AI and Machine Learning in Cryptocurrency Trading: A Steem/USDT Perspective
Hello everyone! I hope you will be good. Today I am here to participate in the contest of Steemit Crypto Academy about the AI and Machine Learning in Cryptocurrency Trading: A Steem/USDT Perspective. It is really an interesting and knowledgeable contest. There is a lot to explore. If you want to join then:

Question 1: Exploring AI and ML in Cryptocurrency Trading
Explain how Artificial Intelligence and Machine Learning are applied in cryptocurrency trading. Highlight their advantages over traditional methods and provide examples of their effectiveness in analyzing and predicting market trends.
Artificial intelligence and machine learning have been proved to be very useful in each field because of their number of benefits especially for the automation and intelligence to solve the problems. Indeed artificial intelligence and machine learning excels from the traditional methods in each field. Here is how artificial intelligence and machine learning is applied in the cryptocurrency trading:
Predictive Analytics:
AI and ML algorithms evaluate the historical price data of the cryptocurrency. We can evaluate the trading volume with the help of the AI and ML. We can use technical indicators along with the artificial intelligence and machine learning to make predictions about future market trends. Sometimes we cannot judge the exact scenario of the market such as the trends and patterns with the human eye. But if we blend our vision with the artificial intelligence and machine learning then we can become more actionable and we can easily understand the patterns and trends.
Example: We can apply the advanced time series models like Long Short Term Memory (LSTM) networks to predict price trend of the cryptocurrencies such as Steem.
Sentiment Analysis:
Sentiment analysis are of great usage and it is the biggest application of AI and ML. Natural language processing in the machine learning processes huge amounts of the unstructured data. By using NLTK we can organize the unstructured data. It processes data including the social media posts, news articles and forums to measure market sentiment. It enables traders to predict when demand or supply may shift based on public opinion.
Example: The sudden rise in the positive sentiments on Twitter about Ethereum caused to increase the rise in the prices. It often happens with other coins as well. Whenever the opinions of the people become positive from the sentiment analysis then it is the opportunity to buy the assets.
Automated Trading Systems:
If we talk about the automated trading systems then these are also because of the artificial intelligence and machine learning. These AI based bots carry out the trades based on the real time analysis, predefined conditions and set of rules to drive the trading.This reoves the human errors and provides precision and consistency over manual trading.
Example: For Steem/USDT trading pair or any other trading pair we can execute buy or sell orders by AI bots within milliseconds when technical thresholds are exceeded.
Risk Management:
Risk is the most crucial factor in the trading and in the trading there is always risk. And it is very necessary to manage the risk. Artificial Intelligence evaluates risks by understanding market volatility, liquidity and historical data. It dynamically adjusts portfolios to keep away from potential losses. And on the other hand AI and ML maximize profits despite unpredictable market conditions.
Example: By using the features of machine learning we can build and train a model to manage the portfolio during the market crash to avoid the potential losses. We can train the model with our desired training data so that in future it can behave according to this trained data.
Anomaly Detection:
Crypto market is subjected to volatility and precision. AI algorithms can detect irregularities in trading patterns or market behaviour. They help the traders to identify unusual activity such as market manipulation or price anomalies.
Example: To cope with the flash crashes in the market and providing early alerts for action we can use artificial intelligence and machine learning.
Advantages of AI and ML Compared to Traditional Approaches:
Faster with Greater Efficiency:
AI offers the capabilities of processing large-scale data within real-time, generating insights with far greater speed than methods of traditional analysis.Superior Pattern Recognition:
ML algorithms can find hidden non-linear relations and subtle interconnections in data, beyond the capabilities of the classical statistical approach.Devoid of Human Emotions
Automated systems do not possess human emotions such as fear, greed, or panic, thus enabling rational and consistent decision-making.Round-the-Clock Market Monitoring:
AI systems are always on, analyzing markets 24/7, which is a necessity for cryptocurrency trading since markets never close.Adaptability and Continuous Learning:
AI models learn to get better with time by learning new data, adapting to changing market dynamics without human intervention.Customizable Tools:
Pre-trained models and user-friendly interfaces make AI accessible even for non-technical traders, who can use it without building the system from scratch.
Examples of AI and ML Effectiveness in Cryptocurrency Trading
Volatility Prediction:
An ML model that was trained on the history of Bitcoin was able to accurately predict a volatility spike at the time of a high-impact news event, and traders were able to hedge their positions.Sentiment Driven Strategy:
AI sentiment analysis identified growing optimism around Cardano before a major update announcement, prompting early investments that capitalized on the subsequent price surge.Optimized Portfolio Management:
Under a bearish trend, AI systems dynamically reallocated a diversified crypto portfolio, thereby reducing the loss by transferring funds to stable coins and less volatile assets.Better Scalping Strategies:
High-frequency trading systems that relied on AI earned more profit due to the execution of microsecond trades in response to minute changes in price.Fraud Detection:
AI detected unusual trading activity on a lesser-known cryptocurrency, uncovering a pump and dump scheme and saving traders from potential losses.
AI and ML are transforming the cryptocurrency trading landscape by providing traders with tools for real-time analysis, accurate predictions, and automated execution. Their adaptability, learning, and ability to handle vast datasets are beyond traditional methods, enabling traders to navigate the volatile and complex crypto markets with enhanced precision, efficiency, and confidence. These technologies are sure to become the indispensable assets of modern traders as they continue to evolve.
Question 2: Building a Predictive Trading Model
Create a simple predictive trading model using historical Steem/USDT price data. Use any AI or ML tool (such as Python’s Scikit-learn or TensorFlow) to predict price direction for the next 24 hours. Provide a step-by-step explanation of the process, including data preparation, algorithm selection, and interpretation of the model’s output.
Here in order to create the simple predictive trading model by using the historical data of STEEM/USDT we need a historical data first for the predictive model.
Data Preparation
Here is the data preparation for the predictive model of STEEM/USDT. For getting the dataset csv file I went to the Bitget. There was the historical data of the STEEM. I downloaded the historical data about the steem on a daily timeframe.

