[스팀잇 데이터분석] 2018년 1월 토픽(TITLE)을 기준으로 Word Cloud(워드 클라우드) 만들기
안녕하세요. ferozah 입니다.

오늘은 뉴질랜드 소식 대신, 제가 그동안 공부한 텍스트 마이닝에 대해 이야기 해 보도록 하겠습니다.
데이터분석과 텍스트 마이닝을 공부하면서, 데이터분석에 최적화된 프로그래밍 언어 'R'을 알게 되었습니다.
R 프로그래밍 언어 소개
R 프로그래밍 언어(줄여서 R)는 통계 계산과 그래픽을 위한 프로그래밍 언어이자 소프트웨어 환경이다. 뉴질랜드 오클랜드 대학의
로버트 젠틀맨(Robert Gentleman)과 로스 이하카(Ross Ihaka)에 의해 시작되어 현재는 R 코어 팀이
개발하고 있다. R은 GPL 하에 배포되는 S 프로그래밍 언어의 구현으로 GNU S라고도 한다. R은 통계 소프트웨어 개발과
자료 분석에 널리 사용되고 있으며, 패키지 개발이 용이하여 통계학자들 사이에서 통계 소프트웨어 개발에 많이 쓰이고 있다. 출처 : <위키피디아>
for ( x in 1:100){
url_base <- 'https://steemit.com/created/kr'
steem <- read_html(url_base)
steem
#steem_title <- html_nodes(steem, 'div') %>% html_nodes('h2')
steem_title <- html_nodes(steem, 'div') %>% html_nodes('h2') %>% html_nodes('a')
steem_title_text <- html_text(steem_title)
steem_title_link <- html_nodes(steem, 'div') %>% html_nodes('h2') %>% html_nodes('a') %>% html_attr('href')
steemit <- cbind.data.frame(Number=c(1:20),TITLE=steem_title_text , LINK=steem_title_link)
View(steemit)
##class(steem_title_text)
setwd("E:/Study/R")
##final_data = data.frame(steemit,stringsAsFactors = F)
##write.csv(final_data, 'steem_test.csv')
write.table(steemit, file = "steem_test_total.csv", sep = ",", row.names = F, append = TRUE)
Sys.sleep(1800)
}
https://steemit.com/created/kr URL을 1800초(30분)에 한 번씩 접속해서 새로운 글 들을 수집합니다. 수집한 글 들은 steem_test_total.csv 파일에 저장합니다.
#2. 기간
2018년 1월 7일 부터 28일까지 샘플링된 steemit, kr 태그를 기준으로 합니다. 또한 포스팅된 글의 '제목(Title)' 데이터를 수집했습니다.
#3. 데이터 분석 및 전처리
총 샘플링된 데이터는 8910개 입니다.
먼저, 해당 csv 파일을 txt 파일로 전환한 후 R에서 데이터를 읽어 옵니다.
이때 KoNLP 라는 도구를 사용하게 되는데, 한글의 명사를 자동으로 추출해주는 기능을 가지고 있습니다. 지금과 같이 스팀잇에 사용된 한글을 분석하려고 할 때 유용 합니다. 다만 단어를 100% 완벽하게 추출하지는 못하기 때문에 추출된 결과를 보고 일부 수동으로 불필요한 단어를 제거하거나, 필요한 단어를 추가해야 합니다.
f <- file("steemkr_wordcloud.txt", blocking= F)
txtLines <- readLines(f)
nouns <- sapply(txtLines,extractNoun, USE.NAMES=F)
txt 파일을 읽고, extractNoun 이라는 기능을 사용해서 명사만 추출 합니다.
