Steem Data Services (SDS) / Update Notice / Version 0.1.7b
Version Details

SDS will be updated to version 0.1.7b within the next few days. The new version is already in the process of being installed on sds0 (developer requests going to sds0 are automatically proxied to sds1 in the meantime).
Here are some of the most important new features and changes in this version:
New API Module
transactions_api
This API comes with a full transaction index and enables us to retrieve a block, transaction or block number bytransaction_id. I worked really hard on this one to get the database size as small as possible. It's now only about 34G in size and still performs very well.
For comparison, if one would create a regular database that contains an index on alltransaction_idsof the Steem blockchain, the resulting size would be > 120G.

New API Module
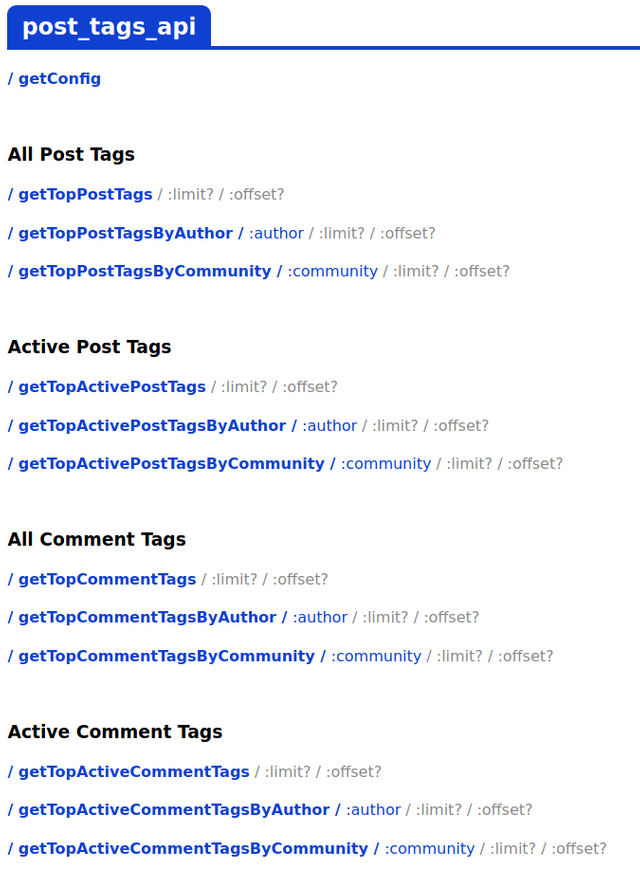
post_tags_api
This one was already in preparation when the last version came out. Now a few of its API methods are finally ready to be used. It allows to quickly retrieve tag statistics like 'top used tags of all posts/comments in the blockchain' and 'top active tags of all active posts/comments'.
It also returns a fieldcountfor each tag, so it can be used to build some nice daily/weekly statistics too. More methods will be added in future.

New API Method
witnesses_api/getWitnessVotesSummary
This method returns a list of all incoming witness votes for the given witness (including the total proxied vesting shares per voter). The resulting rows are sorted by influence descending.
It was backported to the 0.1.7a already to have way faster backwards proxy and witness votes searching capabilities on SteemWorld.New Field
last_replyin all Feed Lists
The field is now available in all feed list results (for root posts only) and it contains the timestamp of the last created reply for each post. If there are no replies, it will be returned as '0'.
Thanks to @moecki for the great ideas ;)
Update
I needed to start a full 're-parse' operation, therefore I could use the opportunity to extend the new post_tags_api already in this version:
Installation Status
- [x] Installing the new version on
sds0 - [x] Live testing the version on
sds0 - [x] Redistributing to
sdsandsds1servers
Have a good one! Steem on ~ 🚀
If you like what I do and you want me to be your Steem witness,
please vote for @steemchiller on steemit.com/~witnesses or steemworld.org/witnesses.


