[BME, CS, radiology] 폐결절(pulmonary nodule)을 분류(classification)하기 위한 딥러닝(deep learning)
안녕하세요, 오랜만에 인사드립니다. @doctorbme 입니다.
인공지능(AI)의 등장은 사실 의학계에서도 많은 변화를 일으킬 것이라 기대하고 있습니다. 사실 중요한 것은, 어떠한 데이터로 어떠한 도구를 통해 어떻게 적용하느냐이겠지만, 대표적인 분야인 이미지/영상 분류에 있어서 어떻게 임상적으로 적용할 수 있느냐에 대한 가능성을 살펴보는 것은 대표적인 분야이겠습니다.
사실 CT 이미지를 바탕으로, 임상적으로 유의미한 결과를 도출할 수 있는 연구를 해보자는 시도는 상당히 많이 이루어져 왔고, 지금도 많이 이루어지고 있습니다. 사실 여기서 중요하게 생각해보아야할 문제는 다음과 같다고 생각합니다.
- 데이터 확보에 있어서 Gold-standard를 어떻게 확보할 것이냐, 그리고 정의할 것이냐에 대한 문제
- 실제 알고리즘이 개발되었을 때, 어떻게 적용할 수 있을 것이냐. 적용에 대해 이해관계자들에 대해 설득할 수 있을 것이냐에 대한 문제
이러한 문제들이 존재하기에 연구자들은, 개발된 알고리즘이 최소한 의사의 임상 활동을 보완할 수 있으며, 충분히 괜찮은 (사실 이렇게 정의하기는 좀 애매합니다만) 성능을 보인다는 것을 보이고자 합니다.
오늘 리뷰할 논문은 Towards automatic pulmonary nodule management in lung cancer screening with deep learning 입니다. 폐결절을 분류하는 연구는 이미 많은 수가 시도되고 있지만, 그 중 하나를 뽑아, 어떠한 과정으로 적용하는지를 방법론적인 측면에서 살펴보는 것도 의미가 있다고 생각합니다.
Scientific Reports 저널에 게재된 논문의 경우 Creative Commons BY 4.0이 걸려있기 때문에, 편하게 그림과 내용을 이용할 수 있습니다.
시작하기에 앞서 @radiologist 선생님의 아래 두 글을 읽어보셔도 도움이 될 것 같습니다.
컴퓨터가 CT판독 할 수 있을까
컴퓨터는 폐암의 종류를 잘 예측할 수 있을까?
방법론
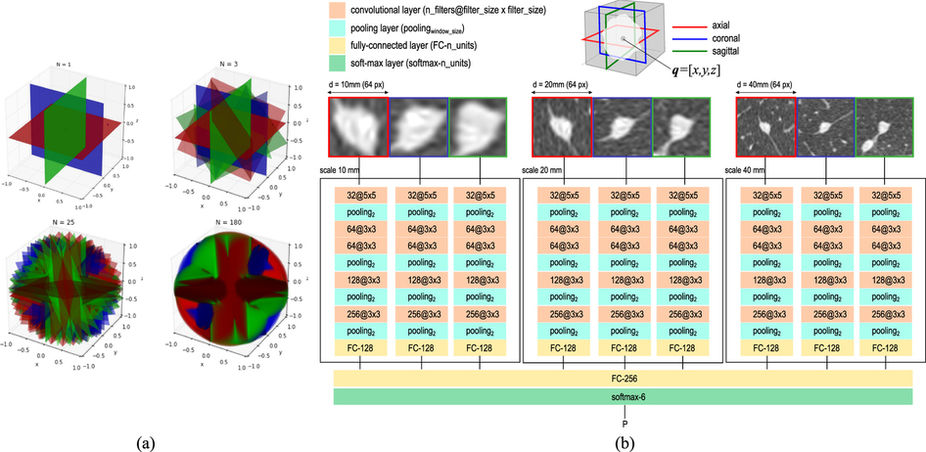
논문의 figure 4. 이 논문에서 사용된 데이터 구성과 딥러닝 구조를 간결하지만 핵심적으로 나타낸 그림입니다.
