[BME, 역학, Intro] 네트워크를 활용한 질병 유행의 예측: 개괄
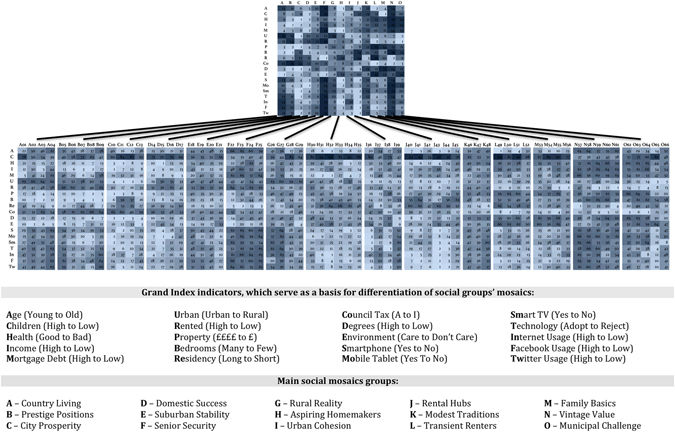
Experian Mosaic Public Sector database의 구성: 참고문헌 [1]의 그림[1]
출처: Google Trends can improve surveillance of Type 2 diabetes
저작권: CC BY 4.0
참고문헌[4]의 연구에서 사용한 데이터셋이며, 영국 지역별로 인구학적 정보와 생활 방식, 약간의 의무기록 정보 혹은 선호하는 커뮤니케이션 채널 등에 관한 정보를 담고 있습니다. 우리의 정보가 카테고리화되어 생성되고 기록되고 저장됩니다. 여기서부터 우리는 어떠한 (밝혀지지 않은) 정보나 원리를 도출할 수 있을까요.
안녕하세요, @doctorbme 입니다. 오늘은 어떠한 질병이 유행하기 전에 검색 엔진 검색 결과 또는/그리고 여러 데이터를 바탕으로 질병의 유행을 예측하고자 하는 연구들에 관하여 살펴보고자 합니다. 그 중에서도 이러한 연구를 설계할 때에 고려해야할 사항에 대해서 살펴보도록 하겠습니다. 이 분야에 대표적인 연구 중 하나는 Google Flu Trends, GFT로부터 시작합니다.
연구의 시작
2009년에 Nature 지에는 구글의 검색 엔진 - 구글 트렌드 (google trend) 검색결과로 독감의 발병을 미리 예측할 수 있다는 연구가 발표되었습니다. 인플루엔자와 관련있어 보이는 환자(ILI, influenze-like illness)와 연관된 45개의 쿼리를 이용하여, 실제로 ILI로 인해 의사를 방문한 데이터와 특정 시간 t에 이러한 ILI와 관련되어 검색된 결과를 log-odds (로그 승산)의 선형 모델로 구성한 연구입니다. 여기서 ILI를 인플루엔자와 관련있어 보이는 환자로 표기하였으나, 인플루엔자(독감)와 비슷한/같은 증상을 보이면서 급성 호흡기 감염을 나타내는 환자를 의미하는 것이기 때문에 무조건 독감으로 확진되는 것은 아닙니다.
이러한 검색 키워드에는 Influenza complication (독감 합병증), Cold/flu remedy (감기/독감 치료법), General Influenza Symptoms (일반적인 독감 증상) 등이 포함되어 있습니다. 흡사, 우리나라 사람들이 어딘가 아플 때 포탈에서 검색하는 키워드와도 비슷해보입니다.
이러한 예측이 잘 맞나 살펴보기위해 이 연구에서는 correlation (상관)과 시기에 따른 ILI의 비율을 실제 CDC 데이터와 예측 모델 사이에 비교해봅니다. 그리고 상당히 정확하게 맞아떨어집니다. 이 연구는 GFT (Google Flu Trends)로 불리며 검색 네트워크 상에서 질병의 예측을 도모하는 대표적인 연구로 불립니다.
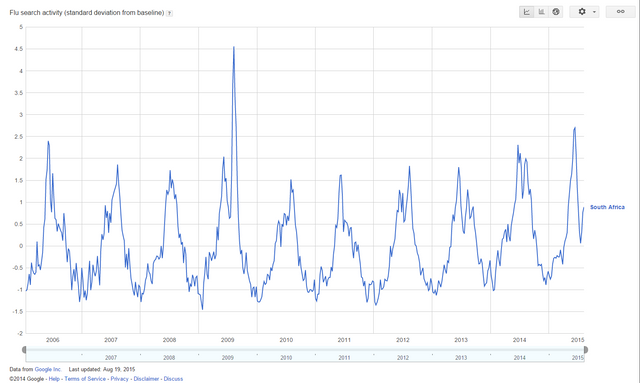
Google Flu Trends data, South Africa
출처: https://en.wikipedia.org/wiki/Google_Flu_Trends 및 저작권: public domain
{kind=link}
추가적인 그림은 이 링크를 참고하시길 바랍니다.