data_unlist <- Filter(function(x){nchar(x)>=2}, data_unlist)
data_unlist1 = gsub('”', "", data_unlist)
data_unlist1 = gsub('“', "", data_unlist1)
data_unlist1 <- gsub("#", "", data_unlist1)
data_unlist1 <- gsub("[", "", data_unlist1)
data_unlist1 <- gsub("]", "", data_unlist1)
data_unlist1 <- gsub("$", "", data_unlist1)
data_unlist1 <- gsub("@", "", data_unlist1)
data_unlist1 <- gsub('[~!@#$%&*()_+=?<>]','',data_unlist1)
data_unlist1 <- gsub("\\[","",data_unlist1)
data_unlist1 <- gsub('[ㄱ-ㅎ]','',data_unlist1)
data_unlist1 <- gsub("가상\\S*", "가상화폐", data_unlist1)
data_unlist1 <- gsub("\\S*화폐", "가상화폐", data_unlist1)
data_unlist1 <- gsub("\\S*체인", "블록체인", data_unlist1)
data_unlist1 <- gsub("블록\\S*", "블록체인", data_unlist1)
data_unlist1 <- gsub("Bitco", "Bitcoin", data_unlist1)
data_unlist1 <- gsub("Bitco", "Bitcoin", data_unlist1)
data_unlist1 <- gsub("bitco", "Bitcoin", data_unlist1)
data_unlist1 <- gsub("BITCOIN*", "Bitcoin", data_unlist1)
data_unlist1 <- gsub("Bitco", "Bitcoin", data_unlist1)
data_unlist1 = gsub("of", "", data_unlist1)
data_unlist1 = gsub("01.", "", data_unlist1)
data_unlist1 = gsub("to", "", data_unlist1)
data_unlist1 = gsub("and", "", data_unlist1)
data_unlist1 = gsub("-01", "", data_unlist1)
data_unlist1 = gsub("10", "", data_unlist1)
data_unlist1 = gsub("is", "", data_unlist1)
data_unlist1 = gsub("for", "", data_unlist1)
data_unlist1 = gsub("my", "", data_unlist1)
data_unlist1 = gsub("on", "", data_unlist1)
data_unlist1 = gsub("12", "", data_unlist1)
data_unlist1 = gsub("with", "", data_unlist1)
data_unlist1 = gsub("#1", "", data_unlist1)
data_unlist1 = gsub("1.", "", data_unlist1)
data_unlist1 = gsub("2.", "", data_unlist1)
data_unlist1 = gsub("the", "", data_unlist1)
data_unlist1 = gsub("by", "", data_unlist1)
data_unlist1 = gsub("DAY", "", data_unlist1)
data_unlist1 = gsub("in", "", data_unlist1)
data_unlist1 = gsub("00", "", data_unlist1)
data_unlist1 = gsub("The", "", data_unlist1)
data_unlist1 = gsub("01", "", data_unlist1)
data_unlist1 = gsub("My", "", data_unlist1)
data_unlist1 = gsub("day", "", data_unlist1)
data_unlist1 = gsub("무엇", "", data_unlist1)
data_unlist1 = gsub("vs", "", data_unlist1)
data_unlist1 = gsub("하기", "", data_unlist1)
data_unlist1 = gsub("BW", "", data_unlist1)
코드가 쓸데없이 길어 보이는 부분 입니다. 앞서 말씀드린 것처럼, KoNLP가 추출한 명사 중 제가 봤을 때, 의미없는 단어는 제거하고, 블록체인, 가상화폐 처럼 원래 하나의 단어인데 분리된 단어들은 다시 연결해 줍니다.
이런 전반적인 행위를 전처리라고 부릅니다. 데이터 분석을 본격적으로 하기 전에 데이터를 다루는 사람이 자신의 입맛에 맞게 데이터의 모양을 예쁘게 만드는 작업입니다.
이렇게 데이터를 정제한 후, 가장 많이 사용된 명사 순서대로 정렬해보니 이렇게 나옵니다.
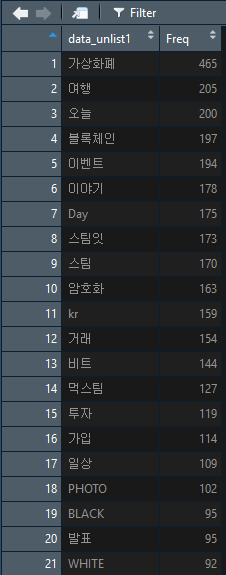
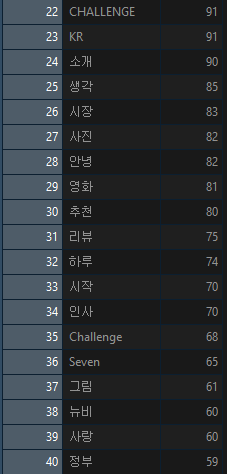
역시 예상대로, 가상화폐가 가장 많이 사용 되었고, 블록체인, Bitcoin, 스팀 등 암호화폐 관련 단어들이 상위권에 있습니다. 먹스팀과 이벤트와 같이 스팀잇에서 자주 볼 수 있는 단어들도 상위권에 있네요!
