Steps to restore a Hivemind database snapshot
I distribute daily Hivemind database snapshots. This is a quick tutorial to restore that database into a fresh new server.
I have completed these steps on a fresh Digitalocean droplet (8vcpu, 32gb ram) running Ubuntu 16.04. And all the process took 4 hours.
Installing PostgreSQL (10.6)
$ apt-get update
$ wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
$ sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ $(lsb_release -sc)-pgdg main" > /etc/apt/sources.list.d/PostgreSQL.list'
$ apt-get update
$ apt-get install postgresql-10
Important note: This dump is only compatible with PostgreSQL 10.6**
Creating the database and user
$ su - postgres
$ createuser --interactive --pwprompt
Enter name of role to add: hive
Enter password for new role:
Enter it again:
Shall the new role be a superuser? (y/n) y
$ psql
$ create database hive;
$ \q
Note: Make sure you remember the role(user) name and password and set the user as hive.
Download the dump
$ wget -c http://hivemind.emrebeyler.me/dumps/hive_latest.sql.gz
Wait until it finishes. It should take around 10-15 mins. (Make sure you check the state.txt. If it says, backup in progress, you need to wait.)
Decompress the file
$ apt-get install pigz
$ apt-get install pv
$ pv hive_latest.sql.gz | pigz -d -p 8 > hive_latest.sql
This will decompress the file with 8 threads and gives a nice progress bar.
It should take 15-20 minutes. You can choose thread count with the -p parameter. I have aligned it with core count.
Restore the database
$ vim /etc/postgresql/10/main/pg_hba.conf
Find that line:
local all all peer
Replace peer with md5, then do a restart:
$ service postgresql restart
Import the database:
$psql -U <username> <database_name> -f hive_latest.sql
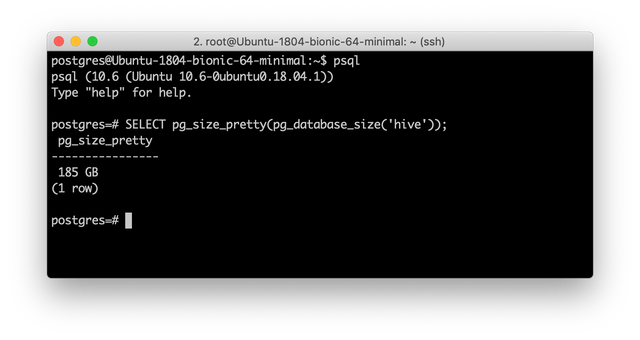
Watching the progress:
$ su - postgres
$ psql
SELECT pg_size_pretty(pg_database_size('hive'));
This will show the database size of hive. It should be around 180-200 GB when the import is done.
Install Python3.6 & Hivemind
These steps are required for manual installation of Hivemind. If you use docker installation, you can skip.
$ add-apt-repository ppa:jonathonf/python-3.6
$ apt-get update
$ apt-get install python3.6 python3.6-dev virtualenv build-essential
$ virtualenv -p python3.6 hivemind-env
$ source hivemind-env/bin/activate
$ git clone https://github.com/steemit/hivemind.git
$ cd hivemind
$ pip install -e .
Congrats! Hive is installed.
Sync process
(Make sure you activated the virtual environment)
$ hive sync --database-url postgresql://hive:hive@localhost:5432/hive
This will sync the missing blocks and catch-up with the block production fast. It's recommended to run this with a process manager (like Supervisor) to make sure the process is always up and running.
Server process
(Make sure you activated the virtual environment)
$ hive server --database-url postgresql://hive:hive@localhost:5432/hive
Notes
This tutorial is opinionated on some steps and gives a simple start to setup a Hivemind. For the best results, always follow the official repository for the instructions.
For example, the recommended way to install Hivemind is the Docker way. I patch and hack things on my Hivemind setup, so I prefer a manual install. Also, it's always preffered to execute apps in a normal user instead of root. I skipped this to keep the tutorial simple.
Also, if you don't have SSD in your setup, restoring process may take more time. Some users reported long waiting times on decompressing, importing, etc.
Troubleshooting
If you encounter any issues while trying this, you can join #hivemind channel at Steemdevs discord and ask for help.
Vote for me as a witness
I do my best to support the blockchain with my skills. If you like what I do, consider casting a vote on via Steemconnect or on steemit.com.
ǝɹǝɥ sɐʍ ɹoʇɐɹnƆ pɐW ǝɥ┴
.uoy knahT
I've been looking for a clear and up to date description of how to set up Hivemind. Thanks for this.
Is is possible to later add a steamd node to this setup and sync with it to create a complete full node? It would seem that this is a faster way to setup and recover from an outage as replay of steamd and above process could occur concurrently on seperate machines.
yes, it decreases the initial sync time from 1 week to 4 hours. :)
This is very important because shorter times to get back online after an outage mean that lower reliability can be tolerated. This all helps with decentralisation by allowing full nodes and parts thereof to be run on (high end) commodity machines.
Thanks. I voted for you as witness.
Its taking 12+ hours to download the Hivemind snapshot. I have very fast internet at my end but download speed is ~500kb/s. Do you know what the problem is. This somewhat defeats the purpose.
Hey,
Sorry to hear that. It takes around 10 mins to download on my end. (Same figure reported from the people using the dump.)
However, this is server/datacenter level internet. There is no throttling in the server side, so the download speed is related to your maximum speed and the location. (Server is located at Helsinki/EU.)
I'm now using Axel rather than wget to download and getting 2.5Mb/s downloads rather than 0.5Mb/s.
Thanks!! Did the whole process on a clean machine. It worked smooth and I am now synced to hive!!
On the clean machine it took me around 3-4 hours. This is what I was hoping for =)
im beginner i learn now python first tutorial after i finish i will read this post again
I have voted for you as a witness now. You have been showing hardworking on steemit to move it forward. Keep growing
Thank you!
just upvoted and left a reply on your post. follow me guys so i will show you flames at upvoting and replying
thank you for this post. your post is super interesting and attractive, i suggest you continue posting such nice posts
thank you
So the crypto universe is moving forward.
I bet you ✌
This post has been included in the latest edition of SoS Daily News - a digest of all you need to know about the State of Steem.
Editor of the The State of Steem SoS Daily News.
Promoter of The State of Steem SoS Weekly Forums.
Editor of the weekly listing of steem radio shows, podcasts & social broadcasts.
Founder of the A Dollar A Day charitable giving project.
A very informative article. Thank you for this information
Posted using Partiko Android