Blockchain & Cryptocurrency #2: Hash pointers and data structures
Hash Pointer
A hash pointer is a data structure that is used a lot in the systems that we're talking about. It is basically a pointer to the place where some information is stored. Together with the pointer we are going to store a cryptographic hash of the information.
So a regular pointer gives you a way to retrieve the information. A hash pointer will let us ask to get the information back and verify that the information hasn't changed. So a hash pointer tells us where something is and what it's value was. In fact it also stores the hash of the value that this data had when we last saw it.
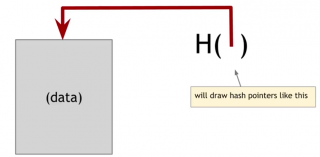
Use Hash Pointer to build data structures
We can take hash pointers and use them to build all kinds of data structures. So a key idea here, take any data structure, link lists, binary search tree or something like that and implement it with hash pointers instead of pointers as we normally would.
Blockchain
For example, here is a linked list that we built with hash pointers. This is a data structure called blockchain. It is just like a regular linked list where you have a series of blocks containing data and a pointer to the previous block in the list. Here the previous block pointer will be replaced with a hash pointer. So it says where it is and what the value of this entire previous block was. We're going to store the head of the list, just as a regular hash pointer.
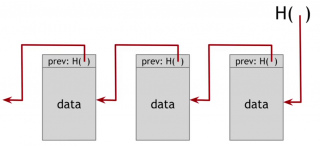
Tamper evidence
A use case for this is a tamper evident log, if we want to build a log data structure that stores a bunch of data. So that we can add data at the end of the log, and detect if somebody tries to mess up with data already presenti in some block of the log. That's what temper evidence means.
Why a block chain gives us this tamper evident property? Let's see what happens if an adversary wants to go back and tamper with data that's in the middle of the chain. And he wants to do it in such a way that we, the holders of the hash pointer at the head, won't be able to detect it.
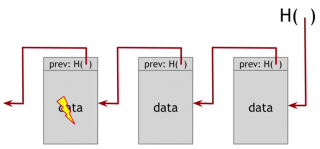
Tamper trial
The adversary changes the contents of the block with the lightning symbol. Therefore, the hash of this entire block changes, since the hash function is collision free. So we could detect the inconsistency between this data and the hash pointer of the following block, unless the adversary also tampers with its hash pointer.
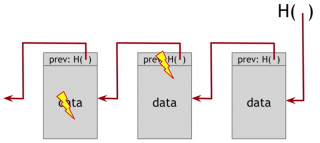
If he tampers with the hash pointer then these two match up. But the content of the following block is changed. That means that it's hash is not going to match the hash pointer of the following block. We're going to detect the inconsistency between the contents of this block and the hash, unless the adversary also tampers with the last block.
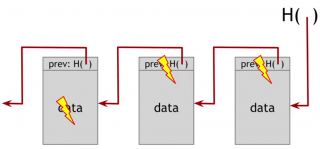
But now, the hash of this block doesn’t match the hash that we hold. The adversary can't tamper with that, because this is the value we remembered as being the head of the list.
Conclusion
So the upshot of this is that, if the adversary wants to tamper with data anywhere in this entire chain, in order to keep the story consistent he's going to have to tamper with hash pointers all the way back to the beginning. And he's ultimately going to run into a road block, because he wont be able to tamper with the head of the list.
So we can build a block chain like this containing as many blocks as we want, going back to some special block at the beginning of the list which we might call the genesis block. And that's a tamper evidence log built out of the block chamber.
Merkle tree
Another useful data structure we can build using hash pointers is a binary tree. We can build a binary tree with hash pointers called Merkle tree, after Ralph Merkle who invented it.