반론
하지만 항상 이러한 예측이 맞아떨어지지는 않았습니다. GFT가 독감의 유병률에 관하여 실제보다 과도한 수치로 예측한다는 사실이 드러났기 때문입니다. 2012년 크리스마스 즈음에서 GFT는 CDC data에 비해 2배 정도의 수치를 예견합니다. 그리고 1) 사용자들의 검색 패턴이 시기별로 달라지는 것 2) GFT의 데이터를 기존 전통적인 데이터와 대비되는 것으로 인식하여 상보적으로 사용하지 않는 것 3) 구글의 검색 엔진 알고리즘과 이에 사용되는 데이터 가공이 업데이트 되는 것 - 결국 시기별로 달라지기 때문에 질병 모델에 영향을 미치는 것이 지적되었습니다.
결국 GFT는 현재 질병 유행에 관하여 미래를 예측하는 서비스를 공개적으로 시행하지 않으며, 과거의 데이터를 찾아볼 수 있을 뿐입니다.
https://www.google.org/flutrends/about/
여러 시도
하지만 독감 유병률에 대한 오차를 줄이려는 연구들은 다양한 시도 하에 꾸준하게 이루어지고 있습니다.
예를 들어 Using Networks to Combine “Big Data” and Traditional Surveillance to Improve Influenza Predictions 연구의 경우에는 구글 독감 트렌드 (GFT, Google Flu Trends)와 미국 질병통제예방센터(CDC; Centers for Disease Control and Prevention)데이터를 결합해서 좀 더 나은 독감 발병 예측을 해보고자 합니다. 여기서 좀 더 나은 독감 발병 예측이란, 확진된 환자의 분포 및 양상을 가지고 있는 CDC의 데이터를 바탕으로, 모델링으로부터 얻은 유병률과의 차이(오차)를 줄이는 것입니다.
이 때 GFT가 독감과 관련한 쿼리 분석을 통해 유병률을 예측한다면, 이러한 모델에 지역적 특성을 결합하여 모델을 정교화하고자 하는 시도인 것입니다. 예를 들어 과거에 기록된 (가장 최근의) CDC 데이터를 바탕으로 각 지역을 노드로 설정하여 지역 간의 연결성(connectivity)과 중심성(centrality)이 얼마나 독감의 전파에 기여하는지를 추가적인 요인으로 구성할 수 있습니다. 이러한 연구는 기본적으로 1) 지역적 특성과 연관을 반영하고 2) 시계열적 특성을 반영하기 위해 기존 과거의 데이터를 활용하는 방안을 전략으로 삼습니다. 이 연구는 기존의 검색 결과와 전통적인 데이터가 제대로 결합하였을 때에 조금 더 정확한 유병률을 구할 수 있다는 점에 의의가 있습니다. 즉, 하이브리드 (hybrid) 모델의 중요성을 나타냅니다.
다른 연구에서는, 독감이 아닌 당뇨병을 대상으로 하였지만, 질병 발병 예측과 관련하여 어떠한 요인이 중요하게 작용할 것인지에 파악하고자 시도를 합니다. 이 때에 회귀 모델 (regression 모델)을 사용하는데, Akaike Information Criterion (AIC)을 이용하여 어떠한 변수를 넣을지 뺄지를 결정합니다. 참고로 AIC는 주어진 가설(파라미터들)에 대해 데이터의 확률을 최대화하는 MLE(Maximum Likelihood)와 가급적 간단하게 구성된 가설(적은 인자 수) 사이의 균형을 취하는 철학을 가집니다. 이러한 요인들은 기존의 웹사이트 상에서 자가진단을 할 수 있는 서비스들 - Diabetes Risk Calculator, ARIC Diabetes Risk Calculator, QDiabetes 등과의 비교 분석을 거칩니다.
