[doctorBME, essay] 편향(bias)과 분산(variance)의 사이에서

안녕하세요, @doctorbme 입니다. 오늘은 조금 편하게 적어봅니다.
기계학습(Machine Learning)을 다루다보면, 한번쯤 편향과 분산의 트레이드 오프(Bias–variance tradeoff)를 마주할 때가 있습니다. 알고리즘을 학습시킬 때, 우리가 학습시킨 알고리즘의 예측이 얼마나 정답에서 떨어져 있는지를 반영하는 편향(bias)과, 예측 자체가 얼마나 변동폭이 큰 것인지를 반영하는 분산(variance)는 서로 트레이드 오프(trade off) 관계에 있고, 이 두 개의 합이 결국 우리가 예측하는 알고리즘의 오차를 결정하는 만큼, 이 두가지 값을 적절하게 균형으로 맞추는 것이 중요하다는 것입니다.
이해를 돕기 위해 아래 그림을 살펴보도록 합시다.
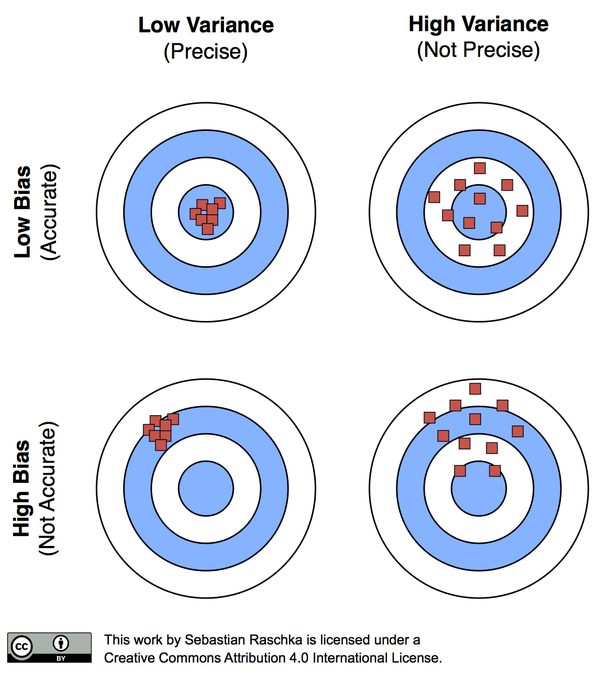
그림 1. 편향과 분산의 개념 (정확도(accuracy)와 정밀도(precision)의 개념)
왼쪽 위 그림처럼, 정확한 목표에 정확히 들어맞는다면 더할나위 없을 것입니다. 그리고 오른쪽 아래 그림처럼, 맞추려는 목표에도 어긋나고 그마저도 퍼져있다면 이 알고리즘은 실패한 것으로 볼 수 있습니다. 보통은 대체로 결과가 잘 모이기는 하는데 목표에서 빗겨있거나 (편항이 큰 상황: 왼쪽 아래 그림), 아니면 평균적으로 결과가 목표 근처에 있기는 한데, 예측을 할 때마다 퍼져있는 상황 (분산이 큰 상황: 오른쪽 위 그림)이 됩니다.
중요한 것은 이러한 편향과 분산이 트레이드 오프 관계에 있기 때문에, 어떠한 알고리즘이 학습하는 과정에 있어서 편향을 줄이려면 분산이 커지고, 분산을 줄이려면 편향이 커져, 결국 두 가지의 균형을 잘 찾아야한다는 것입니다.
예를 들어 2차원 평면에서, 두 개의 클래스를 구분하는 문제를 생각해보면, 클래스를 구분하기 위해 어떠한 경계를 설정해야할지에 따라 성능이 달라지는 것을 관찰할 수 있습니다.
