TwitterのタイムラインからURLを抽出してRSSにしてFeedlyで読む
昨今の界隈ではLDRことLive Dwango Reader (ex. Livedoor Reader)がサービス終了したことが話題になった。
自分はRSS readerには Feedly Pro を長らく使っており、LDRを利用したことがないので特に感慨はない。
Feedly
Feedlyについては簡単に説明しておきたい。
Feedlyは使いやすくシンプルなRSSリーダであり、mobile appもある。PROにすると検索性が格段にアップするし、なによりポピュラーな記事をサマって今日見るべきカテゴリをまとめてくれるのが便利だ。
さらに j で記事移動、v で記事移動、gg でカテゴリ移動のように、vimのようなショートカット配置になっているのも嬉しい。LDRより軽量とは言えないかもしれないが、見やすいしデザインはモダンだ。自分は多く時間を費やすものには金を払う価値があると思っている。
電子ドラッグ
さて、話を戻そう
そもそも最近のインターネットは受動的な情報選択をする傾向にある。TwitterやFacebookなどのソーシャルメディアが跋扈し、情報はほぼSNSによって共有される。
RSSリーダを使っているのはもはや老害の域に達しており、RSSを吐いてくれるサイトも随分減ってしまった。嘆かわしいがこればかりは仕方がない。
相対的にTwitterを見る時間が長くなってしまった人も多いだろう。流速のあるタイムラインでは、情報の取捨選択を瞬間的に行う必要がある。情報は必ずしも有益なものとは限らない。というより、ほとんどのツイートはノイズのようなもので、一時的に脳を麻薬のように刺激し、時間を浪費する。Twitterは電子ドラッグといっても過言ではない。
砂金拾い
しかし中には素晴らしい情報も紛れている。自分が興味があり、ナレッジを蓄積し、知的好奇心を満たしてくれるような素敵な情報の共有が、玉石混交に確かに存在している。
Twitterとは、砂金集めのようなものだ。そして自分の場合その砂金は、短文よりもURLの先にある。
というわけで私は、大量の砂から砂金を分け、革袋にまとめることにした。つまりTwitterで流れる文章からURLを抜き出し、RSSにまとめ、いつも使っているFeedlyに落とし込む。
アーキテクチャはこのようになる。
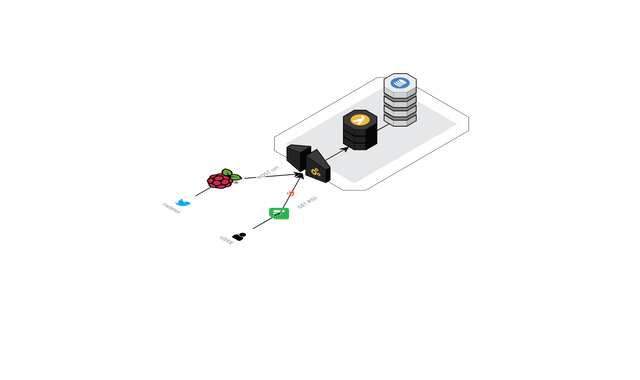
ポイントとしては
AWS APIGateway+Lambda+Dynamodbサーバレスで運用する。Twitter APIで stremに接続し、URLを抽出して投げるAPIGatewayはエンドポイントを用意し、GETではRSSを返し、POSTでデータを蓄積する- TwitterのClientに
Raspberry piを使う
AWS APIGateway + Lambda + Dynamodb サーバレスで運用する。
今回はサーバレスな構成にしてみた。
まずは出力側から考えたい。
Dynamodbのテーブルは以下のようになっている
url
timestamp
created_at
expired_at (TTL)
text
TTLを使用することで、dynamodbに無尽蔵に突っ込まれるデータを定期的に消去する。ここでは登録から2時間後にしている。Feedlyはおおよそ30分間隔、速いと10分でRSSを取得しに来る。取り込まれてしまえばRSSには情報は残っていなくても良い。よって、2時間も消費期限が持てば充分であり、それ以降は必要ないので消してしまう。
Dynamodbはデータの蓄積にも金を取るし、バッチで一個一個消すのも面倒だ。TTLを使えば登録時に指定した時間に消えてくれる。
テーブルは常に表示されるべきRSSのデータのみで完結する。これによってLambdaでは単にlambda_handlerにGETが来たらテーブルをscanしてjsonにくるむだけ良い。
def respond(err, res=None):
return {
'statusCode': '400' if err else '200',
'body': '{}' if err or not res else json.dumps(res,cls=DecimalEncoder),
'headers': {
'Content-Type': 'application/json',
},
}
def lambda_handler(event, context):
operations = {
'DELETE': lambda table, x: table.delete_item(**x),
'GET': lambda table, x: table.scan(),
'POST': lambda table, x: table.put_item(Item=x),
'PUT': lambda table, x: table.update_item(**x),
}
operation = event['httpMethod']
if operation in operations:
payload = None if operation == 'GET' else json.loads(event['body'])
return respond(None, operations[operation](table, payload))
else:
return respond(ValueError('Unsupported method "{}"'.format(operation)))
APIGatewayを使って、エンドポイントを定義する。
