[딥러닝 토이즈, Deep Learning Toys] 자율주행을 향한 Semantic Segmentation!
안녕하세요. 딥루트 @deep-root입니다.
오랜만에 딥러닝 토이즈, Deep Learning Toys 시리즈를 작성하네요. 논문 제출 시기가 맞물려서 한동안 글을 작선하지 못했습니다 ㅠㅜ 반성합니다.
이전 포스팅들에 이어서, 오늘은 Semantic Segmentation demo를 소개해드릴까 합니다.
- [딥러닝 토이즈, Deep Learning Toys] Neural Style Transfer
- [딥러닝 토이즈, Deep Learning Toys] Quick, Draw! Handwriting recognition
Semantic Segmentation이란?

출처: http://mi.eng.cam.ac.uk/projects/segnet/demo.php#demo
Semantic segmentation은 어떤 의미 일까요?? 구글 번역기에게 물어보면 의미론적 세분화 라고 표현합니다.
우선 segmentation은 어떤 데이터를 부분별로 분할 하는 것을 의미하고, semantic은 의미정보를 의미하죠. 가령 자동차, 건물 등의 클래스 정보로 생각하시면 됩니다.
따라서, semantic segmenation은 데이터를 클래스 정보를 포함하도록 분할하는 것을 의미하겠죠?
어떤 (What) 물체인지에 대한 정보와 어디에 (Where) 있는지에 대한 정보를 함께 해결하려고 하는 것이죠.
간단하게 동영상을 한번 보시죠.
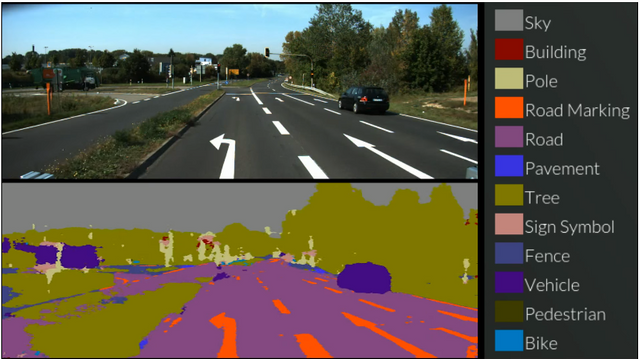
영상을 보면 입력영상 (위)를 네트워크에 넣으면 의미적으로 분할된 영상 (아래) 가 나오게 됩니다.
자동차는 진한 보라색, 도로는 연한 보라색, 건물은 붉은색 등, 영상에서 각 부분이 의미별로 분할되어 나온 것을 확인하실 수 있죠?? 영상의 각 픽셀별로 의미를 부여한다고 봐도 무방할 것 같습니다.
영상을 보시면 쉽게 유추하실 수 있겠지만, 이러한 semantic segmenation은 주변 정보를 의미 + 위치의 복합적인 형태로 제공하기 때문에 자율주행 자동차나 로봇에 있어서 굉장히 많이 연구되고 있는 기술이라고 할 수 있습니다.
SegNet!
따라서, 오늘 소개해드릴 데모는 바로 Deep learning 기반의 semantic segmentation중 굉장히 많이 인용된 논문 중 하나인 SegNet을 소개해볼까 합니다.
SegNet은 Convolutional Autoencoder 구조를 이용해서 Segmenation을 수행한 연구입니다. 논문은 Arxiv에 공개되어 있기 때문에 링크를 통해 누구나 다운로드 하여 확인하실 수 있습니다.
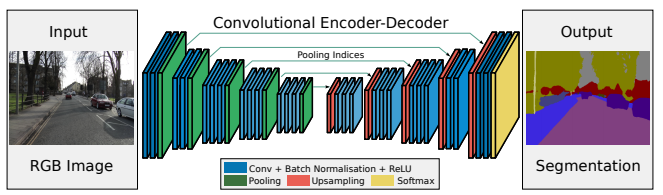
출처: https://arxiv.org/pdf/1511.00561.pdf
짧게 위 구조를 설명하자면 입력 영상 (왼쪽)이 네트워크에 들어가면, 우선 convolution + maxpooling 구조를 통해 압축되고, 중간 네트워크에서 다른 domain으로 변환, 다시 upsampling 되는 구조를 가지고 있죠. 여기서 특이한 점이라면 영상을 upsampling하는 과정에서 위치정보 손실을 줄이기 위해서 압축과정에서 사용한 maxpooling의 구조를 사용한다는 것에 있습니다.
자세한 설명은 이 포스팅의 취지와 맞지 않으니, 이제 어떤 데모를 해볼 수 있는지 한번 살펴보도록 하죠. SegNet Project Page에 들어가면 다음과 같은 데모를 해볼 수 있습니다.
