[머신러닝] 학습 정확도 올리기 (Deep & Wide, Dropout)
Hidden Layer를 더 깊고, 넓게 구현하면 결과가 더 좋아질 것 같다. 그럼 바로 구현해보자.
...
# with Hidden layers
w1 = tf.get_variable("w1", shape=[784, 512],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.Variable(tf.random_normal([512]))
L1 = tf.nn.relu(tf.matmul(X, w1) + b1)
w2 = tf.get_variable("w2", shape=[512, 512],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.Variable(tf.random_normal([512]))
L2 = tf.nn.relu(tf.matmul(L1, w2) + b2)
w3 = tf.get_variable("w3", shape=[512, 512],
initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.Variable(tf.random_normal([512]))
L3 = tf.nn.relu(tf.matmul(L2, w3) + b3)
w4 = tf.get_variable("w4", shape=[512, 512],
initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.Variable(tf.random_normal([512]))
L4 = tf.nn.relu(tf.matmul(L3, w4) + b4)
w5 = tf.get_variable("w5", shape=[512, 10],
initializer=tf.contrib.layers.xavier_initializer())
b5 = tf.Variable(tf.random_normal([10]))
hypothesis = tf.matmul(L4, w5) + b5
...
기존에 3개였던 단계를 총 다섯 단계로 확장시키고 각 NN의 형태도 256에서 512로 넓게 만들었다. 어떤 결과가 나왔을까.
Epoch: 0001 Cost: 0.338800906
Epoch: 0002 Cost: 0.157855082
Epoch: 0003 Cost: 0.128125397
Epoch: 0004 Cost: 0.120872036
Epoch: 0005 Cost: 0.106940168
Epoch: 0006 Cost: 0.111734416
Epoch: 0007 Cost: 0.103941207
Epoch: 0008 Cost: 0.099025977
Epoch: 0009 Cost: 0.090530551
Epoch: 0010 Cost: 0.086762646
Epoch: 0011 Cost: 0.087698921
Epoch: 0012 Cost: 0.082656293
Epoch: 0013 Cost: 0.083550933
Epoch: 0014 Cost: 0.080989251
Epoch: 0015 Cost: 0.079926056
Learning Finished!
Accuracy: 0.9683
정확도가 높아지기는 했지만 확연하게 좋아지지는 않았다. cost는 오히려 기존 방식보다 높아졌다. 너무 복잡해졌기 때문이다. 변수가 너무나도 많아졌기에 모든 테스트 데이터를 사용할 경우 학습 효과가 떨어지는 현상이 발생했다. 그럼 어떤 방법이 있을까.
Dropout for MNIST
역발상이다. 테스트 데이터 중 일부, 그리고 파생되는 여러 node들 중 일부를 일부러 빼고서 학습을 진행한다. 너무 복잡한 것이 문제였으니 간단하게 만들어 보자는 역발상이다. 그리고 우리는 이 방법을 Dropout이라고 한다.