우선 이 논문의 데이터 구성은 크게 2가지 측면에 특이점이 있습니다.
(3D) 이미지의 어떤 점에 대해서 axial, coronal, sagital 방향을 고려하고, 심지어 각도를 조금씩 비틀어가면서, 데이터의 갯수를 증가시킵니다.
이미지 스케일 (크기)에 따라 분류기의 성능이 차이날 수 있다는 것을 알기에, 동일한 결절(nodule)에 대해 10mm, 20mm, 40mm에 해당하는 이미지를 모두 고려합니다.
1번이 무슨말인가 하면, 애초에 우리의 폐 조직은 3차원이기 때문에, 이러한 3차원에 해당하는 이미지를 무수한 갯수의 일종의 정육면체로 조각내서 분석할 수 있다고 하면, 데이터를 구성할 때 취하는 단면적이 면에 항상 수직한 것이 아니라 비스듬하게도 잘라서, 그 단면적을 바탕으로 이미지를 구성하겠다는 이야기입니다. 그러니 여러 각도로 자를수록 (논문에서는 N이 커지는 것을 의미합니다.) 하나의 결절(nodule)에 대해 여러개의 2D 이미지 데이터가 생성될 것입니다. (위 그림의 왼쪽)
이는 두가지 측면에서 장점을 가집니다.
- 부족한 데이터의 갯수를 보충할 수 있습니다.
- N을 조절하여 (비스듬하게 자르는 갯수를 조절하여) 각 label간의 이미지 갯수 분포에 대해 균형을 맞출 수 있습니다.
2번에 대해서는 이미지의 다양한 크기 정보를 반영할 수 있습니다. 일종의 크기 보정이라고 생각하셔도 무방합니다. 우리가 인지하기에는 같은 결절에 관한이미지라도, 학습 상에서는 아예 다른 이미지라고 생각 (알고리즘이 생각한다는 표현은 좀 이상하지만) 할 수 있기 때문입니다. 같은 결절에 대한 다양한 정보와 특성을 반영한다는 측면이 중요합니다.
그 외에도, 이미지를 회전(rotate)시키거나, 뒤집거나 (flip), 약간 이동시켜서 (shift), 동일한 결절(nodule)에 대해 이미지 갯수를 증가시킬 수 있습니다. 딥러닝의 경우에는 학습을 위해 충분한 수의 데이터 확보가 중요한데, 이미지 데이터 중 이러한 방법이 이렇게 가능한 경우가 있습니다.
CNN (Convolutinal neural network)를 사용하였고, 맨 마지막에 6개의 뉴런을 가진 softmax층을 두어, (각 라벨에 해당되는 확률을 뽑아줍니다) 가장 높은 확률을 가진 라벨(label)을 해당 라벨로 출력하게 됩니다. (위 그림의 오른쪽)
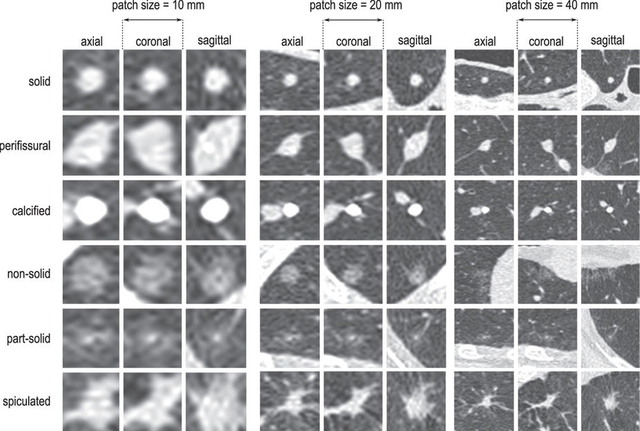
논문의 그림1. 이미지 스케일(scale)에 따른 각 결절(nodule)의 모양. 여기서 이미지 scale은, 동일한 결절에 대해 이미지 확대/축소를 나타낸 것으로 해석하시면 되겠습니다. 세로축이 각 결절의 종류, 가로축이 스케일에 따른 결절의 모양을 나타냅니다.