- 국가를 선택하여 Google Street View에서 제공하는 랜덤 이미지를 테스트
- 사용자가 임의의 사진을 업로드하여 테스트
- SegNet 제작자가 제공하는 사진으로 테스트
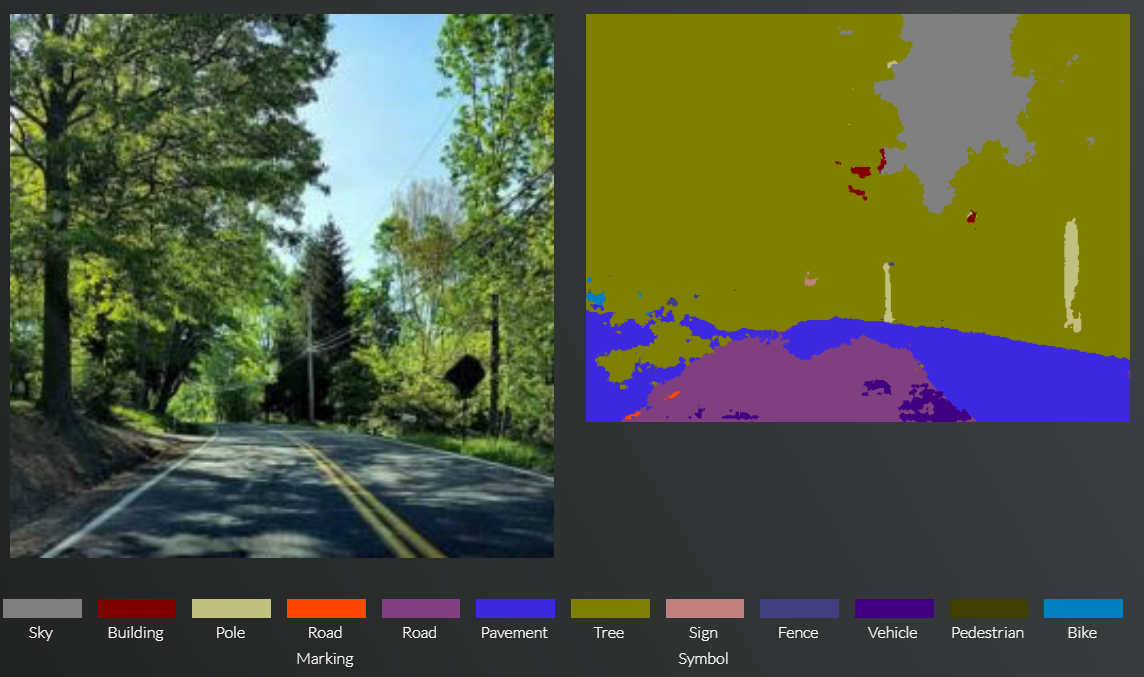
저는 여기서 제가 가지고 있는 도로 사진 한장을 넣어서 테스트를 해보았습니다. SegNet저자가 제공하는 사진만큼 잘 되지는 않지만 나무나 하늘, 그리고 잘 보이지 않는 전봇대 까지 어느정도 분류되어 나오는 것을 확인할 수 있습니다. 물론 도로의 경우에는 그림자 등에 의한 변화때문에 깔끔하게 나오지는 않았지만요.
관심있으신 분들은 다른 테스트도 한번 해보면 재밌는 결과를 얻으실 수 있을 것 같습니다.
마무리하며
이번 포스팅에선 Semantic segmenation으로 발표된 논문 중 하나인 SegNet의 데모를 살펴보았습니다. 앞서 작성한 글과는 다르게 논문에 대한 데모페이지라서 사용자 친화적인 다양한 기능을 제공하진 않지만 블랙박스나 스마트폰으로 찍은 사진을 한번 넣어보시면서 어떤 결과가 나오는지 보시면 좀 더 깊은 내용에 흥미가 생기실 것 같습니다.
그리고 이번 글을 소개하며 자율 주행을 향한 이라는 제목을 붙였는데요. 사실 SegNet의 결과를 가지고 자율주행에 사용할 수 있다고 말하기는 어려운 점이 있습니다. 논문도 벌써 2년이 넘기도 했죠. 따라서 이번 글의 마무리는 최근에 컴퓨터 비전 학회인 CVPR의 challenge에서 1위를 했던 PSPNet의 동영상으로 마무리 하겠습니다. 결과가 얼마나 빠르게 개선되고 있는지 보시면 깜작 놀라실 것 같아요!
그럼 다음 글에서 뵙겠습니다.
어른용 색칠놀이 게임으로 학습시킨 사례군요 흥미로웠었습니다 지금도 흥미롭구요 자동차분야 말고도 사용되는 분야가 많지 않을까 생각해봅니다
재미있게 보셨다니 감사합니다. 제가 일하는 쪽이 자율주행 분야라 자율주행으로 예시를 들었는데, 유동인구 분석 / 손실 정보 복원 등 다양한 분야에도 적용되고 있습니다. 위성사진 분석등에도 사용되기도 하구요 :)
!!! 힘찬 하루 보내요!
언제나 감사드립니다 !! :)