Programming Diary #19: Follower network strength and preparing for Open Source publication
Summary
Once again, I didn't have much progress to report at the two-week mark, so I skipped that update and it has been about a month since Programming Diary #18: WhaleAlert inspired activity notices. For this interval, my activities mostly shifted from the Steemometer programming to alignment of voting weights with the strength of an author's follower network. I also made some progress towards getting the Steemometer ready to publish as open source.
Background
Here are the two goals that I set for myself in Programming Diary #18: WhaleAlert inspired activity notices.
- Implement algorithm changes in automated voting so that voting percentages start incorporating information about an author's follower network;
- Start preparing the existing Steemometer code for Open Source release by adding comments, removing clutter, and trying to make sure that it doesn't leak details about my development environment.
I expect to revisit the first goal many times in order to continually improve the voting alignment between blockchain content and the human attention that the content receives. I also expect the second goal to take more than 2 weeks of effort.
I made progress on both goals during the last couple of weeks, but as expected, I have work remaining before I can call either one complete.
Progress
Aligning voting weight with follower network strength
For the first goal, aligning voting weight in my autovoter with the strength of an author's follower network, here's a visualization of the rules that I implemented. (each line is based on the number of followers that an author has)
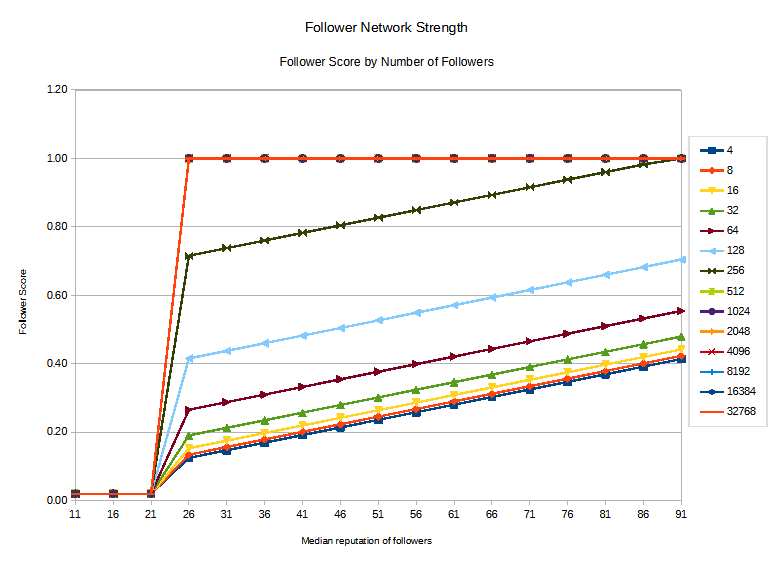
Here are some characteristics of the "Follower Score" as implemented:
- If an author's follower network has a median follower reputation of 25 or less, it doesn't matter how many followers they have. The follower score is 0.01 (to avoid multiplying by 0).
- If an author has more than about 375 followers, and the median reputation is above 25, then the median reputation doesn't matter. They get the maximum follower score, which is 1.
- In between 1 follower and 375 followers, the follower strength increases from 0.01 to 1 with the number of followers and with the median follower reputation.
- To get the follower score above 0.5, the author must have somewhere between 64 and 128 followers.
I don't really like the shape of these curves, but it's a first pass. I ran into trouble with API responsiveness for a few days, so I'm still observing the impact of the changes.
As previously mentioned, once I find a curve that I'm happy with, I'll use that to inform the vote suggestions in the Steemometer tool.
Preparing Steemometer for Open Source publication
In order to do this, I am leaning about javadoc, and how it is implemented in Netbeans. I also learned about the SLOC maven plugin, so that I can contextualize my progress through the various Java class files. At present, it seems that my project currently contains about 2,790 lines of code.