Here I downloaded the CSV file. I opened it in the local storage and learnt the dataset like the name of the columns because to access the data we need to know the column names correctly.
So by using this dataset we will predict the direction of the price (up or down) of Steem/USDT for the next 24 hours based on historical price data. This is a binary classification problem:
- Price Up (label = 1) when the price increases in the next 24 hours.
- Price Down (label = 0) when the price decreases.
We will train a machine learning model based on the historical price data using the dataset of STEEM/USDT. We will account the open, high, low, close, and volume to make the prediction.
Step 1: Load the Historical Data
First of all We will load the historical data but before that we need to import the relevant library like pandas to read the dataset in the CSV file. After loading the data we will be able to understand the format of the data in the compiler.

This is the code in the python to load the dataset and understand the rows of the data. This gives us the basic understanding of the data structure. We can confirm the existence of key columns like timestamp, open, high, low, close and volume.
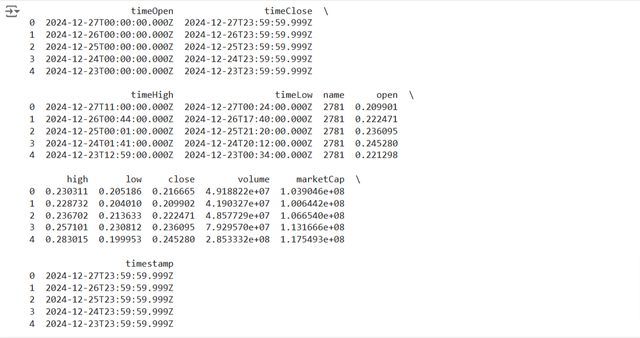
Here you can see that the data has been loaded from the dataset. We can see the values under the column names. In this dataset we can see that there are time columns and the simple open, close columns are representing the price open and price close and so on. Data preparation is very important in the machine learning for this we use specific tools and natural language processing techniques.
Step 2: Feature Engineering - Creating a Target Variable
Now we need to create a target variable through which we will determine the price change either in the upwqard direction or downward direction. The predictive model needs a target variable to predict. So we will create a column priceChange. It will tell the model whether the price will go up (1) or down (0) in the next 24 hours.
We look at the closing price of the next day and then we compare it with the current closing price. Here if the price of the next day is higher then we label it as 1 (up), otherwise 0 (down).
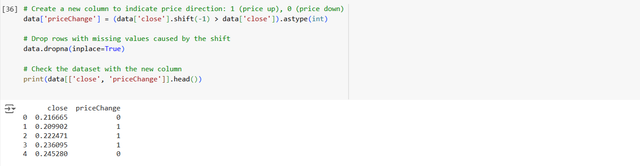
Here if we see I have used the shift function. The shift function is used to move the closing price by one day (shift(-1)). It allows us to compare the closing price of toady or current day with the closing price of the next day. The .astype(int) converts the boolean result (True or False) into 1 or 0 as we are labelling the change in the price with 1 or 0.
Step 3: Prepare the Features (X) and Target (y)
Now after creating the target variables we need to separate the input features from the target. Here input features is the information used for the prediction and the target is the value we want to predict. The input features will be the columns such as open, high, low, close and volume. The target will be the priceChange column which we have set previously.

Here we have set the features and the target variables.
Step 4: Split the Data
Now at this stage we need to split the data from the dataset. We will use some data for the training of the predictive model and the some data will be used for the testing of the predictive model to see if it works correctly or not. We will check how well the model generalizes to unseen data. This is an important step which is used to avoid the overfitting the model to the training data.

