[재무계산] IBM과 S&P 500 간의 공분산, 상관계수 계산 및 시계열 분석
<문제>
1. IBM과 SP 500 INDEX 의 주식 수익률 데이터를 구합니다. (샘플 기간 2012-01-01 - 2016-12-31)
2. 총 샘플 기간 내 둘의 공분산 행렬을 구하세요 (행렬의 대각항에서 벗어나 있는 두 값은 같으므로 대칭 행렬입니다 - 왜 그럴까요?)
3. 21일 거래일 기준 공분산을 구하여 하루씩 윈도우를 움직인 후 총 샘플기간에 대한 시계열 자료를 구합니다. (주의: 행렬의 시계열 자료이므로 샘플 기간 중 맨 앞의 20일 제외한 총 날수에 해당하는 큰 행렬이 만들어질 것입니다)
4. 이 자료를 바탕으로 IBM과 SP500 인덱스의 correlation이 샘플 기간 중 어떻게 움직였는지 살펴보세요.
5. 샘플 기간 내 4번의 correlation과 SP 500 인덱스의 주가 간의 평균적인 관계는 어떻게 되는지 하나의 수치로 제시하세요.
<코드>
!pip install yfinance # yfinance 설치#문제 1
import yfinance as yf
import numpy as np
import pandas as pd
import datetime
IBM = yf.download("IBM", '2012-01-01', '2016-12-31') #IBM 데이터 다운로드
SP500 = yf.download("^GSPC", '2012-01-01', '2016-12-31') #SP500 데이터 다운로드
print(IBM) #확인
print(SP500) # 확인
IBM = IBM.loc[:, ["Adj Close"]] # Adj Close 열만 뽑아주기
IBM.rename(columns = {'Adj Close' : 'IBM'}, inplace = True) #열 이름 다듬기
SP500 = SP500.loc[:, ["Adj Close"]]# Adj Close 열만 뽑아주기
SP500.rename(columns = {'Adj Close' : 'SP500'}, inplace = True) #열 이름 다듬기
IBM_logrtn = np.log(IBM.IBM/IBM.IBM.shift(1)) #IBM log return 구하기
SP500_logrtn = np.log(SP500.SP500/SP500.SP500.shift(1)) #SP500 log return 구하기
IBM_logrtn = IBM_logrtn.dropna(axis = 0) #결측치 제거
SP500_logrtn = SP500_logrtn.dropna(axis = 0) #결측치 제거
total_dataframe = pd.DataFrame(IBM_logrtn) #total dataframe 생성
total_dataframe = total_dataframe.join(SP500_logrtn, how='right') #total dataframe 자료 추가
total_dataframe = total_dataframe.dropna(axis = 0) #결측치 제거
length = len(total_dataframe) #dataframe 열 개수 구해주기
print(total_dataframe) #확인
date_df = pd.DataFrame(total_dataframe.index) #날짜 데이터 프레임
date_df #확인#문제 2
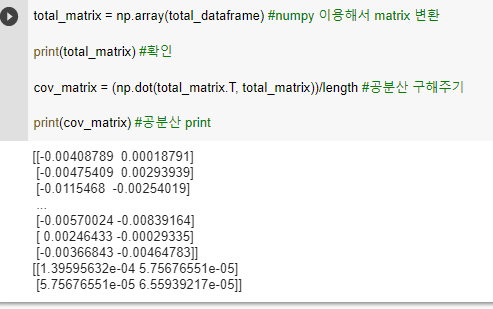
total_matrix = np.array(total_dataframe) #numpy 이용해서 matrix 변환
print(total_matrix) #확인
cov_matrix = (np.dot(total_matrix.T, total_matrix))/length #공분산 구해주기
print(cov_matrix) #공분산 print#문제 3
import matplotlib.pyplot as plt
n = length - 21 # n은 total dataframe의 -21
cov = [] # 공분산 리스트 생성
a = 0 # 인덱싱을 위한 a=0 지정
for i in range(n): # 반복문
total_21_dataframe = total_dataframe.iloc[a:a+21] #total_21_dataframe is indexing a ~ a+21 (21일치)