이 학습 방식에서 독특한 것은, 애초에 하나의 데이터가 3개의 이미지로 구성되어 있고 (axial, coronal, saggital), 학습을 시킬 때도, 이러한 3개의 이미지가 동시에 입력된다는 것입니다. 당연히 이러한 3개의 이미지는, 서로 수직한 단면을 반영합니다.
결과
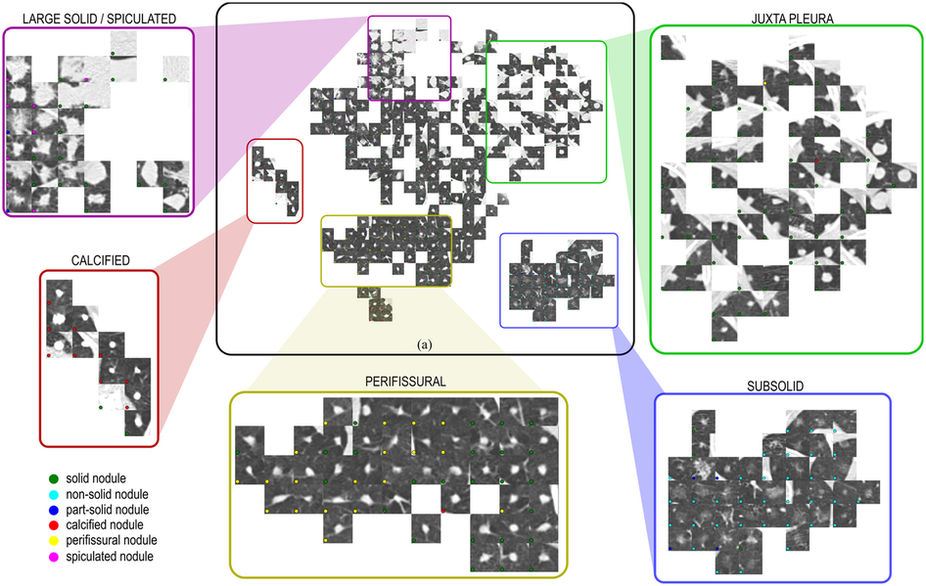
논문의 그림3. 다차원의 데이터를 저차원으로 시각화하는 t-SNE가 사용되었고, 각 지역들이 결절의 종류에 따라 국소적으로 분포되어 있습니다.

논문의 그림2. 각 결절의 종류에 따라, 전형적인(typical) 결절의 모습과 비전형적인 (atypical) 결절의 모습을 나타냅니다. 딥러닝을 사용하였을 때, 전형적일 수록, 해당 라벨로 판단할 확률이 높아집니다 (p=1에 가까워짐). 이는 그림에서 오른쪽으로 갈수록 확률이 증가합니다. (더 전형적임일 나타냅니다.)
성능 비교에 대해서는 4명의 임상의사와, 1개/2개/3개의 스케일을 각각 반영한 딥러닝 알고리즘의 성능을 비교합니다. 이 때 특이할만한 사항으로는, 각 의사들 간의 의견 일치도(불일치도)를 파악하기 위해서 Cohen's kappa를 사용하였다는 것이며, 알고리즘과 의사 간의 의견 비교 도 시행되었다는 점입니다. 알고리즘의 경우, 의사들과 비슷한 일치도를 보였다고 결론내리고 있습니다.
정확도나 F-measure의 경우에도, 하나의 gold-standard를 따라 파악하기 보다는, 각각의 임상 의사들의 견해를 여러개의 gold-standard로 보고, 이에 따라 다른 의사의 의견이나 CNN의 성능을 파악하는 방식을 취하고 있습니다. 이는 애매한 판단 지점에 있어서 각 의사 간의 견해 차이를 최대한 반영하기 위한 노력으로 해석해볼 수도 있을 것입니다. (여개서 F-measure를 반영한 이유는, accuracy에 비해 skewed distribution에 대해 좀 더 강건하다고 알려져있기 때문입니다.)
