ 댓글달아주셔서 감사합니다.
근데 9편이 없는 것 같아요
9편은 시계열인데 좀더 검토를 거친후에 내놓으려구요.. 적은내용에 인기가 없더라도 잘못된 내용이면 안되니까 ㅋㅋㅋ