간단한 트위터 텍스트 분석을 하고싶으면?
가상화폐 트위터 텍스트 분석 및 시각화
이번에는 텍스트분석을 들고왔습니다.
텍스트는 사실 워드클라우드 만드는 과정은 정말이지 너무 쉽지만, 사실은 전처리가 보통 문제가 되는 경우가 많습니다. 수많은 쉼표와 일정하지않는 비정규화된 데이터들. 짜증이 아주 날때가 있을수밖에 없습니다.
이번에는 트위터를 가지고 뭔가를 해보겠습니다.
특히 트위터는 사람들이 거론하는 수만가지 (쓰레기? or 보석?) 생각들이 교차하는 공간입니다.
트위터 API 허가
다음과 같이 twitter api 허가를 받습니다. 미리 회원가입을 해놓아야 합니다.
setup_twitter_oauth(api_key,api_secret)
이번에 해킹을 왕창당한 NEM을 찾아봅니다.
> tweets = searchTwitter(enc2utf8("NEM"), n=500, since="2018-01-26", lang="en")
[[495]]
[1] "decentristan: RT @DecentralizedM1: I'm confident that this hack @coincheckjp will head up the importance of Decentralized Exchanges. NEVER store your coi…"
[[496]]
[1] "Rapulaaa: RT @OwaFlopo: Ele gore o targetile relationshit ya ga mang nem? https://t.co/GcQyuiwfAb"
[[497]]
[1] "tmdfund: RT @iamjosephyoung: $600 million in XEM (NEM) was withdrawn from Japanese cryptocurrency exchange Coincheck. Not confirmed whether it was a…"
[[498]]
[1] "hercules_stry: $723 MILLION HACK ON JAPANESE EXCHANGE COINCHECK!!($123 mil ripple and $600 mil NEM) Can anyone confirm this as thi… https://t.co/0lRbvHoZro"
[[499]]
[1] "L_foxx: @T8trTots What’s old school to you?\xed��\xed�\u0094 old school to me is bobby Womack and nem soul singers!"
[[500]]
[1] "Shohei192: RT @Inside_NEM: NEMbers! Share this NEM 101 video with your friends! This is a great way to explain what #NEM is to anyone... https://t.co/…"
텍스트를 트위터에서 왁자지껄하게 떠드는 모습을 확인할수 있습니다. 다만 데이터타입이 리스트라, 벡터로 꺼내오는게 좋습니다. simplified apply() 함수를 통해, 이를 간단하게 이용해봅니다.
corpus 추출
이를, sapply()함수를 통해, 각각의 텍스트들을 리스트로부터 꺼내올수 있습니다. 그리고 나서 corpus를 추출합니다.
texts = sapply(tweets, function(x) x$getText())
corpus = Corpus(VectorSource(texts))
corpus = tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte"))
corpus는 위키피디아에 따르면, 자연언어 연구를 위해 특정 언어의 표본을 추출한 집합입니다. 말뭉치라고 하는데, 언어 규칙 발생의 검사와 규칙의 정당성 입증에 사용된다고 언급되어있습니다.
tm_map은, 몇가지 인코딩처리때문에 들어간 추가 로직입니다.
Term Document Matrix 추출
실제로 문서에 어떤 단어가 출현하는지 나타내는 표를 term document matrix라고 합니다.
tdm = TermDocumentMatrix(corpus,
control = list(removePunctuation = TRUE,
stopwords = c("https" , stopwords("english")),
removeNumbers = TRUE, tolower = TRUE))
> tdm
<<TermDocumentMatrix (terms: 990, documents: 500)>>
Non-/sparse entries: 5707/489293
Sparsity : 99%
Maximal term length: 20
Weighting : term frequency (tf)
사실 몇가지 문서마다 공통적으로 들어가는 쓸데없는것들이 있습니다. 불용어인 is, the이런건 있을 필요가 없습니다. 그리고 숫자또한 들어갈필요가 없을수 있습니다. 그리고 대문자 소문자를 굳이 나눌 필요도 없겠네요. 한번 돌리고 나면 위와 같은 결과를 볼수 있습니다.
이를 보기쉽게 매트릭스 (행렬) 형태로 나타내면 됩니다.
m = as.matrix(tdm)
> m
Terms 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459
billion 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
coincheck 0 0 0 1 1 2 0 1 1 1 1 0 2 1 0 0 1 0
Docs
Terms 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477
billion 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0
coincheck 0 1 1 1 1 0 0 0 0 1 0 1 1 1 0 1 1 1
Docs
Terms 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495
billion 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
coincheck 0 1 2 0 1 1 1 1 1 1 1 1 2 0 1 1 1 0
Docs
Terms 496 497 498 499 500
billion 0 0 0 0 0
coincheck 0 1 0 1 0
[ reached getOption("max.print") -- omitted 988 rows ]
빈도수대로 정렬
코인체크 이름이 많이 언급이 될수밖에 없겠죠. 조건을 1.25부터 줬으니 말입니다.
내림차순으로 정렬합니다.
word_freqs = sort(rowSums(m), decreasing=TRUE)
> word_freqs
nem coincheck
526 339
million stolen
190 162
japanese hacked
139 135
inside worth
93 86
exchange track
86 80
related xem
78 77
working accounts
77 76
역시나 예상대로입니다. sort() 함수를 통하면 쉽게 정렬이 가능합니다. 역시 상위를 차지하는건, 모두 해킹얘기로 점철되어있네요.