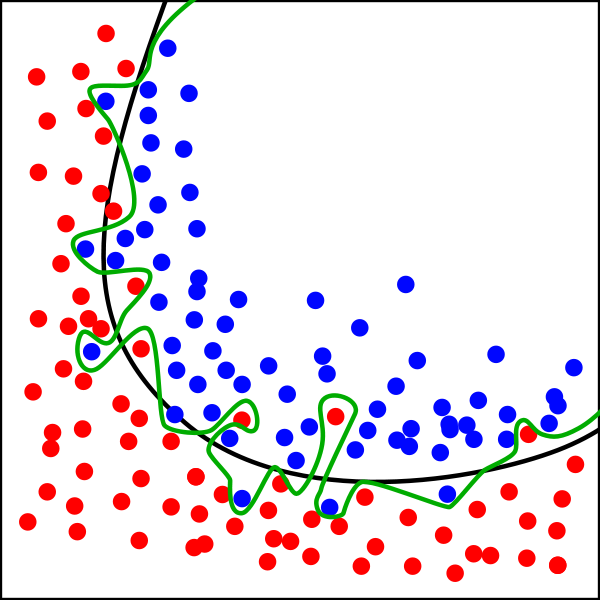
그림 2. 두 개의 클래스를 구분하기 위한, 두 가지의 경계 설정
위 그림에서, 학습데이터는 빨간 점과 파란 점으로 주어지고, 빨간 점과 파란 점의 영역을 구분하기 위해서는 검은 색을 흔히 생각할 것입니다. 뭔가 매끄러운 경계가 존재한다고 상상하는 것이 자연스럽습니다. 초록 색의 경계로 설정해도 좋기는 하겠지만, 여기에서 주어진 학습 데이터 상에서 오차가 거의 0에 가깝게 떨어지더라도, 또 다른 학습 데이터 셋(training set)이 존재해서, 이와 같은 방식으로 학습하는 경우, 학습된 모델 사이에 편차가 존재할 것입니다. 즉, 매번 학습 데이터 셋이 바뀔 때마다, 경계의 모양은 매우 구불구불할 것이고, 다시 말하자면 경계의 모양의 변화폭은 상당히 다양할 것으로 예상할 수 있습니다. 즉, 모델의 분산이 증가하는 것입니다.
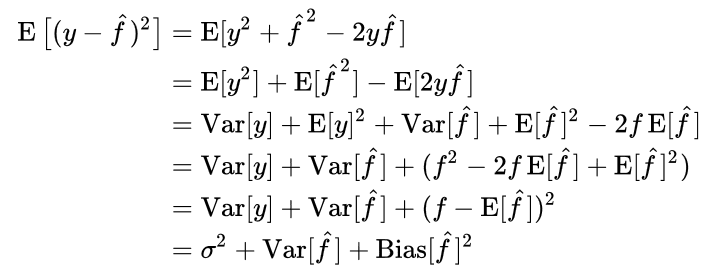
결국 전체 에러는 위와 같이 나타나는데, 첫번째 항은 우리가 절대로 줄일 수 없는 에러, 두번째는 예측 모델들 자체의 분산, 세번째는 정답 (참) 모델과 우리가 구하는 예측 모델의 기대값과의 차이인 편향을 반영합니다. 우리가 모델을 학습시키는 것은 결국 전체 에러를 가장 낮추는 방향으로 진행되기 때문에, 전체 에러가 주어질 경우, 그 사이에 편항과 분산의 트레이드 오프가 일어나게 되는 것입니다.
(여기서 주의해야할 사항 중 하나는, 학습 데이터셋 자체도 하나가 아니라, 여러 학습 데이터셋이 존재할 수 있고, 이에 대한 모델 자체의 기대 모델이 존재할 수 있다는 것입니다.)