Cool! Danke für deine Arbeit! 👍
Die API ist schon sehr interessant. Das erspart mir das Durchlaufen von Posts. Bin gespannt, welche Methoden du da noch einbaust. TagsByCommunity und TagsByAuthor wären sehr nützlich für eine Community- und Autorenseite.
Würde mich schon interessieren, wie du das gemacht hast. Könnte aber auch verstehen, wenn du hier nicht alle deine Algorithmen offenbaren möchtest.
Bedeutet das, dass du für jede API eine eigene Datenbank führst, die mit jedem Block aktualisiert wird?
Da sich die Version noch in der Testphase befindet und ich aufgrund eines festgestellten Bugs heute sowieso einen kompletten 're-parse' starten muss, bevor sie in Produktion gehen kann, werde ich bei der Gelegenheit die
post_tags_apinoch etwas erweitern. Mehr Details dazu demnächst ;)Ja, der Parser durchläuft die Blöcke und ruft entsprechende Events in den über die Config aktivierten Modulen auf (soweit das jeweile Modul nicht bereits bei einer höheren Blocknummer ist). Die Module können natürlich auch untereinander verknüpft werden, um Daten anderer APIs direkt abrufen zu können.
Jedes Parser-Modul verwendet normalerweise mindestens eine eigene Datenbank, die aber auch untereinander verknüpft (attached) werden können. Über die Config kann man auch festlegen, dass eine Datenbank für mehrere oder sogar alle Module verwendet werden soll, aber das würde ich aus Performance- und Wartungs-Gründen nicht empfehlen.
Es lassen sich auch Daten aus anderen Modulen direkt in SQL-Abfragen joinen, daher hat es deutlich mehr Vorteile die Datenbanken zu trennen und so unfragmentiert wie möglich zu speichern.
Die Aufteilung bringt zudem auch hinsichtlich der Verminderung der Redundanz sowie der im Notfall erforderlichen Wiederherstellung Vorteile. Allerdings wirst du dir dazu im Vorfeld wohl sehr viele Gedanken über die Art und Weise der Aufteilung und anschließender Verknüpfung (durch die SQL-Abfragen) gemacht haben. Dabei den Überblick zu behalten, ist nicht ohne.
Für den privaten Bereich habe ich ein paar mehr oder weniger komplexe Datenbanken erstellt und mit entsprechenden Abfragen und Codezeilen versehen. Insofern habe ich ungefähr eine Vorstellung davon, welchen Aufwand du mit der effizienten Speicherung der Daten der gesamten Blockchain hattest/hast.
Bin gespannt. :-)
Heute hatte ich noch einen neuen Gedanken. Oftmals interessiert mich, bei welchen Posts neue Kommentare eingestellt wurden und würde danach gern sortieren, damit man auch neue Kommentare in älteren Posts nicht übersieht. Für jeden einzelnen Post bekäme man das mit den Replies auch raus. Allerdings ist dies für eine Post-Liste (z. B. aus der
feeds_api) nicht ganz so "unaufwendig", da man erst zu jedem Post in der Liste die Replies abrufen müsste.Wäre es anhand der Daten in deinen Datenbanken (unkompliziert) machbar, in der Response (z.B. nach
feeds_api.getCommunityPostsByCreated) auch den Timestamp des letzten Kommentars zurückzugeben?Mir gefällt deine Idee und ich denke, dass ich ein Feld
last_replyin allen Feed-Listen für Root-Posts problemlos zurückgeben könnte. Wahrscheinlich wird das aber erstmal nur für neue Kommentare (Erstellungszeitpunkt) funktionieren, da ich sonst einen weiteren Index für das Feldupdated(das den Zeitpunkt der letzten Änderung enthält) brauchen würde.Ich schau mal, was ich da machen kann.
Das wäre doch sehr gut. Ich denke, es wäre nicht weiter tragisch, wenn es zunächst nur die neuen Kommentare funktioniert. Das wird sich dann ja nach und nach ändern.
Wenn du es eingebaut hast, wäre eine Info gut, damit ich weiß, wie das feld
last_replyzurückgegeben wird, wenn es keine (oder keine neuen) Kommentare gibt.In SDS, is there any chance you could provide a way to get a look at the partitioning below "redfish" - maybe plankton up to 9,999 and tadpoles/guppies from 10,000 to 99,999 (or any other names would be fine...), then start redfish at 100k?
1.8 million is a lot of accounts. It would be nice to get easier visibility of movement within that partition. Also, it might be useful to have a new category at the top end of the scale to give the whales something to shoot for ;-)
Maybe something like this?
Thanks for your ideas! Unfortunately, I can't change the categories for this upcoming version, but I agree that it would make sense.
I recently added a new method on the SDS dev server (sds0), which returns the account count for a specific VESTS range:
https://sds0.steemworld.org/describeMethod/accounts_api.getAccountCountByVESTSRange
For example, to get the number of accounts owning between 10,000 and 99,999 VESTS, you would call it like:
https://sds0.steemworld.org/accounts_api/getAccountCountByVESTSRange/own/10000-99999
Hi steemchiller, sorry to bother you. I am a graduate student working on a research project. I found SDS very useful. I want to collect follow history data but I have some issues using the API. For example, https://sds0.steemworld.org/followers_api/getFollowHistory/steemchiller/1487426276-1688031076 only returns 2 records. It seems it does not return the complete records. Do you have any suggestions? Thank you!
Hi, with the current configuration of the followers_api module you won't be able to retrieve entries older than 3 months, because it is configured with
store_history_days = 90(config can be seen via https://sds0.steemworld.org/followers_api/getConfig).So, currently there is no other way than traversing through all blocks' operations (for example with https://sds0.steemworld.org/blocks_api/getOpsInBlockRange/50000001-50000100/0/custom_json) and watch for
custom_jsonops withid = "follow". Not very efficient and will take a long time to go through the whole chain, but it would work.Hallo Chiller:
Eine kleine Fehlermeldung zur Steemworld von mir (EDIT: sind doch zwei :-) ):
Bei deinem Reward-Info-Tool auf https://steemworld.org/rewards-info passt irgendwas mit dem Date Range nicht. Obwohl ich ein gültiges Datum in die Felder eingetragen hatte, werden keine Rewards angezeigt.
Meine Eintragungen:
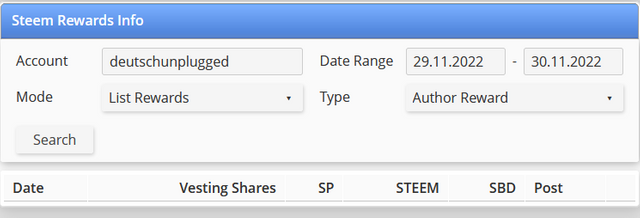
In der Konsole sieht man, dass folgende Abfrage versendet wird:
Anscheinend passt die Umwandlung von Datum in Timestamp nicht so recht.
Bei der Berechnung der Beneficiaries ist etwas nicht nachvollziehbar:

Beim Spender (hier deutschunplugged) wird angezeigt:
Beim Empfänger (hier du-finanzbot) wird angezeigt:
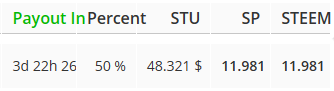
Mir scheint, als wenn beim Empfänger von den SP- und STEEM-Beträgen noch einmal der Benef-%-Satz ermittelt wird.
Ich schätze, es liegt die Abfrage https://sds.steemworld.org/rewards_api/getComingBeneficiaryRewardsSummary/du-finanzbot zugrunde.
Da wird im Abschnitt
"benef":{"stu":12.053,"sbd":0,"steem":23.908,"sp":23.908,"trx":23.908,"percent":25}der richtige Betrag zurückgegeben, aber bei den Summen in"sum_sp":11.954,"sum_trx":11.954,"sum_steem":11.954stehen die geringeren Beträge.Thanks for the latest update. You are very kind. Hopefully, Steemit will be more successful. The presence of steemworld.org really helps me in Steemit. We are waiting for the next update, @steemchiller
😊😊😊
Thanks for the compliment
Hey, ich muss schon wieder hier einsteigen :-))
Seit gestern geben diverse Responses vom sds0 das Feld
reply_countnicht mehr zurück. Das betrifft - soweit ich das jetzt feststellen konnte - alle Requests aus dercontent_search_apiundfeeds_api. Speziell aufgefallen ist dies beigetPostsByAuthorTextundgetCommunityPostsByCreated.sds1 und sds sind nicht betroffen. Es sieht so aus, als wenn du an neuen Features arbeitest :-)
Es wäre aber schön, wenn das Feld erhalten bleibt.
Bin gerade dabei, mein Frontend für die Suche aufzubereiten, da michelangelo3 seinen Server (mit der Suchfunktion) abschalten möchte...
Moin, ich habe das Feld gestern aus Kompatibilitätsgründen in
children(wie es auch von derposts_apizurückgegeben wird) umbenannt. Dies ermöglicht es Entwicklern eine zentrale Logik für die Behandlung der Ergebnisse derposts_apiundfeeds_apizu haben, ohne zwischen verschiedenen Feldnamen wechseln zu müssen.Ein paar neue Felder sind auch hinzugekommen, aber das werde ich alles demnächst in einem Post noch genauer erklären, bevor die neue Version auf
sdsundsds1installiert wird. Für den Übergang empfehle ich dir, bis dahin erstmal fest aufsds0zu gehen ;)Da bin ich gespannt! :-)
Ich finde die Vereinheitlichung gut, da ich auch bisher eine Klasse für die "Aufbereitung" der Community-Post-Daten nutze. Für die Suche wären das je nach Suchbegriffen (Kombis aus Text, Tags und Accounts) unterschiedliche Requests, so dass dein Ansatz sehr gut passt. Das
childrenhabe ich doch glatt übersehen...Mir ist die Tage noch was anderes aufgefallen: Wir haben in der Community gemutete User, deren Post-Daten
is_muted=0enthalten. Das liegt sicher daran, dass der Beitrag selbst nicht (aktiv) gemutet wurde, sondern der User.Ich nehme an, das ist so von dir beabsichtigt. Aktuell sehe ich hierfür nur die Möglichkeit, mit
communities_api/getCommunityRolesdie gemuteten User abzurufen und abzugleichen. Oder siehst du eine Möglichkeit, dies mit den Community-Posts (aus derfeeds_api) zurückzuliefern?Es gibt ab der Version
0.1.8(sds0) ein neues Feldauthor_role, das für gemutete User den Wertmutedenthält. Damit könntest du das also jetzt schon lösen.Trotzdem finde ich die Idee, ein extra Feld wie
is_author_mutedzu haben, gar nicht mal so schlecht. Ich werde mal schauen, ob ich das noch problemlos in der Version hinzufügen kann...You always release information that is very important for us to know the Steem Data Service. thank you very much for providing more information regarding Steem Data Services (SDS) / Update Notice / Version 0.1.7b .
I always appreciate your work. Thank you for this.
You are doing an excellent job, you will see that all hard work pays off, congratulations on the upcoming steemit sds updates.
.
These are great updates sir and i believe with this new upgrades and feautures, SDS would be a better working interface.
Thank you for this again, you are always doing a great Job which is very noticeably and well appreciated and i see no reason why i shouldnt vote for you.
I voted for you as a witness some weeks ago😊.