| Package Name | File Name | Type | Blank | JavaDoc | Comment | Code | Total |
|---|---|---|---|---|---|---|---|
| module-info.java | src | 0 | 0 | 2 | 9 | 11 | |
| steemometer | ApiServer.java | src | 7 | 29 | 1 | 52 | 89 |
| steemometer | AuthorInfo.java | src | 44 | 61 | 22 | 133 | 260 |
| steemometer | CountOps.java | src | 34 | 41 | 34 | 227 | 336 |
| steemometer | MedianCalculator.java | src | 20 | 39 | 1 | 108 | 168 |
| steemometer | PostDisplayManager.java | src | 15 | 43 | 3 | 91 | 152 |
| steemometer | PostInfo.java | src | 42 | 122 | 8 | 227 | 399 |
| steemometer | StartPoll.java | src | 6 | 10 | 0 | 21 | 37 |
| steemometer | SteemData.java | src | 45 | 112 | 11 | 192 | 360 |
| steemometer | SteemPriceFetcher.java | src | 21 | 9 | 12 | 65 | 107 |
| steemometer | Steemometer.java | src | 190 | 12 | 121 | 1078 | 1401 |
| steemometer | SteemometerConfig.java | src | 14 | 41 | 0 | 50 | 105 |
| steemometer | SteemometerController.java | src | 5 | 10 | 1 | 23 | 39 |
| steemometer | SystemInfo.java | src | 4 | 12 | 0 | 9 | 25 |
| steemometer | TransactionNotifier.java | src | 30 | 60 | 14 | 217 | 321 |
| steemometer | UrlValidator.java | src | 16 | 44 | 1 | 68 | 129 |
| steemometer | VoteSuggestor.java | src | 5 | 17 | 0 | 15 | 37 |
| steemometer | XferMemoInfo.java | src | 23 | 93 | 1 | 126 | 243 |
| steemometer | XferMemoManager.java | src | 15 | 42 | 3 | 79 | 139 |
| 2 package(s) | 19 file(s) | java | 536 | 797 | 235 | 2790 | 4358 |
I learned how to use Netbeans to insert javadoc comments in all files, and I have reviewed the auto-inserted comments in the ApiServer.java file and the AuthorInfo.java file. I also went through all files and removed auto-generated comments that I thought were unnecessary.
Next up
Since my goals from the last cycle are still in progress, I plan to continue them for the next two weeks.
- Experimentation and improvement towards aligning voting weights with follower network strength.
- Getting Steemometer ready for Open Source publication.
As with last time, I don't really expect to finish either goal in the next two weeks.
Reflections
I want to follow-up on three topics from the Reflections section in Programming Diary #18: WhaleAlert inspired activity notices, and also add a new topic:
SBD print threshold / Steem inflation
The Steem price has now remained above the SBD print threshold for a little more than a month, so I have continued to keep an eye on Steem inflation. The first quarter was deflationary, but the first week of the second quarter reversed that trend. It will be interesting to see what happens in coming weeks since the BTC halving is expected on April 20.
Blockchain activity
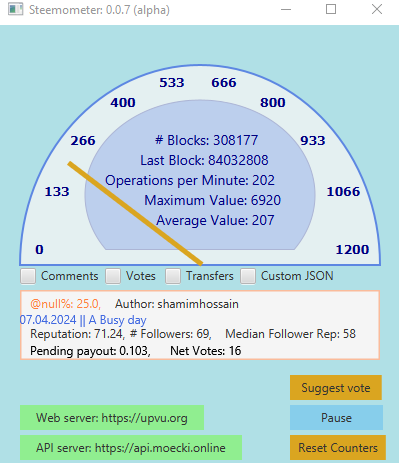
In the last post, I wondered if SBD printing would lead to an increase in blockchain activity. It appears that the answer is "yes". In that post, the blockchain activity was reported at about 185 operations per minute. Now it's up to about 207.
Steemit.com stability/API performance
The overall stability problems that were mentioned in Programming Diary #18, have been solved. API reliability still has occasional problems, however. As noted above, my autovoter fell behind by about two days for some reason. I didn't notice it for a while, so I have no idea what the cause might have been. Also, simple python activities are often still blocked by the rate limits that were implemented last fall.
Witnesses
Here's the new topic for today's post. I have some thoughts about witnesses in the Steem environment:
- The top-20 witnesses have more to do than just validate blocks. The task of setting the price feed seems to be in good order, but they also need to consider the SBD interest parameter. I've discussed this topic here, here, and here. It would be nice if the witnesses would weigh in with their perspectives. Is there some reason why 0 is the optimal percentage?
- I could be wrong, but I think there's at least one top-20 witness who has disengaged considerably from the ecosystem. It might be good for people to reevaluate their votes.
- Since I don't control enough stake to influence the ranks of the top-20, I often focus my witness voting further down in the ranks. There are a number of disabled witnesses who are still in front of real witnesses, so - again - it might be good for people to reevaluate their votes. For those of us who have smaller stakes, moving votes that aren't needed from the top-20 section to higher ranked witnesses might have a substantial impact towards downranking the disabled witnesses.
- I've mentioned it before, but IMO, @moecki should be ranked much higher than #58. It seems to me that he provides more to the ecosystem than several of the witnesses in top-20 positions, and many of the others, too. I hope readers will consider allocating a vote towards his witness.
Conclusion
If slow and steady wins the race, then I'm on track for a big programming win. 😉 It seems like publishing the toy Steemometer program as Open Source is in sight now, even if it's still not imminent.
My purpose for breaking out of iterating new features for it was to force myself to develop some other skills that will be useful for eventually implementing a peer to peer social media client. Based on the experiences learning about javadoc and SLOC, that seems to be proceeding as hoped.
I hope to see you in two weeks with Programming Diary #20!
Thank you for your time and attention.
As a general rule, I up-vote comments that demonstrate "proof of reading".

Steve Palmer is an IT professional with three decades of professional experience in data communications and information systems. He holds a bachelor's degree in mathematics, a master's degree in computer science, and a master's degree in information systems and technology management. He has been awarded 3 US patents.