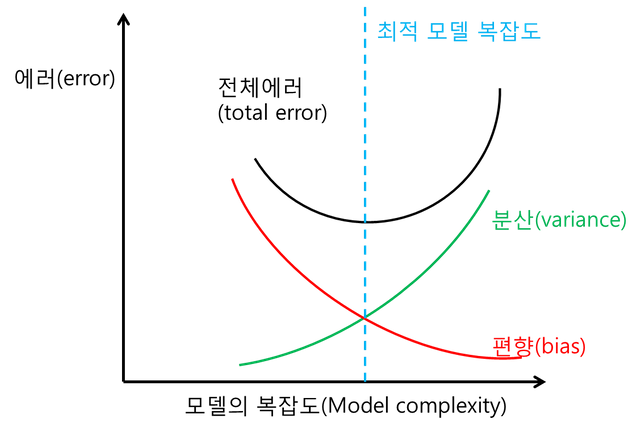
그림3. 전체 에러와 분산 및 편향의 관계
여기에서 우리는, 적절한 모델이라는 것이 결국, 분산과 편향의 균형을 고려하여 한쪽으로 치우치지 않는 최적의 복잡도를 찾는 것임을 알게 됩니다. 하지만 뒤집어서 생각해보면, 편향이 매우 작거나 분산이 매우 작은 상황이 사실은 최적의 상황이 아니라는 것도 알게 됩니다.
우리는 어떠한 사안에서든, 이러한 편향과 분산의 관계를 염두할 필요가 있다고 생각합니다. 어떠한 사안을 너무 단순하게 보게 된다면, 의견을 통일하기는 좋지만 사실 우리가 원하는 진실과 다소 떨어진 해답을 얻게 될 수도 있습니다. 한편 어떠한 사안을 너무 복잡하게 보게 된다면, 의견의 다양성을 반영하고 그 중심을 찾는다는 점에서는 좋지만 결국 의견이 하나로 모아지지 않을 수 있습니다. (혹은 의견을 수렴하는 데에 매우 많은 비용을 지불해야할 것입니다.) 따라서, 의견의 무조건적인 통일을 추구한다거나 의견의 매우 많은 다양성을 추구하는 것은, 결국 적절한 균형을 깨뜨리는 일이 될지도 모릅니다.
이러한 사안은 어떠한 문제에 대한 각자의 의견 수렴에 관한 이야기가 될 수도, 우리가 우리 삶을 살아나가는 방향과 경험을 위한 의사결정의 경우에도 해당이 될 수 있을 것입니다. 우리가 계속해서 편향된 결정을 하면서 산다면, 우리 삶이 주는 다양성과 다채로움을 알게되긴 힘들 것입니다. 그리고 우리가 계속해서 다양한 경험에만 집중한다면, 삶의 중심을 유지한 채 어떠한 길을 따라 앞으로 한걸음씩 나아가기 어려울지도 모릅니다. (혹은 그러기에 많은 시행착오를 겪어야할지도요.)
결국 우리가 이러한 사실에서 생각해봐야할 관점은 아래와 같습니다.
어떠한 학습이든 사안이든 혹은 삶이든, 필연적으로 발생할 수 밖에 없는 고유 에러가 존재한다. 이러한 에러가 어느정도 존재할 수 있음을 인정하는 것이 필요하다.
편향을 완벽히 제거하거나 분산을 완벽히 제거하는 것은 불가능하다. 그러한 방향은 오히려 우리를 위험에 빠뜨리게 될 것이다. 우리는 언제나 편향과 분산 사이에서 균형을 찾아야한다.
이것이 편향(bias)과 분산(variance)의 트레이드 오프(trade off)가 우리에게 던지는 화두일 것입니다.
그림 출처
그림 1, https://sebastianraschka.com/blog/2016/model-evaluation-selection-part2.html, Creative Commons 4.0 - BY
그림 2, https://en.wikipedia.org/wiki/Overfitting , Creative Commons 4.0 - BY SA
그림 3. 자체 작성
{kind=link}
완벽한 분류기는 없다는 사실을 알면서도, 충분한 성능을 가진 것들에 비해 0.1%라도 더 좋다는 식의 글을 쓰기 위한 실험들이 머릿속을 스쳐지나갑니다 ;ㅂ;
이런 것들은 그만하고 싶네요... 푸념 푸념.