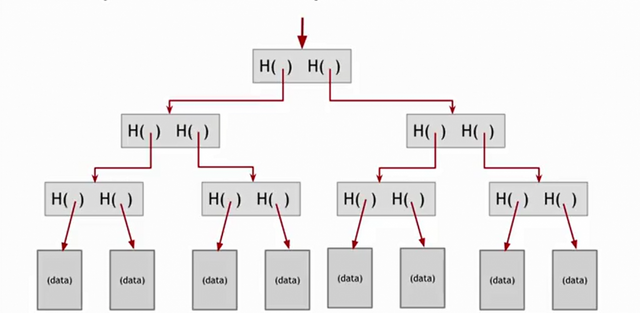
Suppose we have a bunch of data blocks (i.e. the ones represented on the bottom line of the graph). We're going to take consecutive pairs of these data blocks and for these two data blocks we're going to build a data structure that has two hash pointers, one to each of these blocks. Then we do the same with all the others data blocks.
Tamper evidence
Then we move a level up and build new blocks that contain a hash pointer of its two children. And so on, all the way back up to the root of the tree. At the end, just like before, we're going to remember just the hash pointer at the head of the tree.
Suppose that we want to go down through the hash pointers to any point in the list and make sure that the data hasn't been tampered with. As we just showed you with blockchain, if an adversary tampers with some data block at the bottom the tree, the hash pointer one level up won't match. So he'll have to tamper with all the hash pointer of upper levels until the root.
Prove membership in a Merkle Tree
Another nice feature about Merkle trees, is that is easier than the blockchain to prove that a data block belongs to it. Suppose that someone wants to convince us that a particular block is in the tree and show us which one is.
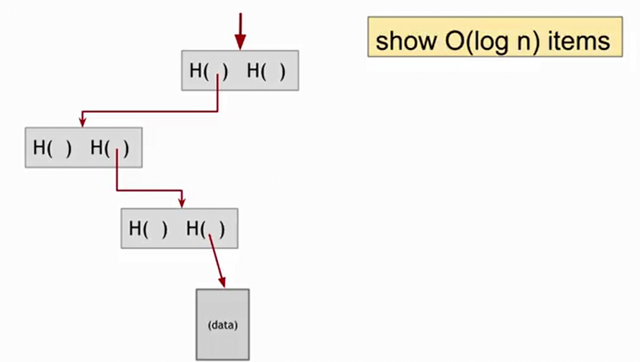
It is enough to check all the hashes of the path from the bottom of the tree till the root. So that takes about $$log_{2}n$$ items that we need to verify, and it takes about $$O(log_{2}n)$$ time for us to verify it. And so, even if there's a large number of data blocks in the Merkle tree, we can verify proven membership in a relatively short time.
Conclusions
So Merkle trees have various advantages:
- the tree holds many items but we just need to remember the one root hash (only 256-bits)
- we can verify membership in a Merkle tree in logarithmic time and logarithmic space
Sorted Merkle tree to prove non-membership
A variant of Merkle Tree is a sorted Merkle tree. In this kind of tree, we take the data blocks at the bottom and we sort them into some order. Say alphabetical, lexicographic, numeric order or some order that we agree on. Once we've sorted the Merkle tree, we can prove that a particular block is not in the Merkle tree.
We can do that simply by showing a path to the item that's just before where that item would be and just after where it would be. And then we can prove that both of these items are in the Merkle tree are consecutive. Therefore there is no space in between them for the element we are searching. So even non-membership proofs in sorted Merkle tree is very efficient.
General application of Hash pointer to Data Structures
It turns out that we can use hash pointers in any pointer-based data structure as long as the data structure doesn't have cycles. If there are cycles, we won't be able to make all hashes match up.
In fact, in an acyclic data structure, we can sort starting from the leaves or near the tail that don't have any pointers coming out of them, compute the hashes of those and then work our way back, towards the beginning. But in a structure with cycles, there's no end that we can start with and compute back from.
For example, a directed acyclic graph can be constructed using hash pointers and we'll be able to verify membership very efficiently. This is a general trick we will see over and over throughout the distributed data structures and the algorithms that we will talk about during the course.