GETの統合レスポンスに application/rss+xml を指定し、本分マッピングテンプレートで以下のように登録する。
これによってLambda側で処理されたJSONをRSSにマッピングできる。Lambdaはあくまでデータ処理だけを考えればよく、APIGatewayが最終出荷物をコントロールしている。
#set($inputRoot = $util.parseJson($input.path('$.body')))
<?xml version='1.0' encoding='UTF-8'?>
<rss version='2.0'>
<channel>
<title>yurfuwa's twitter</title>
<link>http://twitter.com/yurfuwa</link>
<description>extract timeline-share-links</description>
#foreach($item in $inputRoot.Items)
<item>
<title>$item.text</title>
<link>$item.url</link>
<description>$item.text</description>
<pubDate>$item.created_at</pubDate>
</item>
#end
</channel>
</rss>
これで、AWSから発行されたURLのエンドポイントを叩けば、dynamodbに登録されているデータのRSSが出力されるようになった。個人で利用するだけなので、ドメインを取得する必要もない。
Raspberry piでTwitterのクライアントを作る
自分は自宅サーバーをとうの昔に捨ててしまった。その代わりにRaspberry piを使っている。EC2も考えられるが、AWSは富豪的だ。たかが個人のタイムライン監視に、EC2でお金を払うのは辛い。個人用のSlack botなんかも、Raspberry piでやっている。
ここでも、特に難しいことはしないが、Lambdaではpython3を使ったがClientはnodeにしている。
Twitterのストリームに接続したら、expanded_urlが含まれているか見る。含まれていたら、指定のURLを除外して、整形して、APIGatewayで作ったエンドポイントに POST で投げる。
先程のLambdaはすでにPOSTで来たらDynamodbのテーブルにput_itemするようになっているから、これで完成。
var twitter = require('twitter');
var client = new twitter( {...})
var request = new require('request');
const urlRegex = require('url-regex');
var stream = client.stream('user', {with : 'followings'});
stream.on('data', function(event) {
var media = event.entities.media;
var url = event.entities.urls[0];
if(event.lang == 'ja' && url && url.expanded_url && !(
/instagram.com|twitter.com|twitpic.com|ift.tt|swarmapp.com|nico.ms|pixiv.net|bit.ly|this.kiji.is|nhknews.jp|fb.me|tenki.jp|j.mp|melonbooks|ask.fm/.test(url.expanded_url)
)){
var options = {
uri: process.env.NODE_TWEET_SHARE_ENDPOINT,
method: 'POST',
json: {
"url": url.expanded_url,
"text": event.text.replace(/RT \@[A-z|a-z|0-9|\-|\_]+\:\ /,'').replace(urlRegex(),''),
"created_at": event.created_at,
"timestamp" : parseInt( Date.now() / 1000 ),
"expired_at" : parseInt( Date.now() / 1000 ) + 7200
}
};
request(options, function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body)
}
});
}
});
運用費
さて、AWSのサービスを使っているので、一月のお値段が気になる。

このような感じ。EC2ではこうはいかない。Dynamodbは無料枠の範囲内で収まる。
TTL設定しないと爆死するし、Twitterのフォローが1万人とか監視いる人は知らん。
Feedlyで表示してみる
実際運用してみると素晴らしく、良い。
Feedlyは勝手に話題っぽいURLを優先してくれるので、無尽蔵にURLを突っ込んでも見るべきものから表示される。
Twitterを漠然と眺めている時間は減る上に、RSSは10分間隔で更新されるので速報系のニュースにも強い。
最終的にはディープラーニングでTwitterからのソースをクラスタリングして、カテゴリごとにRSSを吐くとなお良さそう。教師データは既にあるカテゴライズされたRSSのソースを使えばいいし。
Great post, I has upvote your post, support me please, thanks