Here to split the data I have used train_test_split from Scikit-learn. By using this I have set aside 20% of the data for testing. It ensures the remaining 80% will be used for training the model.
Here an important point to notice is that the shuffle=False. It ensures that the time series order is maintained to avoid shuffling because we are dealing with the sequential data.
Step 5: Train a Machine Learning Model
Finally it is the step to train the machine learning model after splitting the data for the training and testing. Now we know that the data is already prepared. Now we need to select a machine learning model. And after selecting it we will train that model for the future prediction of the next day. We will train it to learn the historical patterns of the price.
I am using Random Forest Classifier. It is a good choice because it is robust and works well with time series data. We will initialize a Random Forest Classifier. Then we will train it by using the training data from the dataset. It will learn and will determine whether the price will go in the upward direction or in the downward direction.

Here you can see that Random Forest Classifier has been initialized and it is using the training data which we split previously to train this model. We can see in the output that the model has been trained completely from the historical price data of STEEM/USDT.
Step 6: Sample Predictions
Now after training the model we will use it to predict some sample predictions. We will make predictions on the testing data to see how well it can predict price direction on unseen data. So we will use the trained model to predict the price direction for the test set and print the predictions.

Here you can see some sample predictions from the test data.
Step 7: Evaluate the Model
Now it is the time to evaluate the model which we have trained by using the historical data of STEEM/USDT. So to assess the performance of the model we need to calculate the how acurately this model predicts the direction of the price. We will use metrics such as accuracy, precision, recall and F1-score to evaluate the performance of the model. We calculate the accuracy which is the percentage of correct predictions. We also print a classification report that shows precision, recall and F1-score for both classes such as price up and price down.
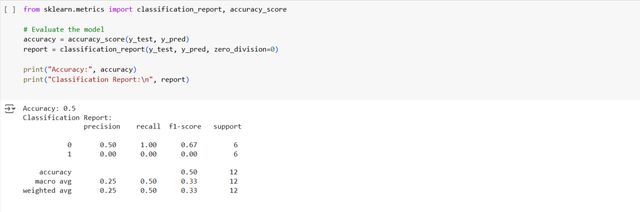
Interpretation:
- Accuracy tells us the percentage of correct predictions out of all predictions.
- Precision and Recall measure how well the model predicts price up and price down with respect to true positives, false positives, etc.
Step 8: Predict the Next Price Direction
Now we are near to predict the next direction of the price after a lot of work on the dataset, splitting the data, training the model and evaluating the performance of the model.
Now we will use the latest data point to predict the direction of the price for the next day. This is the most important part of the model because it tells us about the buying or selling opportunity. For this we will extract the most recent data such as the last row. We will pass it to the model and then we will predict the direction of the price for the next 24 hours.