total_21_matrix = np.array(total_21_dataframe) # matrix 변환
cov_21 = np.cov(total_21_matrix[:, 0], total_21_matrix[:, 1]) # cov_21은 공분산 행렬
num_cov_21 = cov_21[0][1] #공분산 값
a = a+1 # a+=1
cov.append(num_cov_21) # 한번의 루프에서 구해진 cov값을 cov 리스트에 추가
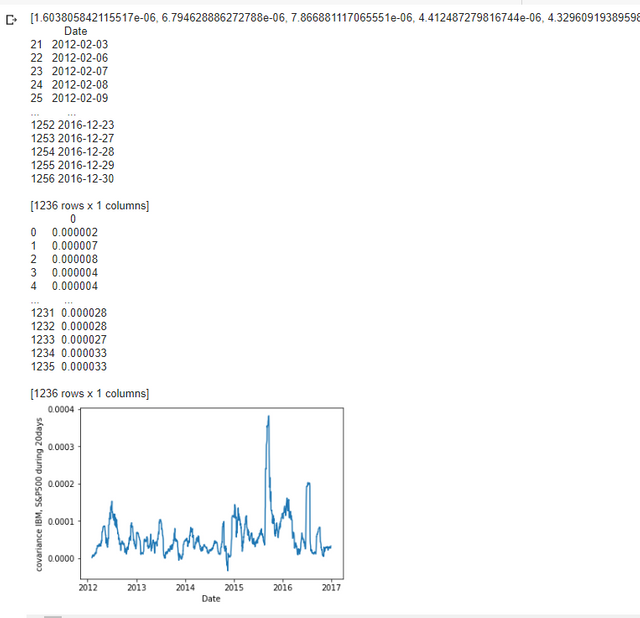
print(cov) #확인
date_df = date_df[21:] #date 21일부터
print(date_df) #확인
cov = pd.DataFrame(cov) #공분산 데이터프레임
print(cov) #확인
cov.index = date_df #date 인덱스 추가
plt.plot(cov) #plot으로 시계열 데이터 생성
plt.ylabel('covariance IBM, S&P500 during 20days') #y값의 뜻
plt.xlabel('Date') #x값의 뜻
plt.show() #보여줘#문제 4
#상관계수 = Cov/(표준편차의 곱)
m = length - 21 # n은 total dataframe의 -21
corr = [] # 상관계수 리스트 생성
b = 0 # 인덱싱을 위한 a=0 지정
for i in range(m): # 반복문
total_21_dataframe = total_dataframe.iloc[b:b+21] #total_21_dataframe is indexing a ~ a+21 (21일치)
total_21_matrix = np.array(total_21_dataframe) # matrix 변환
cov_21 = np.cov(total_21_matrix[:, 0], total_21_matrix[:, 1]) # cov_21은 공분산 행렬
num_cov_21 = cov_21[0][1] #공분산 값
ibm_std = np.std(total_21_matrix[:, 0]) #ibm 표준편차 구해줘
sp500_std = np.std(total_21_matrix[:, 1]) #sp500 표준편차 구해줘
num_corr = num_cov_21/(ibm_std * sp500_std) # 상관계수 구하기!!
corr.append(num_corr) #corr에 num_corr 추가해주기
b+=1 #b+=1
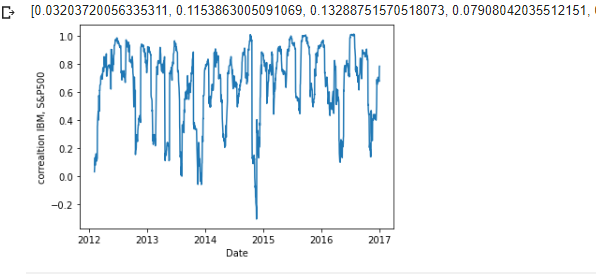
print(corr) #확인
corr_df = pd.DataFrame(corr) #corr 데이터프레임 생성
corr_df.index = date_df # 인덱스 추가하기
plt.plot(corr_df) #corr_df 시계열 데이터 생성
plt.ylabel('correaltion IBM, S&P500') # y값의 뜻
plt.xlabel('Date') #x값의 뜻
plt.show() #보여줘#문제 5
IBM_list = list(IBM.IBM) #IBM 주가 리스트 생성
IBM_list = IBM_list[22:] # IBM 주가 데이터 맞춰주기
print(type(corr)) # 타입 확인
print(type(IBM_list)) #타입 확인
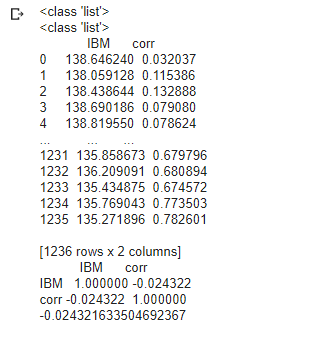
result_df = pd.DataFrame({"IBM" : IBM_list, "corr" : corr}) # IBM과 위에서 구한 corr 데이터 프레임 생성
print(result_df) # 확인
result=result_df.corr(method = 'pearson') # 둘의 상관계수 행렬 생성
print(result) #확인
result.iloc[0, 1] #상관계수 구해주기
<결과>

결과 해석
IBM과 S&P 500의 간의 20일간 log return 상관계수는 대체로 0~1의 값을 지녔다
-> 양의 상관관계이다 = log return의 방향이 대체로 비슷하다
IBM과 상관계수간의 상관관계 값은 -0.024
-> 사실 이걸 제대로 이해 못하겠다... 어떤 의미인지 찾아봐야 할듯
로그 수익률을 쓰는 이유
-> 한 시점 전의 자산 가격이 최종 수익률에 영향을 미치지 않기 때문
-> 매클로린 급수에 의해 일반 수익률과 근사하다