워드크라우드 생성
이제 워드 클라우드를 생성해봅니다. 데이터 프레임으로 전환하면 쉽게 사용가능합니다.
dm = data.frame(word=names(word_freqs), freq=word_freqs)
wordcloud(words = dm$word, freq = dm$freq, min.freq = 5,
max.words=200, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))
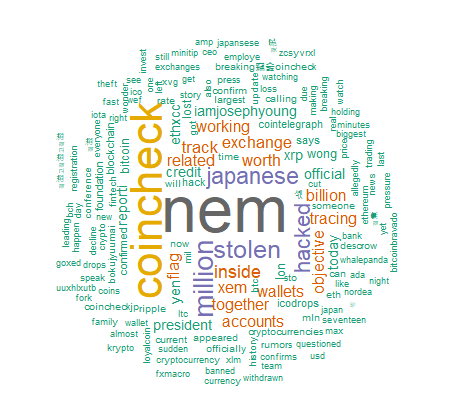
어때요? 참 쉽죠? 역시나 코인체크와 일본이라는 단어가 많이 등장합니다. 어떡하나요 이거원 해킹에 너무 취약해서. 사견이지만, 해킹에 안전한 암호화폐가 오히려 그 접점에서는 별로 안전하지 않기 때문에 법정통화까지 가기에는 한참인것 같네요.
사실 이러한 과정들을 function으로 만들어놓고 재활용하면 어떤 코인이든 한줄로 끝내버릴수있습니다. 아래는 전체 코드입니다.
function으로 다시 정리 및 마무으리
install.packages(c("twitteR","httpuv", "tm", "wordcloud"))
install.packages("tm")
install.packages("wordcloud")
install.packages("httpuv")
install.packages("twitteR")
library(tm)
library(wordcloud)
library(httpuv)
library(twitteR)
setup_twitter_oauth(api_key,api_secret)
analyze <- function(lang, coin, date) {
tweets = searchTwitter(enc2utf8(coin), n=500, since=date, lang=lang)
texts = sapply(tweets, function(x) x$getText())
corpus = Corpus(VectorSource(texts))
corpus = tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte"))
tdm = TermDocumentMatrix(corpus,
control = list(removePunctuation = TRUE,
stopwords = c("https",coin , stopwords("english")),
removeNumbers = TRUE, tolower = TRUE))
m = as.matrix(tdm)
word_freqs = sort(rowSums(m), decreasing=TRUE)
dm = data.frame(word=names(word_freqs), freq=word_freqs)
print(word_freqs)
print(dm)
wordcloud(words = dm$word, freq = dm$freq, min.freq = 5,
max.words=200, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))
return(dm)
}
이렇게 열심히 영-차 영-차 적어놓으면 너무나도 쉽게 펑션콜만 하면 끝입니다. 우지한이 코파다가 만든 코인은 요즘 뭐가 핫한지 한번 확인해볼까요?
비트코인 캐시
dm = analyze("en","BCH", "2018-01-25")
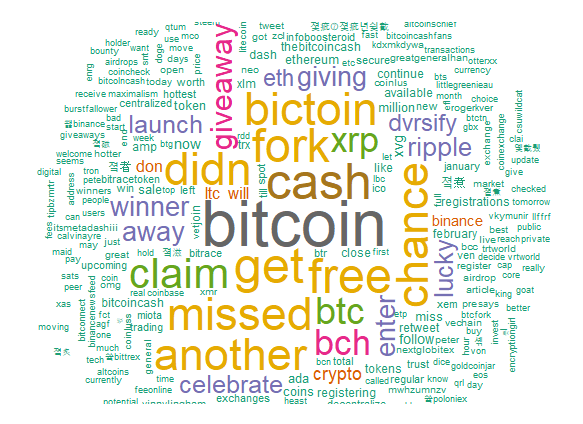
BCH는 비트코인의 그늘에서 절대 벗어날수 없나봅니다. 포크코인이니까요. 뭘 또 공짜로 뿌리고있는걸까요? 에어드랍을 하고있는걸까요? 잘 모르겠습니다.
이오스
dm = analyze("en","EOS", "2018-01-25")

우리의 B+ 코인답게 undervalued, hodl, pick 이라는 단어도 보이네요.
직접 한번 해보시면 더 재밌습니다. 데이터사이언티스트가 별게 있나요? 셀프 데이타 사이언티스트가 되어 열심히 탐색하다보면 회사에도 논문에도 어디든 쓸데가 많을거라는거~
남은 주말 깔깔깔 재밌는 주말 보내시길~
hola! I like your post! Thanks for it! I went to jail because of cryptos... lets make steemit together to a better place with our content! I would like to read a bit more about you and maybe do you have some more pictures? I also just wrote a introduce yourself. Maybe you upvote me and follow me swell as I do? https://busy.org/introduceyourself/@mykarma/1-jail-review-bitcoins-3-years-ago
제가 사실 요즘 R 공부중인데 @gillime 님 글 보고 많은걸 배웁니다. 정말 감사합니다^^ 저도 따라해보도록 할게요^^
정리 잘하셨네요! 리스팀 합니다!
우어 뭔가 외계어가 많지만... 저 성과물은 정말 멋있네요...꼭 한번 배워보고 싶은...
정말 쉬운지...궁금할 정도로..
코딩 공부를 정말 하게되면 gillime님 글 꼭 다시 읽어볼게요~~ 강력한
동기부여!!! 감사드립니다 ^^
헉 이렇게 좋은 포스팅을...
잘보고 갑니다 ^^