Interpretation:
If the model predicts 1 then the price is expected to go up and if it predicts 0 then the price is expected to go down. After getting the latest data from the dataset the model has predicted that the price will go down in the next 24 hours.
Here are some key points for the preparation of this predictive model for the trading market predictions:
- Data Preparation: We load, clean and prepare the data by creating a target variable (
priceChange). - Model Selection: We chose the Random Forest Classifier because it os efficient and works well for our dataset.
- Evaluation: After training the model we evaluate its performance using accuracy and a classification report.
- Prediction: The model predicts whether the price will go up or down for the next 24 hours. It allows us to make trading decisions.
This model is a starting point for building predictive trading systems. It can be enhanced further by adding more features using different algorithms, or incorporating more advanced techniques like time series forecasting or deep learning models.
Question 3: Implementing Sentiment Analysis for Trading Decisions
Perform sentiment analysis on recent Twitter posts or Steemit articles mentioning "Steem." Use an AI-based sentiment analysis tool (e.g., NLTK, VADER, or Hugging Face) to classify posts as positive, neutral, or negative. Explain how the sentiment trends can be used to adjust a Steem/USDT trading strategy, providing a clear example based on your findings.
This is really an interesting question. I like the sentiment analysis by listening to the different content and voices about somethings. Actually recently I have learnt in my current semester Natural Language Processing (NLP) and in that in one chapter I explored the semantic and syntactic analysis in details. And I learnt tokenization, stop words, lemmatization and much more. So in this question I will perform the semantic analysis of the content related to STEEM.
I will use AI based sentiment analysis tool in python where NLTK (Natural Language Toolkit) will be used for the analysis of the posts related to steem. The posts data is in the natural language and we will process the data for the sentiment analysis.
Here is the complete step by step process for the sentiment analysis from the posts of Steemit and Twitter in which the word Steem is mentioned by the users:
1. Import Required Libraries
For the sentiment analysis tool setup we need some important libraries which help us in the natural language processing. With the help of these libraries we will perform sentiment analysis on the posts.

import nltk: This line imports thenltkwhich is a Natural Language Toolkit library. It is the most popular tool for text processing and natural language analysis.nltk.download('vader_lexicon'): This line downloads the VADER which is Valence Aware Dictionary and sentiment Reasoner lexicon. This is a type of dictionary that has already built in sentiment information. And this information is used by VADER in determining the sentiment of text. Thevader_lexiconis required for theSentimentIntensityAnalyzerbecause it is used to carry out sentiment analysis on text.from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer: This imports a class which is known asSentimentIntensityAnalyzerfrom thevaderSentimentpackage. This provides the core functionality to calculate the sentiment scores of the given text.
2. Instantiating the Sentiment Analyzer

Here I have created the instance of the SentimentIntensityAnalyzer. It will be used in order to analyze the sentiment of posts. After this it assigns sentiment scores. So creating its instance is important in the sentiment analysis.
3. Define Posts
After this we need the data of the posts for the sentiment analysis. And on the basis of those analysis we will predict how we can adjust our trading strategies of STEEM/USDT.

Here in order to accumulate the list of the posts I have defined an array of the posts with the name posts. This array of posts is holding 30 different posts. I have taken random post's data precisely about the STEEM for the extensive sentiment analysis based on these 30 different sayings in which Steem is mentioned.
In this posts data some posts are positive, some posts hows neutral data and some posts shows negative sentiments. So the data is mix of the favourable data, neutral data and against data and it will really help how we will do the sentiment analysis of this data by using NLTK. And on the basis of the comprehensive result we will decide the trading strategy.
4. Perform Sentiment Analysis for Every Post
Now I will perform the sentiment analysis for each post separately. So we can perform the sentiment analysis for any data for each line and word.

