Ha salido stable diffusion v 2.0 y estoy muy decepcionado. / Stable diffusion v 2.0 is out and I am very disappointed.
Hola amigos, ayer recién se anunció la salida de stable diffusion v 2.0 y he de decir que estaba muy emocionado ya que stability ai había dicho desde hace un tiempo que la versión 2 iba a ser increible. De hecho en su página vemos algunas de las generaciones que han hecho y si son interesantes.




Como se puede observar esta nueva versión es muy capaz de hacer cosas bastante realistas, de hecho yo mismo lo he probado y hecho algunas imágenes con prompts ultra sencillos a ver que pasaba y aquí están los resultados.
a beatiful cat




a honey bee




En las generaciones que he hecho podemos observar que la calidad de las imágenes ha aumentado significativamente y aunque en algunas hay coherencia en otras bueno. Así que me aventuré a probar con prompts más complicados y he tratado de recrear una vieja generación de unos perros con audífonos y el resulta es muy muy decepcionante, tengo que aclarar que he podido solo guarde 2 imágenes de las 4 porque s eme trabó la página no me dejó guardar el resto y como es un modelo nuevo en huggingface es muy difícil generar imágenes debido a la saturación.
A dog wearing headphones, 8k octane beautifully detailed render, post-processing, extremely hyperdetailed, intricate, epic composition, grim yet sparkling atmosphere, cinematic lighting + masterpiece, trending on artstation, very detailed, vibrant colors, Art Nouveau, masterpiece, full shot, full body, science fiction background


Y bueno a diferencia de su predecesor no hay comparación.




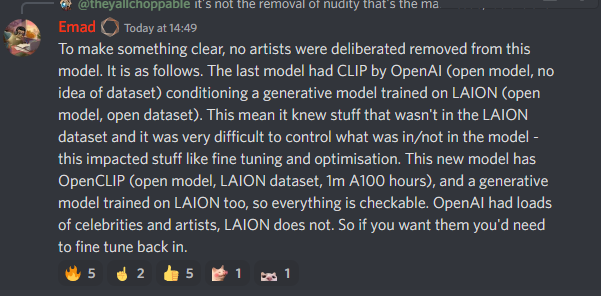
Pero ¿por que pasa esto? Bueno pues resulta que en esta nueva versión han usado un data set de 5 mil millones (LAION-5B) de imágenes cuidadosamente elegidas donde han eliminado a famosos, artistas y contenido NSFW, todo esto con la intención de no meterse en problemas legales. Sin embargo esto deja terriblemente limitado al modelo y aunque si que es posible que en un futuro se pueda entrenar el modelo para hacer cosas que ya hacíamos con el modelo anterior si deja un sabor amargo y se siente como una especie de censura.
En fin hasta aquí la actualización del día de hoy, en cuanto el modelo se libere al menos en dream studio y haya menos congestión traeré más experimentos porque por ahora es muy difícil, hasta un próximo blog.
English
Hi friends, yesterday was just announced the release of stable diffusion v 2.0 and I must say that I was very excited because stability ai had been saying for a while that version 2 was going to be amazing. In fact on their page we see some of the generations they have done and yes they are interesting.
As you can see this new version is very capable of doing quite realistic things, in fact I have tested it myself and made some images with ultra simple prompts to see what happened and here are the results.
a beatiful cat
a honey bee
In the generations I have done we can see that the quality of the images has increased significantly and although in some there is consistency in others well. So I ventured to try with more complicated prompts and I have tried to recreate an old generation of a dog wearing headphones and the result is very very disappointing, I have to clarify that I could only save 2 images of the 4 because the page got stuck and did not let me save the rest and as it is a new model in huggingfacee is very difficult to generate images due to saturation.
A dog wearing headphones, 8k octane beautifully detailed render, post-processing, extremely hyperdetailed, intricate, epic composition, grim yet sparkling atmosphere, cinematic lighting + masterpiece, trending on artstation, very detailed, vibrant colors, Art Nouveau, masterpiece, full shot, full body, science fiction background.
And well unlike its predecessor there is no comparison.
But why does this happen? Well it turns out that in this new version they have used a 5 billion data set (LAION-5B) of carefully chosen images where they have eliminated celebrities, artists and NSFW content, all this with the intention of not getting into legal trouble. However, this leaves the model terribly limited and although it is possible that in the future the model can be trained to do things that we already did with the previous model, it leaves a bitter taste and feels like a kind of censorship.
Anyway so far today's update, as soon as the model is released at least in dream studio and there is less congestion I will bring more experiments because for now it is very difficult, until a next blog.

Imagen hecha por @fclore22