Expected GPU Magnitude Update (17-2-2018)
Over the last week I have been working on improving the estimates for expected magnitude generated by my scripts by incorporating task data downloaded from the project websites. This has been proving more difficult than anticipated, due to inconsistent reporting of CPU time between projects and contradictions in which CPUs get assigned multi-threaded tasks (i.e. YAFU assigning a quad core CPU 16 thread work units).
After a week filled with frustration I decided to give up on adding task data to the CPU tables for now and move on to the GPU tables. Luckily this went much smoother. Top hosts where determined using the method from my previous script. The task data for these hosts where downloaded. The task data was used to calculate credit/second by dividing the credits for each task by the wall time. This was then used to calculate an estimate of the magnitude.
Today we also have a special table that is just for fun… server and prosumer GPUs
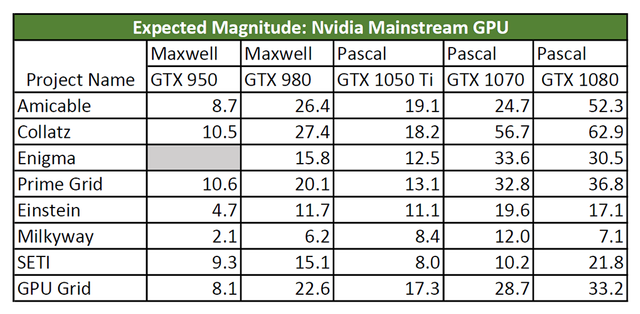
Results: Nvidia
The usual project advice applies here.
- Run the PPS-sieve subproject on PrimeGrid .
- Running CUDA tasks on Enigma requires Windows
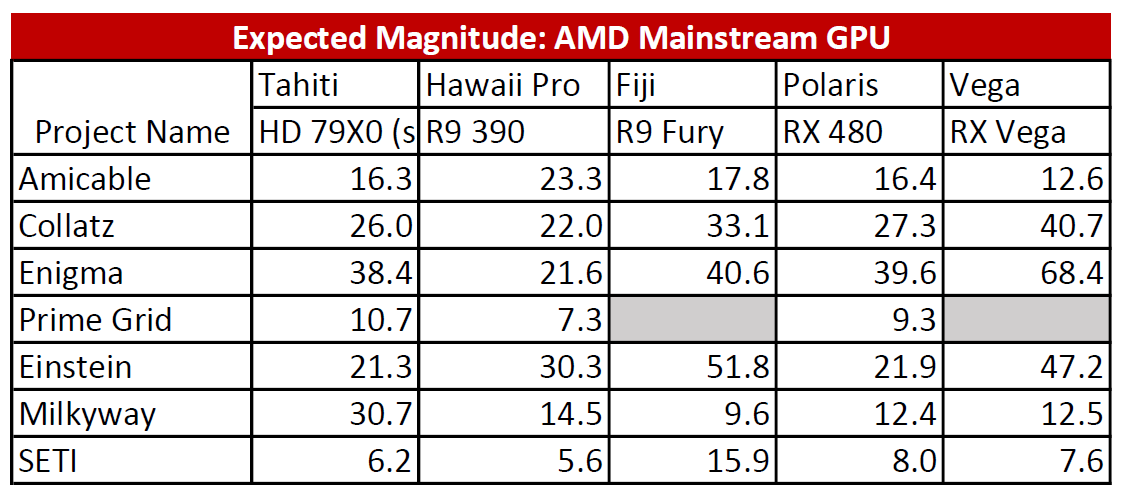
Results: AMD
And the standard AMD advice:
- Run Milkyway if you have a GPU using the Tahiti architecture (including the R9 280/280x)
- GPU Grid requires CUDA (Nvidia)
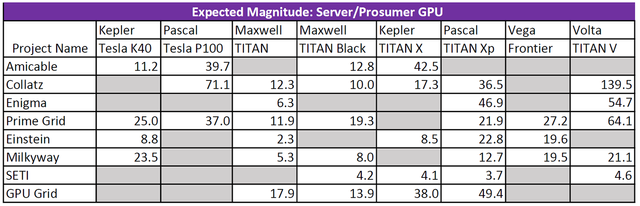
Results: Server/Prosumer
This section is just for fun. There isn't nearly enough data to say whether or not these number are accurate. Just knowing that someone is using them for BOINC projects is ridiculously awesome.