또 다른 어떤 연구에서는 generalized linear models (GLM, 일반화선형모형) 과 generalized linear autoregressive moving average (GARMA)를 사용합니다. 일반화선형모형의 경우에는 종속변수가 정규분포를 가진다는 가정을 할 수 없을 때 사용하며, GARMA 의 경우에는 ARMA를 바탕으로, 정규분포를 따르지 않는 시계열 데이터를 분석할 때 사용합니다.
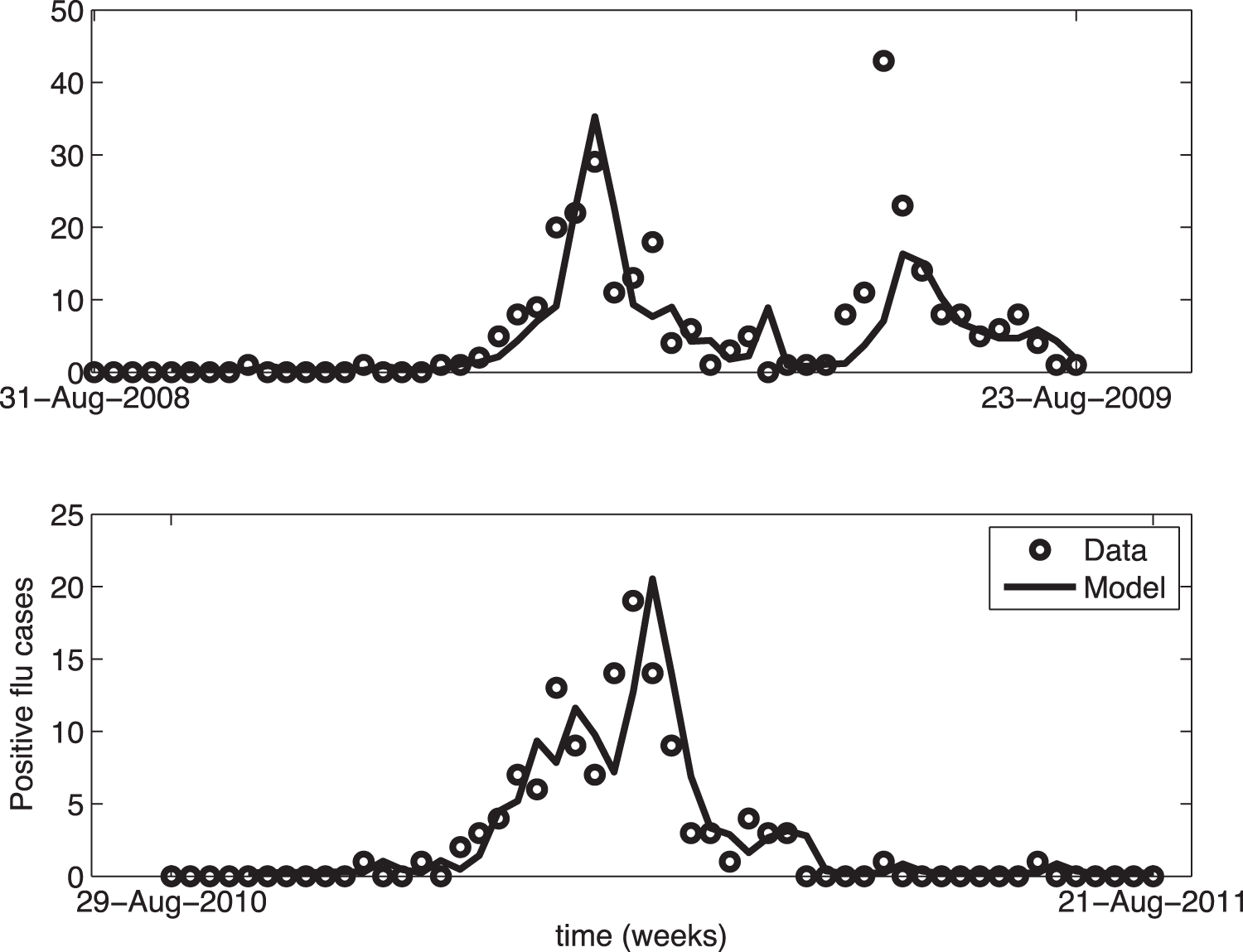
논문[4]의 그림 ( http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0056176 )
저작권: Creative Commons Attribution License (특별한 제한은 걸려있지 않습니다.)
GARMA를 사용하여 인플루엔자 시즌에서 실제 데이터와 모델의 비교를 함.
이외에도 다양한 연구들이 상당수 존재하며, 흥미로운 연구는 후속 글을 통해 조금 더 깊이 살펴보도록 하겠습니다.