고생이 많으시네요. 사실 저는 그 0.1%의 성능 향상을 그리 믿지 않는 편이기는 합니다. 아무리 Cross validation을 써서 수행한다고 한들, 우리가 모르는 학습데이터셋은 분명히 존재하기 마련일테니까요. 잘 되시기를 기원합니다. ㅠㅠ
편향과 분산 사이의 균형을 정확히 맞추기는 아마 힘들 듯 해요.
그냥 근사치 범위로 평향과 분산의 경계에서 우리는 균형을 이루었다라고 생각하는 것일 뿐이죠.
사실 최적이라는 개념을 맞추기가 매우 힘들겠지요. 실제로 완벽히 떨어지는 최적이라는 것은 존재하기 어렵다는 생각입니다. 실제 삶에서는 편향과 분산 또한 시행착오를 겪어가며 유추하고 맞추어야하기에, 좀 더 힘들지도 모르겠습니다.
빅데이터의 문제였나? 그런데서도 비슷한 내용을 본거같군요. 어느쪽 방향으로 편향되면 더더욱 그 상황을 고착화시키는 데이터를 제공한다던가요
아마 샘플링의 문제가 아닐까 싶기도 합니다. (공교롭게도 @sampling 님의 아이디가 눈에 띠는 군요! 신기합니다.) 사실 그러한 편향을 없애기 위해 많은 노력을 합니다. Cross validation도 그러한 일환이겠지요.
그럼에도 불구하고, 우리가 다루는 데이터의 클래스들이 항상 균일한 분포 (혹은 크기)를 가지는 것은 아니기에, 불균형된 데이터를 다루는 상황이 발생하기도 합니다.
우리가 찾고자하는 모델이, 파라미터 공간 안에서 항상 convex를 가정할 수는 없기에, local minimum에 다가가다보면, 결국 그 안에서 빠져버리는 것 같습니다. 아마 이 이야기를 해주신 것 같다는 느낌이 드는데요, 이 부분을 해결하는 것은 참 어렵다는 생각입니다.
데이터 분석이 삶에 대한 통찰로 이어지는 과정을 엿본 것 같네요. 어쩌다 생각이 그리로 흘러가셨는지가 궁금해져요 ㅎㅎ
@홍보해
종종 과학이 주는 통찰이 삶에 미치는 영향에 대해 고민해볼 때가 있습니다. 과학은 일견 합리적이고 가치중립적으로 생각되기 마련이지만, 결국 과학을 하는 주체가 사람이다보니, 사람 친화적인 관점에서 해석해볼 때가 있습니다.
안녕하세요? 반갑습니다.
균형점을 찾는 것이 항상 힘들군요. 재미난 글 잘 보고 갑니다.
균형이라는 게, 애초에 찾기 힘들기 때문에 균형이 아닐까 하는 생각도 있습니다. 재미있으셨다니, 저도 감사드립니다.
편향과 분산을 의사결정 과정과 연결짓는 글 전개가 매우 흥미롭고 재미있네요. ^^b
얼핏보면 따로 떨어진 학문들이 결국 인생의 이야기를 담고 있을 때가 있는 것 같습니다. 이러한 한계를 알지 못할 때, 과도한 강박 같은 것이 발생하는 것 같기도 하고요. 좋게 봐주셔서 감사합니다!
Congratulations @doctorbme! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOP편향에 대해서 자세한 정보 도움이 된 것 같습니다. 편향과 분산은 트레이드 오프 관계라 균형을 맞춰서 최적화 시켜야 한다는게 중심 내용인 것 같네요. 번외로 편향과 편차는 어떤차이가 있는건가요? 향은 방향을 가리키는 거고 차는 값의 차이니 벡터와 스칼라의 차이라고 바야 할가요?
@yourwisedentist님이 당신의 글을 번역 요청했습니다Powered by Steemit Translation by CICERON