My Lorenz Curve project isn't dead yet
The last time I posted about my Lorenz Curve project I thought that it was basically doomed. At the time I thought that using the api interface to query the blockchain database for information about the reward-distributing virtual ops was just too slow to be practical. As I was looking at the api docs for other projects I realized that the getOperationsStream method could start from any block (I had assumed it would only be a stream of the "current" blocks), and I think this method is faster than the one-at-a-time querying I was doing. I've been working on a new script built around this approach. I ran it yesterday for a few hours and got a few days worth of data.
I've still got a way to go before things are working robustly, but some of the things I'm seeing seem like they make sense, so I feel like I'm making progress. For example, here are the SBD distributions for one day (assuming no bugs in my code, etc.):
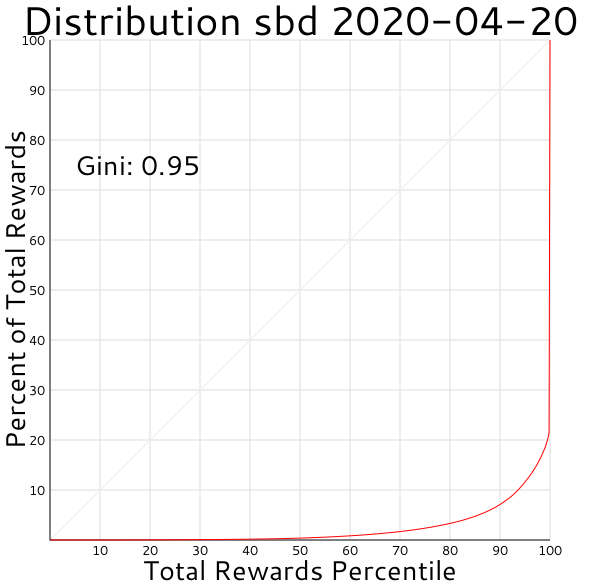
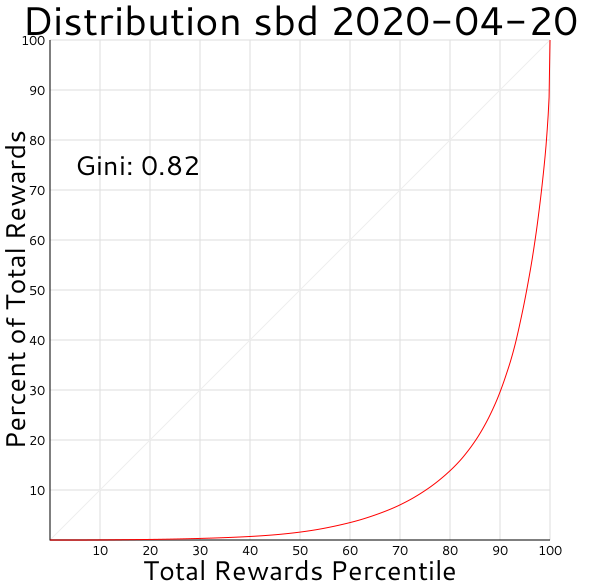
That sharp uptick at the end are SBDs going into the steem.dao account. If I exclude proposal_pay ops from the analysis it looks like this:
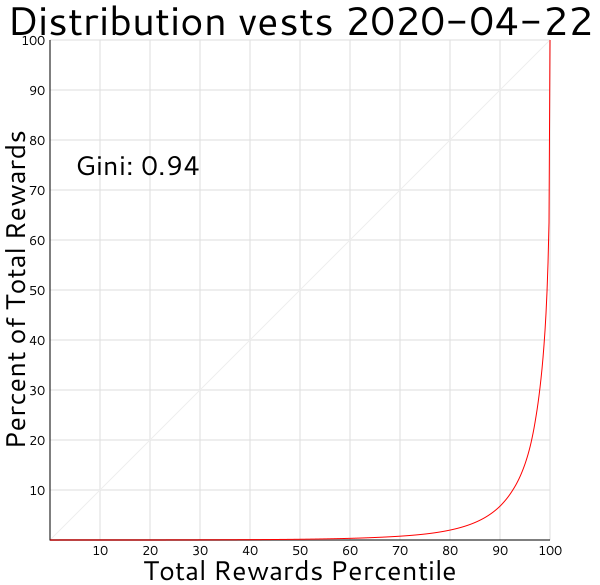
And here's what the vests (which are mostly proportional Steem Power) distribution is like, first with just witness rewards excluded:
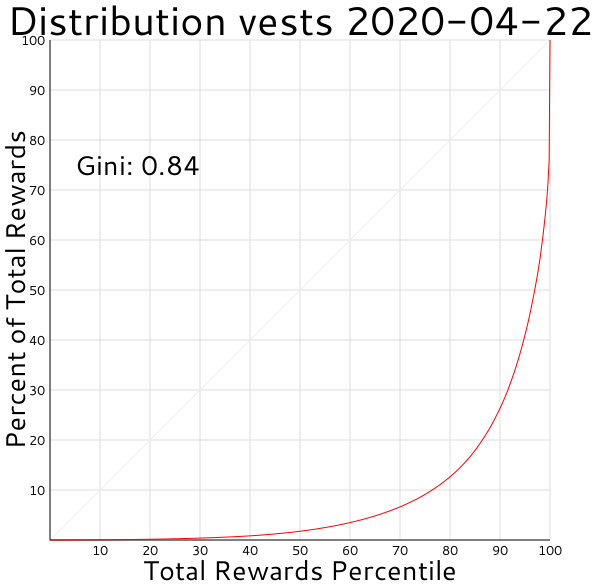
And then with witness and curation rewards excluded:
Looking at just the curation rewards, it's skewed very heavily toward the top end:
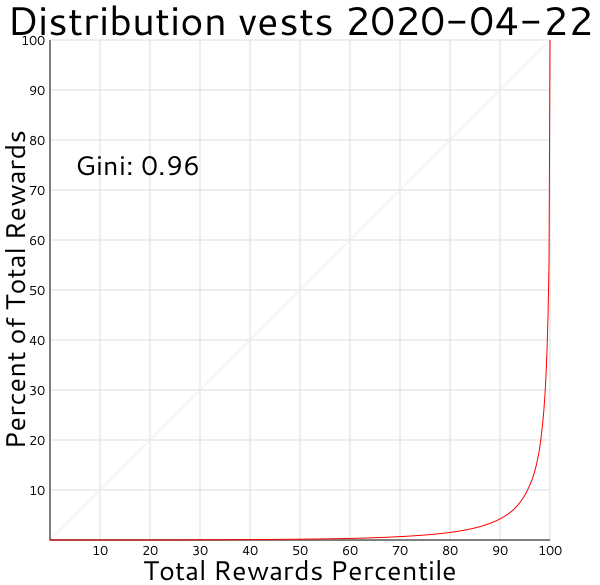
And the witness rewards curve my script is creating seems to track what the algorithm is supposed to be, with the top 20 treated equally to each other but on a much higher tier than everyone else:
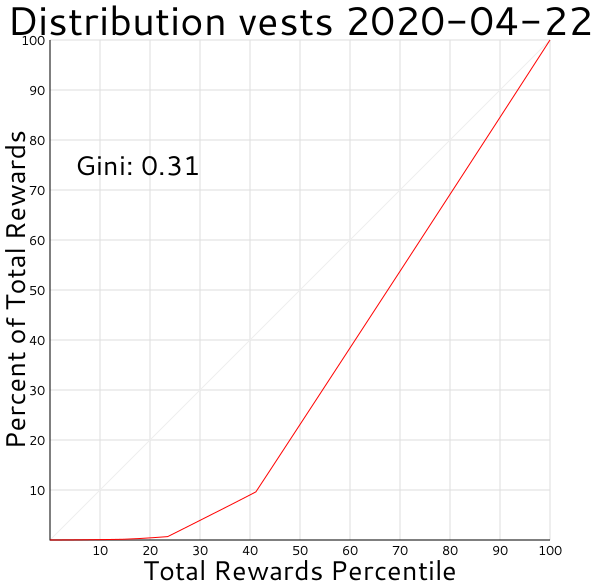
One thing I need to decide before I start incorporating timespans longer than a single day is how to treat the Vests / SteemPower conversion factor. I think that's just a formula based on time, but I haven't looked it up yet. If I want combined rewards in a single graph I'll have to decide how to fairly compare Steem/SPs and SBDs as well. Another thing I noticed when looking at the data is that a lot of rewards are going to likwid as a beneficiary, but I believe that's a service that redistributes what it gets back to the original author (after taking a cut), so it may make sense to put some special case code in for that.
I'm still pretty far from being done. Even if my code is working and bug free (which is no guarantee), it's still in a very hacky "proof of concept" stage rather than a robust tool. But at least I feel like I'm getting somewhere again.