#4. 워드 클라우드
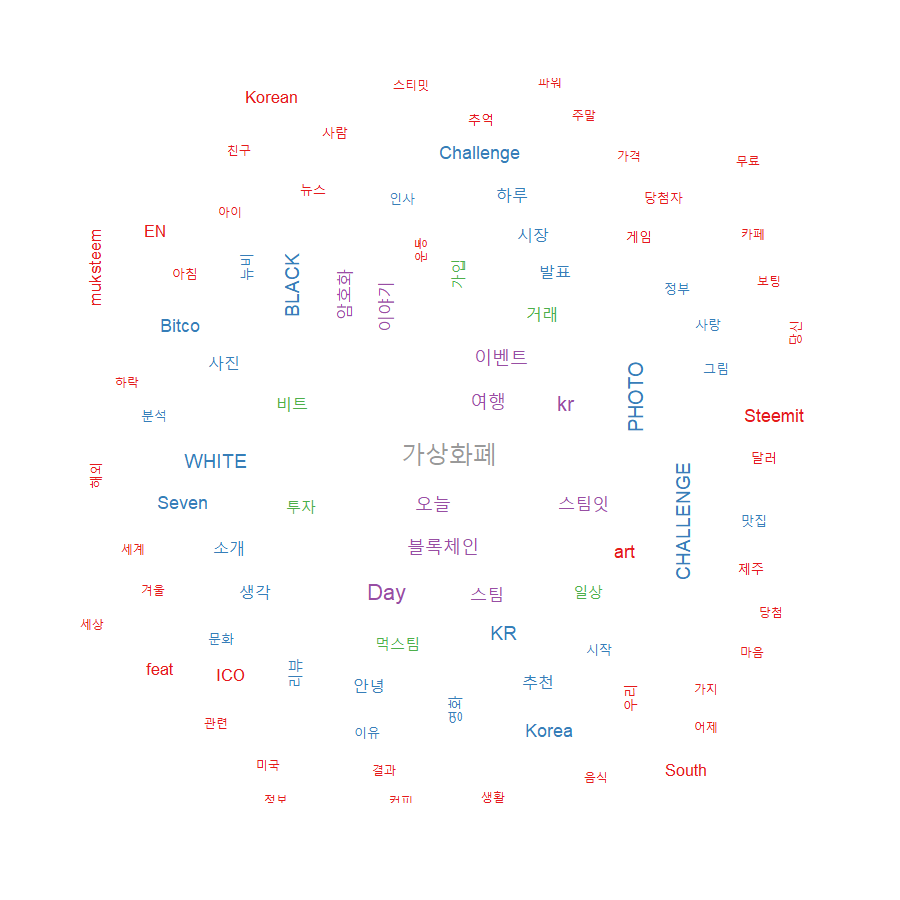
이제 해당 데이터를 기반으로 워드 클라우드를 그리도록 하겠습니다.
워드 클라우드는 지금 보신 데이터들을 다른 사람들에게 보여줄 때, 핵심 단어들이 한 눈에 보이도록 시각화하는 기법 입니다.
wordcloud(wordDf$word # 단어
, wordDf$freq.Freq # 빈도수
, min.freq = 35 # 최소 빈도 수
, colors = pal
, rot.per = 0.2
, random.order = F
, scale = c(2,1)
, family="맑은 고딕")
wordcloud 함수를 사용하여 워드 클라우드를 그려 보았습니다. 데이터에 있는 모든 단어들을 사용하면 워드 클라우드가 정상적으로 그려지지 않기 때문에, 최소 35번 이상의 빈도 수를 가진 단어들을 대상으로 워드 클라우드가 그려지도록 설정 했습니다.
스팀잇 1월 전체 데이터는 아니지만 대략적으로 토픽들의 트렌드를 확인할 수 있었습니다. 다음 달 부터는 네이버 클라우드 서버를 사용하여 24시간 돌려볼까 생각 중입니다.
감사합니다!
스스로 홍보하는 프로젝트에서 나왔습니다.
오늘도 좋은글 잘 읽었습니다.
오늘도 여러분들의 꾸준한 포스팅을 응원합니다.
늘 감사드립니다!
개발 글은 추천!
LDA (Latent Dirichlet Allocation) 사용하시면 토픽 별 키워드를 뽑을 수 있습니다. 훨씬 양질의 태그 클라우드를 만들 수 있고, 잘 응용하면 태그 그래프도 만들 수 있습니다!
오 그런게 있었군요! 공부해서 적용해 보겠습니다 알려주셔서 감사합니다!
힘내세요! 짱짱맨이 함께합니다
짱짱맨 덕분에 힘이 납니다!^^
You got a 4.76% upvote from @inciter courtesy of @ferozah!