CNN의 성능을 평가할 때에는 인간 이외에도, 항상 전통적인(?) 분류기와 비교하게 되는데, 여기에서는 Support vector machine과 K-means algorithm을 사용하여 비교합니다. 이 때 F-measure에서 CNN이 월등한 성능을 나타냈다고 이야기합니다.
주안점
사실 영상의학적 이미지를 딥러닝에 적용하고자 하는 시도는 상당히 많이 이루어지고 있기 때문에, 이 하나의 연구가 모든 것을 반영하기는 어려울 것입니다. 중요한 것은 어떠한 연구를 살펴보든, 이러한 연구가 앞으로 연구를 진행함에 있어서 어떤 점을 고려해야할 지에 대한 아이디어/관점을 얻는 것입니다. 제가 개인적으로 생각하기에, 이 논문에서 중점적으로 인지해야할 핵심 요소는
- 부족한 라벨(label)을 가진 이미지의 갯수를 어떻게 다양하게 증가시킬 것인가
- 하나의 결절(데이터의 요소)에 대해 얼마나 다양한 정보를 동시에 반영할 것인가
- 판단이 애매한 지점에 대해, 어떤 식으로 종합하고 성능을 평가할 것인가
위와 같은 3가지 요소를 중점적으로 살펴보아야 한다고 생각합니다. CT 이미지 뿐만 아니라, 의학의 영역에서 딥러닝(혹은 더 나아가 머신러닝)을 적용하고자 할 때 고려해야할 요소이기도 할 것입니다.
참고문헌
Francesco Ciompi, Kaman Chung, Sarah J. van Riel, Arnaud Arindra Adiyoso Setio, Paul K. Gerke, Colin Jacobs, Ernst Th. Scholten, Cornelia Schaefer-Prokop, Mathilde M. W. Wille, Alfonso Marchianò, Ugo Pastorino, Mathias Prokop & Bram van Ginneken, Towards automatic pulmonary nodule management in lung cancer screening with deep learning, Scientific Reports volume 7, Article number: 46479 (2017)
doi:10.1038/srep46479

Thanks!
인공지능과 의학... 어려운 분야 두개가 만났군요
이미 많은 병원에서 암 진료에 왓슨을 사용할 정도로 인공지능은 의학과 불가분의 관계가 된것 같습니다 :D
네. 언젠가는 두가지 분야의 학문이 결국 만나게 될 것으로 예측합니다. 왓슨에 대해서는 개인적으로는 사실 60:40 정도로 긍정과 부정의 전망을 같이 가지고 있는데, 기회가 되면 한번 풀어보겠습니다. :)
이미지를 자동으로 읽고 판단하려는 시도는 여기저기있군요
결국 방법론은 1) 어디에 2) 어떻게 적용하느냐가 중요해지는 시대가 오고 있는 것 같습니다. 어쩌면 이미지 판단/분류 뿐만 아니라 블록체인도 마찬가지가 아닐까 합니다.
일반적인 ConvNet 인데 32x32는 5x5 마스크를 쓰고 64x64는 3x3을 두 번 썼다고 표현한 점에서 꼼수(...)가 느껴집니다. 성능 평가의 방법이 또 제 눈을 사로 잡네요. 저도 써먹어봐야겠습니다 +_+ 리뷰 포스팅 오늘도 감사합니다.
논문에서는 약간의 성능 향상이 있었다고 주장하고 있습니다. Tweak은 사실 engineering의 분야이겠지요. 물론 그 구조 변경이나 파라미터 변경에 대한 이론적 근거를 마련하는 일은 또 다른 문제이겠습니다만...