The loop goes through each of the posts that is in the list posts. The sia.polarity_scores(post) function calculates a sentiment score for each post. The polarity_scores method returns a dictionary with four values. compound is the overall sentiment score. It combines all the sentiment components such as positive, negative, and neutral.
There is conditional statement on the basis of the compound score. According to the compound score:
- If the score is above or equal to 0.05 then the post is classified as Positive.
- If the score is below or equal to -0.05then the post is classified as Negative.
- Otherwise the post is classified as Neutral.
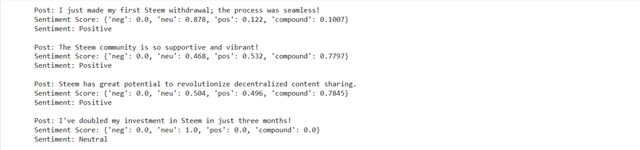
After analyzing the posts and sentiment analysis it prints the post and its sentiment score. At the end it returns whether the post is positive, negative or neutral.
5. Count the Number of Positive, Neutral and Negative Posts
Then I have added the part of code to know the total number of posts in each category.
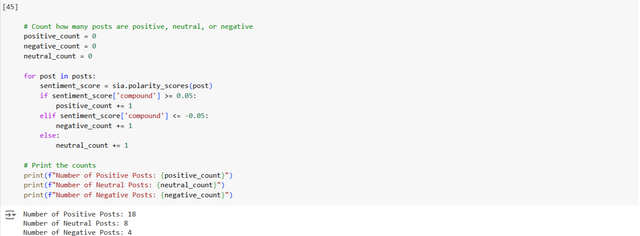
This code block will count the number of positive, neutral and negative posts. It will once again iterate through each post and increment the respective counters based on the compound score for the sentiment. After it has counted the posts it will print the sum of positive, neutral and negative posts.
6. Sentiment Based Trading Strategy

Trading Strategy Logic:
If we talk about the trading strategy after these sentiment analysis then we can say that:
If there are more positive posts than negative posts then the sentiment is overall positive. And this overall positive sentiment suggests a buying opportunity for Steem/USDT.
If negative posts are more than positive posts then the sentiment as a whole is negative. So when the sentiment analysis of steem are negative then it indicates a selling opportunity for Steem/USDT.
If the number of positive and negative posts are the same then the sentiment is considered as neutral. This neutral sentiment suggests that the trader should hold Steem/USDT.
The Sentiment Analysis Tool which we have developed for the Steem analyzes posts about "Steem". After this posts are sorted into three categories such as positive, neutral and negative. The counting of the the positive, neutral and negative posts gives a sense of the general sentiment about Steem. This sentiment can then be used to modify a Steem/USDT trading strategy:
Positive Sentiment: If the sentiment is positive it means there are more positive posts than negative posts. It indicates an optimistic view toward Steem's future. This suggests a buying decision of Steem/USDT.
Negative Sentiment: If the sentiment is negative then it means that there are more negative posts than positive ones. It indicates pessimism which gives the suggestion to sell Steem/USDT.
Neutral Sentiment: In cases where no explicit trend exists in sentiment analysis then the strategy is to hold Steem/USDT until more information becomes available.
The sentiment analysis regarding Steem are positive so is is giving the buying opportunity.
This is very helpful for traders to use the sentiment analysis for decision making on the basis of the social media or community sentiment. It is very useful to capture the trend of the market related top the specific coins such as Steem.
Question 4: Designing an Automated Trading Strategy
Describe how an automated trading system can be designed using AI tools. Include the logic for triggering trades, setting stop-loss levels, and taking profits. Use examples to illustrate how the system can respond to live market data in a Steem/USDT trading scenario.
There are a number of ways and methods to design an automated trading bot and system which can inform us about the trading scenarios and we can perform the trading according to that if our automated trading system is reliable and trusted. I will use an API from the trusted source to get the current price of the steem and then I will decide what do to and then the bot will inform us automatically.
Step 1: Sign up on CoinMarketCap
First of all as we need an API for the price analysis and we know there are a number of options for the API such as Binance, Kraken, Kucoin but these are all the exchanges and in some regions their access is restricted and similarly their API will also not work in those regions.
So we can use an API which is public as well as reliable and it will work everywhere. For this we have two options which are reliable sources Coinmarketcap and Coingecko. But I am going to use Coinmarketcap.
First of all we need to sign up on the CoinMarketCap API. Once signed up we can find our way for the generation of the API. There are different plans for the API but as we want to use it for the personal purpose so we will use free plan. And this free plan allows to process 10000 requests per month.
An API key is like an ID and serves to authenticate any request to the API. Without an API key we cannot gain access to CoinMarketCap's gigantic database of cryptocurrency information. This API offers critical information including real time prices, market capitalization and trading volume for many cryptocurrencies. So we need to make sure that we have saved our API key at safe place and do not share it with anyone else who can misuse your API key.
Step 2: Install Required Library
To interact with the CoinMarketCap API we will need the requests library. This is a Python library that simplifies the process of sending HTTP requests and receiving responses. We can install it using the simple request command as shown below:

The requests library will handle communication between the Python script and the CoinMarketCap servers. With this library we can send requests for specific cryptocurrency data and CoinMarketCap will respond with a JSON object containing the information we need. This step is crucial for fetching real time data to inform about the trading strategy.
Step 3: Fetch Cryptocurrency Data
Now we need to fetch the live data for the Steem/USDT. We can fetch particular information about a coin such as its live price, volume or its market cap by using the CoinMarketCap API. I am going to include some Python code below it will fetch the latest price of the STEEM/USDT trading pair for on the basis of this data we will train our model for the automation.
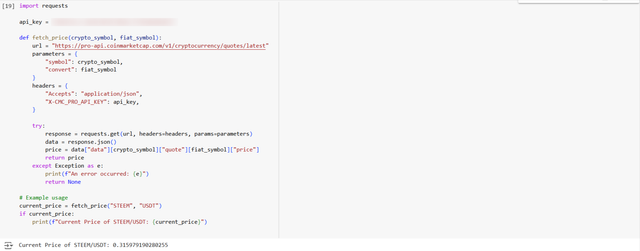
The script does a GET request to the API endpoint which contains the latest cryptocurrency quotes. I have specified the symbol for the cryptocurrency. As we need to get information of price data about STEEM/USDT so in this case STEEM and the equivalent fiat currency USDT is selected.
This function takes the heavy lifting that involves connecting to the API and sending a request and then receiving the response from the API. It does this by parsing its contents and extracting the price. It uses error handling as well. This use of error handling prevents the program crashing from any network issues and invalid responses.
We can see that the API is working completely fine and it has returned the exact current price of STEEM/USDT which is 0.315979190280255.
Step 4: Implement Trading Logic
Once we have the live price data now it is the time to add trading logic. Now in the trading logic I will use a fixed price for the entry and then on the basis of that price I will caluclate the and triggers stop loss, take profit or the hold condition.
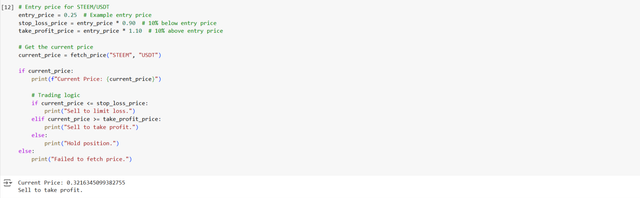
This script evaluates whether the current price triggers a stop loss, take-profit or hold condition.
Here is the breakdown of the trading logic used in this script:
- Entry Price: It is the price that we bought
STEEMinitially. For this example we assume $0.25. - Stop Loss Price: As a way of reducing losses we have set a threshold price 10% below the entry price.
- Take Profit Price: We have set a target of selling when the price has gone above a certain profit level such as 10% above entry price. We can modify the logic according to our risk.
When I have run this logic for the trading it is Current Price: 0.3216345099382755, Sell to take profit. So it is working fine.
This code makes the system to respond dynamically according to market conditions. For example if the current price falls below $0.225 then the system sells to cut losses. Similarly if the price goes above $0.275 it sells to lock in profits. If neither of these conditions is met then the script suggests holding the position.
Step 5: Automate the Strategy
Manual monitoring of cryptocurrency prices can be exhausting. To address this problem automation ensures continuous evaluation of trading conditions. By using Python's schedule library we can repeatedly execute the trading logic at fixed intervals such as every minute.