I would get a higher mag running Enigma on my 280x than by running Milkyway?
Nice catch. It looks like task data and highest RAC methods are giving inconsistent results for that case.
For Milkyway Tahiti
Highest Rac: 45 Mag
For Enigma Tahiti
Highest Rac: 38Mag
The script that you are running, is it public? Would like to be able to run monthly to see stats for my GPU .
The script is not currently public. The goal is to post the code when I'm confident that the results given by the current code don't need to be compared to other methods of estimating the RAC to validate the results.
Some problems with the current method have been pointed out, so the code is in for a near total rewrite (again) before the next update.
Very good overview @nexusprime.
Do these numbers scale when having more GPUs in one system? For example, if I have 2 GTX1080 running Einstein, will my system reach a magnitude of 2 x 17.1 = 34.2?
I ran some checks while writing the code to make sure I could use tasks from machines with multiple of the same GPU. I'm fairly certain that it scales, assuming both GPUs are fully utilized and their are not thermal issues.
Some computer specs are reported (on projects websites) as
What I assume it means rig has 2 cards installed, at least one is 970.
This computer has 2 cards and running times either ~1000s or ~3000s. I guess 1000s might be for GTX 970 and 3000s for a weaker card, as times on e@h are consistent and my 1060 takes ~1000s for a task.
Thus listed card is probably the fastest one or random, as it always shows GTX 970 for this computer.
I've checked manually only a handful of entries for my articles to make sure I check computers with only one card installed.
How did you solve this problem for your statistic?
[Coprocessors: [2] NVIDIA GeForce GTX 970 -> means that there are 2 GTX 970s installed
Mixing different cards from the same company is rare but they should appear as
[coprocs][BOINC|7.6.33][CUDA|GeForce GTX 780|1|3072MB|37892][CUDA|GeForce GTX 770|1|2048MB|35286][/coprocs]
in the host file.
Though that data from Einstein does look suspicious. I also ran the code a separate time only allowing for machines with one GPU and obtained close to the same results. But I may go back to limiting the results to machines with only one GPU.
I always remove machines that have multiple flags for CUDA (Nvidia), multiple flags for CAL (AMD), or both flags.
Thanks, informative.
It seems some projects report in different ways, at least on the website, as I haven't checked host files. Amicable and e@h it seems lists only name for 1 card, unlike asteroids (see @parejan comment). As tasks at e@h take the same time to finish (+/- 5%) I would be surprised if they are both 970s, as this computer takes either ~1000s or ~3000s to solve a task. Unless one card would be severely starved of some resources and the other not.
Thanks for pointing this out. Definitely something to watch.
Though I do wish that e@h (and yoyo) would use the
standardcurrent version of the website. It would make the analysis work a lot easier.I guess they are really 2 GTX970's in one system.
Have a look at these systems:
http://www.asteroidsathome.net/boinc/show_host_detail.php?hostid=26048
http://www.asteroidsathome.net/boinc/show_host_detail.php?hostid=100737
http://www.asteroidsathome.net/boinc/show_host_detail.php?hostid=240829
where you have different combinations of GPUs.
Nevertheless and interesting aspect to understand.
Amicable and e@h it seems lists only name for 1 card, unlike asteroids. As tasks at e@h take the same time to finish (+/- 5%) I would be surprised if they are both 970s, as this computer takes either ~1000s or ~3000s to solve a task.
Interesting. All these projects are on different versions of BOINC software, which probablity doesn't help here to obtain the same level of information.
It is quite depressing to see Titan V (and other prosumer cards) perform so badly on Milkyway. That project should really try to optimize their tasks for these cards, especially for Titan V as this card has a good FP64 support IIRC.
There are some issues with how this measurement works and the fact that there are only a few examples. Additionally high end cards tend to run multiple work units at the same time, which I failed to account for properly. It is mostly an issue for milkyway. which is the primary FP64 project. Hopefully I can fix this in the next version. Here are some more accurate results for Titan V: https://steemit.com/gridcoin/@cautilus/my-quest-to-use-an-nvidia-titan-v-for-boinc-titan-v-and-1080-ti-boinc-benchmarks