결국 임상 의학 분야에 적용하기 위해서는, 성능 평가도 임상 의학의 룰을 따르게 되는 것이 아닌가 생각해봅니다. 어떠한 측면에서는, 기계적으로 적용되는 측면이 있기도 합니다. 가져다 쓰더니 잘 나오더라...이런 방향의 연구가 참 많지요. 사실은 제대로 가져다 쓰는 것이 중요해보이긴 합니다 :)
너무 케이스가 적어서 저저옫 비교로 일치했다라고 단정 하기가 참 애매하네요
보통 의학 (임상쪽) 데이터는 특히나 라벨이 달린 데이터 갯수도 적고, 생산하는 데에도 비용이 드는 편이기 때문에, 다른 분야에 비해 임상에서 쓸 수 있는 케이스 갯수는 한정적일 때가 많습니다. 병원 간 데이터가 공유되고 취합되면 좀 더 케이스가 늘어날 수는 있을 거라고 봅니다. 애매한 지점이 존재하는 것은 맞습니다. 그래서 다양한 metric을 보고자 하는 것 같습니다.
잘 보았습니다 ^^ 서두에 언급하셨다시피 과학적인 측면에서 CAD 및 AI 판독 시스템의 적용 크게 두가지가 문제가 아닐까 싶습니다.
첫째는 각기 다른 이미지들, 즉 CT 머신 회사도 다르고, 각 병원에서 쓰는 미세한 옵션들이 다른데, 이것을 어떻게 표준화 하느냐.
둘째는 이 논문에서 연구하는바와 같이 어떤 알고리즘이 최선인가.
두 가지 모두 어느 정도 가능성은 보이고 있지만 널리 적용되긴 아직은 멀었지 않나 싶습니다 (저만의 행복회로 일지도.. ㅎㅎ). 물론 법적인문제 (법적 문제시 얼마나 신뢰성을 둘지, 그 법적 책임은 누구에게 더 많을지.. 등)도 만만치 않게 넘어야 할 문제인 것 같구요..
여하튼 저는 오픈 마인드로 변하는 물결을 최소한 거스르지는 않아야 겠다고 생각하게 됩니다. 물결을 선도하면 좋겠지만, 쉽지는 않아보입니다..ㅠ 좋은 글 감사합니다 !
답글 감사드립니다. 말씀주신 두 가지 문제 모두 실질적으로(practically) 적용하기 위해서 풀어야하는 문제들로 생각합니다.
첫번째 문제의 경우에 있어서, 개인적으로는 preprocessing 과정에서 표준화된 몇가지 방법론이 등장하는 것이 제일 좋고, 정 안되면 학습 알고리즘 상에서 이러한 차이에 강건한(robust) 학습이 이루어져야한다고 생각합니다. 정말로 많은 수의 데이터가 확보된다면 이러한 옵션들을 커버할 수 있을 것으로 보이나, 역시 임상데이터는 비싸고, 라벨링은 노력이 많이 들고 하기에, 연구로 해본다라는 측면의 toy model 을 넘어선, 제대로된 모델을 만들기에는 아무래도 좀 더 시간과 협력이 필요할 것으로 예측하고 있습니다.
두번째 경우에는, 이러한 '최선'을 정의하기 위해, 여러 컨센서스가 필요할 것으로 보입니다. 저는 이부분에 대해 살짝 급진적으로 생각하는 것이 있는데, 알고리즘에서 '최선'이라는 것은 gold-stardard에 성능이 근접하는 것이고, 이러한 gold-standard 를 어떻게 정의하느냐, 혹은 알고리즘이 이러한 gold-stardard 마저 정의할 수 있는 시대가 올 것이냐에 해당하는 고민이 있습니다. 그러니 어떤 알고리즘이 최선이냐에 대한 물음은 결국 (궁극적으로는) gold-standard 를 어떻게 정의하느냐에 대한 물음으로 치환될 수 있다고 보이기도 합니다.
개인적인 생각으로는, 점점 임상 의학의 영역에 침투해들어올 것으로 보입니다. 물에 잉크를 떨어뜨리면 처음에는 국소적으로 분포하지만, 점점 퍼져나가게 되듯이, 널리 적용되기엔 아직 시기상조이지만, 결국에는 10년 내에는 정말로 많은 것을 바꿀 수 있다는 잠재성을 생각해보기도 합니다. :)
우문현답과도 같은 댓글이네요!
아직 방법론과 신뢰성의 측면에서 멀어보이지만, 의료 분야에서 'practical artificial intelligence'는 반드시 널리 쓰이리라 생각합니다 ^^