결론
결국 네트워크를 기반으로 한 질병 유행에 관한 예측 모델링은,
- 예측을 하고자하는 질병의 특성과 정보가 데이터 취득 채널에 잘 반영되어 있는가
- 기존의 전통적인 데이터 소스와 어떻게 결합하는가 (기존 데이터를 상보적으로 잘 활용할 수 있는가)
- 시간 혹은 공간의 추가적인 정보를 반영할 수 있는가
- 사용자 (환자/일반인)의 (데이터 생산과 관여된) 행동 특성 및 변화를 반영할 수 있는가
정확도를 비롯한 성과가 결정된다고 생각해볼 수 있을 것입니다.
최근 다양한 소셜네트워크 서비스들이 존재하고 여기서부터 파생되는 단어 혹은 문장들에 대한 자연어처리나 쿼리 분석 등을 통해 다양한 질병을 예측하고자하는 연구들이 시도되고 있습니다. 이러한 연구들이 과연 미래의 의료에 어떻게 작용하게될지 기대해보아도 좋을 것 같습니다.
참고문헌
[1] Jeremy Ginsberg, Matthew H. Mohebbi, Rajan S. Patel, Lynnette Brammer, Mark S. Smolinski & Larry Brilliant, Detecting influenza epidemics using search engine query data, Nature volume 457, pages 1012–1014 (19 February 2009)
doi:10.1038/nature07634
[2] David Lazer, Ryan Kennedy, Gary King, Alessandro Vespignani, The Parable of Google Flu: Traps in Big Data Analysis , Science 14 Mar 2014:Vol. 343, Issue 6176, pp. 1203-1205 DOI: 10.1126/science.1248506
[3] Michael W. Davidson, Dotan A. Haim & Jennifer M. Radin,Using Networks to Combine “Big Data” and Traditional Surveillance to Improve Influenza Predictions, Scientific Reports volume 5, Article number: 8154 (2015) doi:10.1038/srep08154
[4] Andrea Freyer Dugas , Mehdi Jalalpour, Yulia Gel, Scott Levin, Fred Torcaso, Takeru Igusa, Richard E. Rothman, Influenza Forecasting with Google Flu Trends, PLOS ONE 2013, https://doi.org/10.1371/journal.pone.0056176
[5] Nataliya Tkachenko, Sarunkorn Chotvijit, Neha Gupta, Emma Bradley, Charlotte Gilks, Weisi Guo, Henry Crosby, Eliot Shore, Malkiat Thiarai, Rob Procter & Stephen Jarvis, Google Trends can improve surveillance of Type 2 diabetes , Scientific Reportsvolume 7, Article number: 4993 (2017) doi:10.1038/s41598-017-05091-9

Google Flu Trends가 예측이 높다고는 생각되지 않네요.
실제 가짜뉴스처럼 어떤 공포와 영향력 있는 누군가에 발언으로 검색되는 양이 급속도로 늘어날 수 있기 때문에 약간 부정적인 생각이 되네요.
네. 정확히 보셨습니다. Google Flu Trend 자체는 예측이 그리 높지 않습니다.
사실 이러한 영향은 인과관계와 상관관계의 차이로도 볼 수 있습니다. 이러한 예측을 할 때에는 1) 독감에 걸렸거나 독감 증상이 있는 사람이 2) 증상의 발현이 존재하여 관련 키워드를 검색한다 라는 1 -> 2 로 이어지는 인과관계를 가정하게 되는데, 만약에 어떠한 독감 혹은 독감과 유사한 질병에 대한 공포가 확산되거나 미디어에서 이에 대해 경각심을 불러일으키는 캠페인이 존재하면, 1) 미디어에 노출된 사람 중 관심 있는 사람이 2) 독감과 관련된 정보를 검색한다 라는 식으로 변모하기 때문에 이를 구분해내는 것이 어렵습니다.
그래서 최근 연구는,
이러한 식의 방안을 내세우고 있습니다.
그리고 구글에서는 가짜 뉴스에 대해서, 검색을 어떻게 하면 개선할 수 있을까 고민하고 있기도 합니다. Google tweaks Search to help combat ‘fake news’
https://techcrunch.com/2017/04/25/google-tweaks-search-to-help-combat-fake-news/
@yourwisedentist님이 당신의 글을 번역 요청했습니다Powered by Steemit Translation by CICERON
@yourwisedentist님이 당신의 글을 번역 요청했습니다Powered by Steemit Translation by CICERON