[EN] Bufferoverflow - Theoretical part
In a buffer overflow or buffer overflow, data that is often read in as user input is written to a memory area that was not intended for this purpose. As larger amounts of data are read in than actually reserved for this by the developer, this "overflows" and is written to the corresponding next area.
Source
{kind=link}
Especially programming languages that are mostly compiled directly into machine code are susceptible to programming errors (e.g. C/C++ etc.). For these languages, the developer is responsible for checking the memory areas. This is one of the reasons why existing algorithms (which have proven themselves) should not be redeveloped.
Java or Pyhton and other high-level languages use operating system control structures that can detect and prevent such memory overflows.
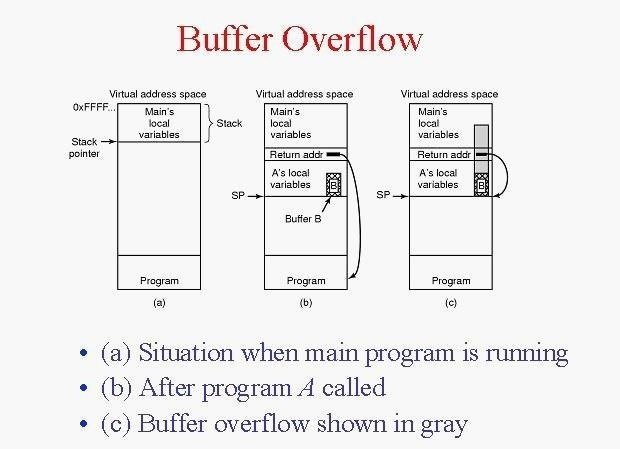
In principle, a distinction is made between stack and heap overflows. This means dynamically allocated and static memory.
In this minimal example I would like to limit myself to a stack overflow.
void stack_overflow(const char *foo)
{
char bar[7];
strcpy(bar, foo);
}
If the function is now called:
stack_overflow("abcdefghij")
This results in a buffer overflow, since not enough memory has been allocated for bar[]. The function strcpy(), which in this case copies our input into bar[], is an example of a function that can often lead to overflows if the limits are not observed.
Ask the experts: Why would calling the method with "steemit" as a parameter also lead to a buffer overflow?
Depending on the program, it may crash and behave in an uncontrolled manner.
If a buffer overflow is intentionally generated, usually with the intention of executing code on the target system. The execution privileges correspond to those of the affected process. This can be achieved by storing jump addresses in memory that refer to other memory areas. For example, a return address can execute a function.

I will soon write a detailed article with an example.
Thank you for reading!