This script ensures that trading logic runs every 10 seconds without the need for manual intervention. The schedule library has very simple syntaxes. So it is pretty easy to define how frequently tasks will be executed. The infinite loop (while True) makes sure that the bot is running until it is manually stopped.
We can also implement email notifications when the certain changes occurs in the market according to the pre-defined conditions. For that purpose we use email related python library and then we add the email address at which we want to send the email notification of the market update for the sudden action then we need to give the email address and password from which we will send email.

This automated trading system is aimed at making informed decisions based on real time data from CoinMarketCap. However before using it with actual money consider testing it with historical data or backtesting to refine the parameters and improve reliability. Live trading holds risks so be very cautious and adjust your logic for trading according to changes in market trends and volatility.
Question 5: Addressing Challenges and Improving Reliability
Analyze the challenges of using AI/ML in cryptocurrency trading, such as overfitting, data limitations, and execution speed. Propose solutions to mitigate these challenges and improve the reliability and performance of AI-driven trading strategies. Include practical examples where applicable.
Everything comes with challenges and dark as well as bright aspects just like a picture which has two sides one is attractive and one side is not fascinating. Similarly when we implement AI and ML in cryptocurrency trading it also comes with some challenges and precautions.
And it is necessary to address these challenges to ensure the reliable performance. Here are the analysis of the primary challenges associated with the cryptocurrency trading executed with the artificial intelligence and machine learning.
1. Overfitting:
Overfitting arises when a model learns to recognize patterns specific to the historical data but it fails to generalize to new data according to the unseen market conditions. We know that cryptocurrencies are highly volatile markets and thus overfitting is a major problem in cryptocurrency trading.
Here are some solutions towards the overfitiing:
- Cross Validation: We can use techniques such as k-fold cross validation to evaluate the model on different subsets of data. This would decrease the chances of overfitting since the model is sure to perform well on unseen data.
- Regularization: Use L1 or L2 regularization to penalize complex models and encourage simpler, more generalizable solutions.
- Use Diverse Data: Train models on data from multiple timeframes, market conditions, and currencies to ensure robustness.
Example: A trading model trained on BTC/USDT data from 2021 alone might overfit to patterns specific to that year. Incorporating data from other years and other pairs such as ETH/USDT can help the model generalize better.
2. Data Limitations
Cryptocurrency markets are relatively new so historical data is limited as compared to traditional financial markets. Data quality can also be inconsistent with missing values, biases or inaccuracies. So data limitations are the problems in the cryptocurrency with the help of AI and ML.
Here are some solutions towards the data limitations:
- Synthetic Data Generation: Use techniques like Generative Adversarial Networks (GANs) to create synthetic market scenarios for training purposes.
- Data Augmentation: Introduce noise, adjust timestamps, or manipulate volumes to create varied scenarios that mimic real market behavior.
- Fill Gaps with Interpolation: Use statistical methods to handle missing values effectively without distorting the data.
Example: If there are gaps in BTC/USDT hourly data due to API downtime interpolation can estimate missing prices ensuring uninterrupted training and testing.
3. Execution Speed
The market here remains in operation for 24/7 hours and a price might change within those minutes. Missed execution or unbeneficial transactions might arise from delayed implementation due to slow decision making by the AI model itself or because of API latencies.
Here are some solutions towards the execution speed:
- Optimize Algorithms:: Optimize Algorithms to use less resource intensive yet lightweight models, such as tree-based models (like XGBoost) or simple neural networks, against deep and resource-intensive ones for decision-making in a real-time environment.
- Low-Latency Infrastructure: Place trading bots on servers close to the exchange data centers so that the network latency is minimized.
- Parallel Processing: Implement multithreading or multiprocessing for handling many tasks at once, like fetching data and making predictions.
Example: A bot that makes predictions every second can use an optimized XGBoost model to have instant responses, but for nightly re-training or strategic decisions, a deeper model can be reserved.
4. Market Manipulation and Noise
Markets are prone to manipulation such as pump and dump schemes and noise which is high. So it is tough for models to filter the actionable signals from noisey fluctuations.
Here are some solutions towards the Market manipulation and noise:
- Feature Engineering: Add features like order book depth, spikes in trade volume, and abnormal price patterns to allow models to identify manipulative behaviors.
- Use Ensemble Models: Average the prediction of multiple models to avoid sensitivity to noisy data.
Example: If a price surge in STEEM/USDT is driven by a pump-and-dump scheme, incorporating volume changes and social media sentiment as features can help the model avoid false signals.
5. Lack of Transparency and Interpretability
Many AI/ML models, especially those that are deep learning types, are black-box, meaning that it is extremely difficult to understand how particular trading decisions are made by the system. Lack of transparency in this can jeopardize trust in the entire system.
Here are some solutions towards the lack of transparency and interoperability:
- Use of Explainable AI (XAI): Techniques can be used such as SHAP (SHapley Additive exPlanations) or LIME, which provide insights into where the factors were influential during the model's predictions.
- Interpretable Models for Key Logic: Apply more interpretable models such as logistic regression or decision trees on key decisions but leave the complex models for side tasks.
Example: Using SHAP we can trace why 24-hour price change or trading volume made when we buy or sell STEEM.
Improving Reliability and Performance
To ensure that AI-driven trading strategies are reliable and effective, the following practices are recommended:
1. Regular Re-Training
Markets keep changing, and models should adapt to new patterns and behaviors. Periodically retrain models using the latest data to prevent them from becoming outdated.
Example: A model that is trained on a pre-2023 database might not account for recent trends such as institutional uptake of cryptocurrencies. Regular refreshment ensures continued relevance.
2. Strong Backtesting
Thoroughly test any trading strategy on history data before it is made live. Use out-of-sample testing and simulate varied market scenarios, such as bull, bear, or sideways markets.
Example: A backtesting system that tests a strategy on both 2021's bull run and 2018's bear market can reveal whether the model performs consistently across conditions.
3. Incorporate Risk Management
Integrate stop-loss and take-profit mechanisms into the AI strategy to manage risks. Define clear parameters for maximum drawdowns and avoid over-leveraging.
Example: Set a maximum allowable drawdown of 5% per day to ensure the model doesn’t incur significant losses during unexpected market crashes.
4. Hybrid Approach
Combine AI-driven strategies with traditional technical indicators (e.g., Moving Averages, RSI). This hybrid approach allows AI to handle complex, data-driven patterns while leveraging well-established trading principles.
Example: Use the AI to find anomalies in market behavior and rely on the RSI to verify overbought or oversold conditions.
The benefits of AI/ML in cryptocurrency trading are vast, including data-driven decision-making and scalability. However, overfitting, data quality, and execution speed pose challenges. Cross-validation, optimized algorithms, latency reduction, and transparency can help traders tackle these issues and build reliable AI-driven strategies. The systems are further ensured to be reliable in dynamic and unpredictable markets through regular re-training and comprehensive backtesting.