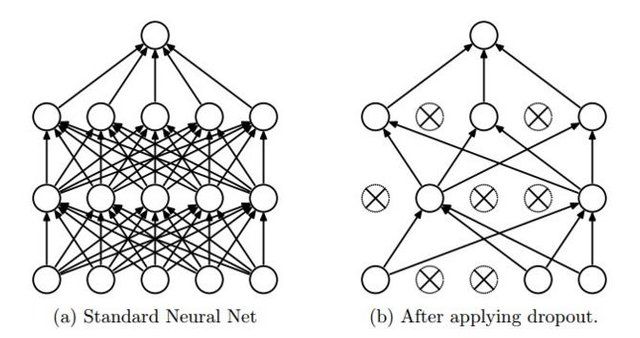
# dropout (keep_prob) rate 0.7 on training, but should be 1 for testing
keep_prob = tf.placeholder(tf.float32)
# with Hidden layers
W1 = tf.get_variable("W1", shape=[784, 512],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.Variable(tf.random_normal([512]))
L1 = tf.nn.relu(tf.matmul(X, W1) + b1)
L1 = tf.nn.dropout(L1, keep_prob=keep_prob)
W2 = tf.get_variable("W2", shape=[512, 512],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.Variable(tf.random_normal([512]))
L2 = tf.nn.relu(tf.matmul(L1, W2) + b2)
L2 = tf.nn.dropout(L2, keep_prob=keep_prob)
W3 = tf.get_variable("W3", shape=[512, 512],
initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.Variable(tf.random_normal([512]))
L3 = tf.nn.relu(tf.matmul(L2, W3) + b3)
L3 = tf.nn.dropout(L3, keep_prob=keep_prob)
W4 = tf.get_variable("W4", shape=[512, 512],
initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.Variable(tf.random_normal([512]))
L4 = tf.nn.relu(tf.matmul(L3, W4) + b4)
L4 = tf.nn.dropout(L4, keep_prob=keep_prob)
W5 = tf.get_variable("W5", shape=[512, 10],
initializer=tf.contrib.layers.xavier_initializer())
b5 = tf.Variable(tf.random_normal([10]))
hypothesis = tf.matmul(L4, W5) + b5
각 Layer마다 tf.nn.dropout이라는 새로운 코드를 추가함으로써 구현할 수 있다. 각 layer에 속한 node 중 몇개를 빼고서 학습을 진행하겠다는 의미다.
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=hypothesis, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(cost)
# initialize
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# parameters
training_epochs = 15
batch_size = 100
# training model
for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(mnist.train.num_examples / batch_size)
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
c, _ = sess.run([cost, optimizer], feed_dict={X: batch_xs, Y: batch_ys, keep_prob: 0.7})
avg_cost += c / total_batch
print('Epoch: ', '%04d' % (epoch + 1), 'Cost: ', '{:.9f}'.format(avg_cost))
print('Learning Finished!')
# Test model and check accuracy
correct_prediction = tf.equal(tf.argmax(hypothesis, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print('Accuracy: ', accuracy.eval(session=sess, feed_dict={X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1}))
그리고 test를 위한 feed_dict에는 70%만 학습에 사용하겠다는 코드를 추가하고, 최종적인 정확도를 계산할 때는 모든 데이터를 사용하겠다는 코드를 추가한다. 바로 결과를 살펴보자.
Epoch: 0001 Cost: 0.459188741
Epoch: 0002 Cost: 0.174127219
Epoch: 0003 Cost: 0.127372757
Epoch: 0004 Cost: 0.107246399
Epoch: 0005 Cost: 0.093983340
Epoch: 0006 Cost: 0.083125115
Epoch: 0007 Cost: 0.075034579
Epoch: 0008 Cost: 0.065235772
Epoch: 0009 Cost: 0.063138818
Epoch: 0010 Cost: 0.059596362
Epoch: 0011 Cost: 0.055033770
Epoch: 0012 Cost: 0.055033997
Epoch: 0013 Cost: 0.050529926
Epoch: 0014 Cost: 0.045394735
Epoch: 0015 Cost: 0.049365032
Learning Finished!
Accuracy: 0.9807
무려 98%의 정확도를 보여준다. cost 역시 작은 수치로 낮아졌다. 오히려 node 몇개를 빼고서 학습을 해보니 더 높은 정확도의 결과가 나왔다. 98%의 정확도면 엄청난 수치임을 직관적으로도 알 수 있다.
이렇게 Neural Network, Xavier Initialization, Deep & Wide NN, Dropout이라는 방법을 사용해서 기계 학습의 정확도를 더 높여봤다.
짱짱맨 호출에 출동했습니다!!
고팍스에서 MOC상장 에어드롭 이벤트를 진행합니다.
혜자스러운 고팍스!
https://steemit.com/kr/@gopaxkr/moc