[알차니의 머신러닝] Sequence Models 감상평
Sequence Models
요즘 coursera에서 듣고 있는 강의는 Sequence Models(sequence는 연속적인 사건들, 배열, 순서라는 뜻이고 Model은 모형)이라는 강의인데 머신러닝, 딥러닝을 구현할 때 사용되는 RNN(Recurrent Neural Networks)이라는 모델을 토대로 공부하는 내용이다. 구글에 RNN으로 검색만 해도 양질의 자료가 검색이 되기에 여기서 서술할 것은 그 모델 자체보다는 학습하면서 느낀바를 적어보려고 한다.
RNN이란?
글의 이해를 돕기위해서 간단히 RNN에 대한 이야기로 시작할까한다. RNN은 Recurrent Neural Networks 약자이다. Neural Networks라는 말은 우리 몸의 뇌신경세포의 연결망을 본따서 만든 모델이라는 뜻이고 Reccurent라는 말은 되풀이되고 반복이 된다는 말이다. 신경망의 기본구조는 Input(입력)을 받아서 어떤 조정 을 거친 후에 Output(출력)을 내는 것이다. 어떤 조정의 방법에 따라 각 모델의 특성이 결정이 된다.
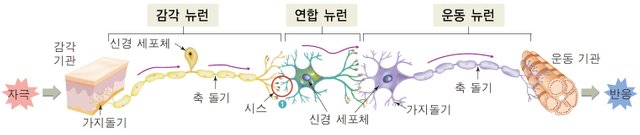
사람의 신경전달 과정
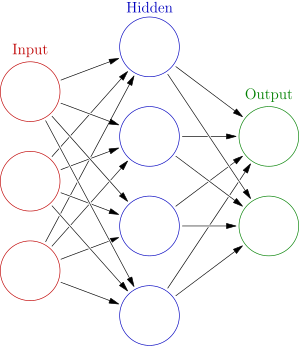
인공신경망
RNN은 Recurrent에 current라는 단어를 포함하고 있어서인지 직관적으로 흐름과 관련된 느낌을 주는데, 실제로 RNN은 각 뉴런의 정보를 조정하는 조정값이 이후의 조정값에도 영향을 미쳐서 앞선정보가 뒷 정보에 영향을 미치는 큰 흐름을 만든다. 이것은 Sequence의 특성을 가지는 정보의 예측을 가능하게 한다. 연속적인 흐름이 특징인 데이터, 음성, 음악, 글 등을 활용하여 소리를 문자로 바꾸거나, 새로운 음악을 창조하기도 하고, 글을 번역하거나 어울리는 단어를 예측하기도 한다.
Word2vec(Word to Vector)
글이나 문자를 학습하려면 컴퓨터가 쉽게 연산할 수 있는 숫자로 표현해주면 좋은데 거기에 쓰이는 기술중에 하나가 Word2vec이라는 것이다. 말그대로 단어를 벡터 형식으로 변환하는 것이다. 글이나 문자를 학습한다는 말을 다시 말하면 각 문장, 단어들의 관계를 파악해서 어떤 의미를 지니고 있는지를 알아내는 작업이라고 이해하면 되겠다.
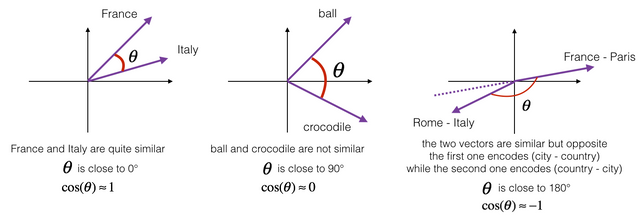
위 그림과 같이 프랑스와 이탈리아는 국가라는 공통점을 가지고 있어서 각도가 크지 않고, 공과 악어는 전혀 비슷하지 않기에 각도는 90도에 가깝다. 반면 로마-이탈리아의 짝과 프랑스와 파리의 짝은 비슷하긴하나 배열이 수도-국가, 국가-수도 순으로 반대여서 180도에 가까운 각을 나타낸다. 이와 같이 단어간의 연관성을 표현하는 것을 cosine similarity라고 하는데 그 내용은 이 글이 범위를 벗어나니 생략한다.
Debiasing word vectors
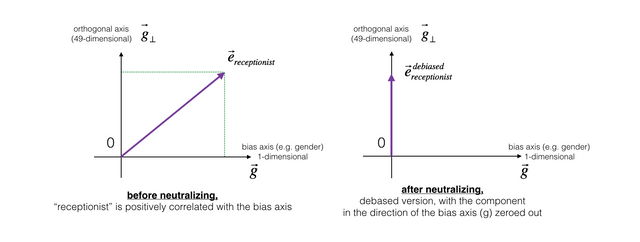
그림 1 : 출처 coursera 강의
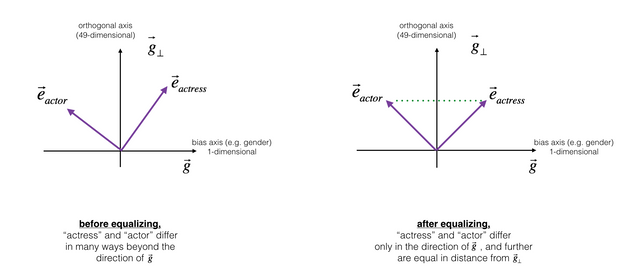
그림 2 : 출처 coursera 강의
차별, 편견이 사실상 있는 세상에 우리는 살고 있다. 그런 세상속에서 탄생한 글들도 물론 특정 부류에 대한 차별적인 인식이 담겨있다. 아무리 기계라지만 이런 세상 속에 살고 있는 우리가 쓴 글을 학습한다면 그 편견 또한 학습하게 되더라. 실제로 Sequence Models week2 의 과제를 할 때 사용한 벡터는 50-dimensional GloVe vectors 라는 것인데 이 벡터를 통해 학습하게 될 때 직업에 대한 남녀차별적인 요소가 반영되어 발란스가 맞질 않았다. 그런 bias를 조절하는 작업이 debiasing 이라는 것이다. 그림1에서 보는 것과 같이 접수원이라는 직업은 남녀모두가 할 수 있는 직업인데 그래프에서 보듯 성별을 구별하는 벡터의 크기가 존재하여 오른쪽 위로 향한다. 그것을 중성화 시키면 그림 1의 오른쪽 그림과 같이 된다. 그리고 그림 2에서 actor와 actress 또한 gender라는 요소에서 동일한 위치를 가지고 있지 않는데 그것을 조절하는 것을 equalize라고 한다. equalize의 결과는 그림2의 오른쪽과 같다.
얼마나 많을까
These debiasing algorithms are very helpful for reducing bias, but are not perfect and do not eliminate all traces of bias.
과제의 말미에 나왔던 한 줄인데, 정말 공감이 되었다. 편견과 고정관념을 깨는데 이 알고리즘이 매우 도움이 되지만 완벽하진않고 그리고 모든 편견을 제거할 수 없다는 말. 슬프면서도 안타까운 현실이다. 아이러니하게도 이성적이라 믿었던 기계도 인간이 발화해왔던 언어를 학습하면 편견을 갖게 되고 그걸 다시 인간이 제거해야하는 상황. 뭔가 신기하면서도 오묘하다.
Congratulations @allchani! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on the badge to view your Board of Honor.
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Do not miss the last post from @steemitboard!
Participate in the SteemitBoard World Cup Contest!
Collect World Cup badges and win free SBD
Support the Gold Sponsors of the contest: @good-karma and @lukestokes