Pixabay license, source
Reminder
Visit the /promoted page and #burnsteem25 to support the inflation-fighters who are helping to enable decentralized regulation of Steem token supply growth.
I wonder if I have any painful suggestions to make?
Thinking about the Follower count to assist voting percentages, I wonder how hard (or necessary) it would be to check "Follower Activeness" - not necessarily their "Last Update" but perhaps checking that their STEEM Power is above a minimum threshold for acceptance. For example, older users might have a "higher reputation" bias from inactive users. As I type this, I'm asking myself "so what?" and perhaps the answer is that you're checking if the user's attracting new followers and therefore still posting good quality content. Although high power users naturally attract new followers irrespective of how good their content is.
Can you tell I'm thinking out loud.
!00% agree. Not only his activity, but his willingness to put himself in the community for all to see. I know some witnesses working behind the scenes that haven't talked about what they're doing (not that I've seen anyway).
I've thought about that, too (great minds think alike? 😉). Also median SP of followers. I think both values might be useful, but the only ways I know to implement them would be to query each follower account separately at the time of voting, or to store it in my own database and update it regularly. Both implementations require more compute than I want to put into it right now.
TEAM 1
Congratulations! This comment has been upvoted through steemcurator04. We support quality posts , good comments anywhere and any tags.Thanks @o1eh 🙂
I just stumbled across this and thought of you and @moecki - https://peakd.com/steem/@steemitblog/introducing-the-steem-recommendation-page
I wonder why it was removed - presumably it required too much processing power.
Have you ever scrolled to the bottom of steemitblog on steemit.com? It ends prematurely which I found interesting 🫢
Nice :-)
I recently saw something in the Hivemind code that amazed me. I can't remember what it was right away, but it must have once been available or intended as a function.
Perhaps you can actually still find remnants of the implementation of the recommendations at that time. In any case, I think that this was implemented at Hivemind level.
Strange. On steemitdev.com it doesn't end prematurely...
I think hivemind came along later. I ran a couple quick searches of steemit's github space, but didn't find anything. I didn't spend a lot of time at it, though.
You are right. Thanks for the link. I really need to have a look at all the old posts from steemitblog. Quite a lot was explained there.
I found two commits:
https://github.com/steemit/steem/commit/a01b04ed439681528c61b3b7e318092c8b98067f
https://github.com/steemit/steem/commit/f3877959f55d30e1ba2815eeb437dabc0e3d70fd
These were probably the first implementations. I don't yet know whether it was changed before it was removed again.
Whilst looking for some documentation for steemit.com, I stumbled across a few interesting discussions that were prompted by the dev team. I can't remember what any of them were either 😆 but I did think about digging some of them out. One of them was a page view counter and there's a lot of condenser code scattered about for that.
This would be a great favour to some (well known) users :-)
However, there are a few obstacles here:
Will you accept the challenge? ;-D
Ha ha - no chance! I'm grateful that you've looked into this already. I'm not a fan of page view counters and if you managed to convince me otherwise (😉), I'd investigate a Google Analytics API that could pull the data in and produce some more meaningful data. One day, I'll get access to Steemit's GA account!
Hopefully it won't take so long ;-D
Interesting. That even predates me by a a couple of months. I have no recollection of ever seeing that feature in operation, so maybe they removed it quickly. If I remember, I'll ask @cmp2020 if he remembers it when he gets home from college. I didn't find any other references to it in github or google after a couple quick searches.
I agree that it was likely removed due to performance considerations. That definitely strikes me like it would have trouble scaling. Also, when the automated voting came along, I'm not sure how accurate it would be. I think useful recommendations would probably require something more sophisticated (i.e. language processing & machine learning). There's a whole field of AI research that's dedicated to this purpose.
If I scroll to the bottom of steemitblog, I get there. If I scroll to the bottom of steemitblog/posts, it ends prematurely. Both go all the way to the bottom from steemitdev. Maybe another bug that you fixed with your work on condenser. 😉
I think it was the first post that came from the steemitblog account. There was a latter post about Steemit going open source so my suspicion is that the code didn't even hit GitHub. I haven't really looked though.
Good point. I suspect that it won't be long before an AI model can analyze a user's posts, review who they vote and comment on and subsequently find authors with a similar profile. I would say that using tags (for example) but few people use tags correctly now. Ignoring that downside, it actually feels like a fairly straightforward algorithm to do.
My guess - it's hard coded on the steemit.com domain 😉
Upvoted. Thank You for sending some of your rewards to @null. It will make Steem stronger.
Your post has been successfully curated by @kouba01 at 40%.
Thanks for setting your post to 25% for @null.
We invite you to continue publishing quality content. In this way you could have the option of being selected in the weekly Top of our curation team.
Thank you @kouba01!
This post has been featured in the latest edition of Steem News...