Update to the Gridcoin Reward Mechanism Proposal
Abstract
A revised version of the proposed research reward mechanism described in [1] is presented. The updates to the mechanism are in response to real-world conditions that limit the normalization process between different hardwares on different project applications. Advantages and disadvantages of the proposal are discussed, as well as the feasibility of implementation.
Acknowledgements
In addition to everyone mentioned in the original proposal, I would like to thank again @jamescowens, especially for conversations regarding how to store the information required to implement this proposal, as well as @cycy, especially for help navigating through BOINC's source code and providing his WU data for analysis.
Description and Benefits of the Proposal
The proposal (both the revised and original ones) can be summarized as considering the Gridcoin network to be one massive supercomputer, and rewarding crunchers with GRC proportional to their processing power contribution.
Reasons for changing the incentive structure to this proposal include:
- This proposal relieves the network of necessarily allocating the same amount of GRC to each project
- As a consequence of (1) and by design, it eliminates the same type of hardware receiving vastly different rewards on different projects
- The GRC minting mechanism can be scaled in an intelligent fashion
- Since the normalization is constructed from hardware/project pair data, it allows us to introduce non-BOINC based distributed computing paradigms
- The normalization ties the minting of GRC to two important units: FLOPs and Joules (computing power and energy consumption)
- The information from (5) allows for data analysis that can improve the efficiency of the network
- A more robust project greylisting mechanism can be implemented, since the network can more precisely measure computing power vs. available WUs
- A much more accurate total network computing power for both Gridcoin and BOINC can be calculated
- The possibility for a GRC/green energy exchange market where crunchers can offset their carbon emissions becomes much more realistic, as described in [2]
- The proposal necessitates the creation of a hardware profiling database, the benefits of which are also described in [1]
Revised Proposal
Changes
The basis of the Equivalence Ratio (ER) described in [1] has been switched from Total Credit Delta (TCD) to Recent Average Credit (RAC), which is the current WU contribution measurement for BOINC.
The main reasons for sticking with RAC are (quoting from @jamescowens):
- It [TCD] makes us much more susceptible to credit hacks, because the RAC has a charge up halflife of 7 days and so blunts a magnitude play.
- Projects sometimes rollback credits for various reasons... difficult to deal properly with that.
- It [TCD] introduces an instability between the SB intervals to calculate the rewards and the actual points the stats are sampled. RAC can be thought of as essentially a "rate", because it is smoothed, whereas TCD is a point in time value. If you are incorporating 6 hour old TCD's from one of the projects in the SB, you are not using an accurate basis for TCD incorporation in the SB.
The original pseudocode for the method based on TCD can be found in the Appendix - the new one is presented below. Changes from the old pseudocode include:
- M = |H| x |A|, where H is the same, and A is the set of projects, no longer the set of project applications
- W = |B| x |A|, where B is the same, and A is modified as above
- N = |B| x |A|, where B is the same, and A is modified as in M and W
Pseudocode

Runtime Analysis
Under realistic conditions where the rate of growth of the number of projects and number of types of hardwares are significantly outpaced by the rate of growth of the number of beacons, this algorithm runs in O(|B|) time. Ignoring the outer superblock loop:
the first for loop has |A| x [ (1x|H| matrix) x (|H|x1 matrix) ] calculations - a scalar times a vector product. Since the vector product is determined by |H|, which in practice will not grow enough to justify considering it a variable, the runtime is O(|A|x|H|) = O(1).
the second nested for loop has |B| x |A| multiplications, so the runtime is O(|B|).
the third for loop has |B| x |A| calculations, so the runtime is O(|B|).
Thus, the overall runtime is O(|B|) - i.e. it is linear in the number of beacons participating in the network.
Impact of the Changes
Compared to the original proposal, for the everyday/consistent cruncher, the reward allocation will not be much different; in the limit of time, the rewards would be the same either way. In the Appendix is a modification of the C++ code to calculate RAC from the old BOINC wiki (also see @jamescowens' treatment of RAC, or one of the many others available). It becomes clear from this simulation that the RAC of any single host/project pair as it approaches its asymptotic maximum is equal to the maximum number of credits that the host can crunch in 24 hours. In other words, there is a linear mapping between "maximum" RAC and WU/time, the latter of which is the basis for creating the ER. Thus, this new proposal based on RAC maintains that crucial aspect of the ER; however...
A game-theoretic issue arises out of using RAC over TCD - crunchers may be able to increase their rewards by jumping from project to project. This is currently the case as well, and it is unknown whether adopting this proposal will mitigate, exacerbate, or leave untouched this exploit. This can be analyzed if the community so desires.
The crunchers of projects that have comparatively lower processing power will no longer receive disproportionately higher rewards. This effectively eliminates the artificial economic incentive to crunch smaller projects. After discussing the possibilities for maintaining an artificial incentive to crunch smaller projects, @jamescowens proposed the following solution: effectively, designate a certain percentage of the network's total computing power to be evenly spread amongst all projects; if any project(s) receive(s) less than the intended amount, proportionally subtract rewards from the project(s) that exceed(s) the intended amount, and proportionally add rewards to the project(s) that received less than the intended amount. The community would decide whether or not it wants to implement this mechanism.
There is a slight problem that arises out of using RAC - the ER no longer normalizes credits across applications, but rather across entire projects. The granted credits of application WUs are supposed to be proportional to their running time within projects, but this is almost certainly not the case because 1) of the inherent capabilities of some hardware relative to others, and 2) projects may not have normalized their applications even on a single machine. This casts doubt on the accuracy of WU proportionality within a project, and it will impact the accuracy of the ER. However, after a thorough investigation, normalizing across applications is not possible at this moment, although it can be with the proper PRs put in to BOINC.
This last point warrants further discussion, and provides a useful bridge to explain how the data to construct the matrix M will be collected.
How is M built?
The host statistics export files, which all projects have available, contain much of the relevant information needed to construct M - see the Appendix for an example of such a file. In particular, the expavg_credit field is determined by the same code that was used to create the aforementioned modified RAC code. The credit_per_cpu_sec field is deprecated, although would provide useful information if it was not. The expavg_credit field in conjunction with the p_model field is enough to construct M.
While the host statistics export files contain sufficient information to construct M as described in this current proposal, they are missing key information necessary to construct the matrix M on a per application basis as described in the original proposal - namely, the RAC per application. After going through the BOINC source code (many thanks to @cycy for help navigating through it), it seems like it would be necessary to submit a PR to BOINC to actually be able to obtain such information.
A good example of a file that would provide such data is the WU information file provided by World Community Grid - see the Appendix for an example. Below is a histogram of the WU/time of different hardwares crunching different applications of WCG (many thanks to @cycy for providing this data):
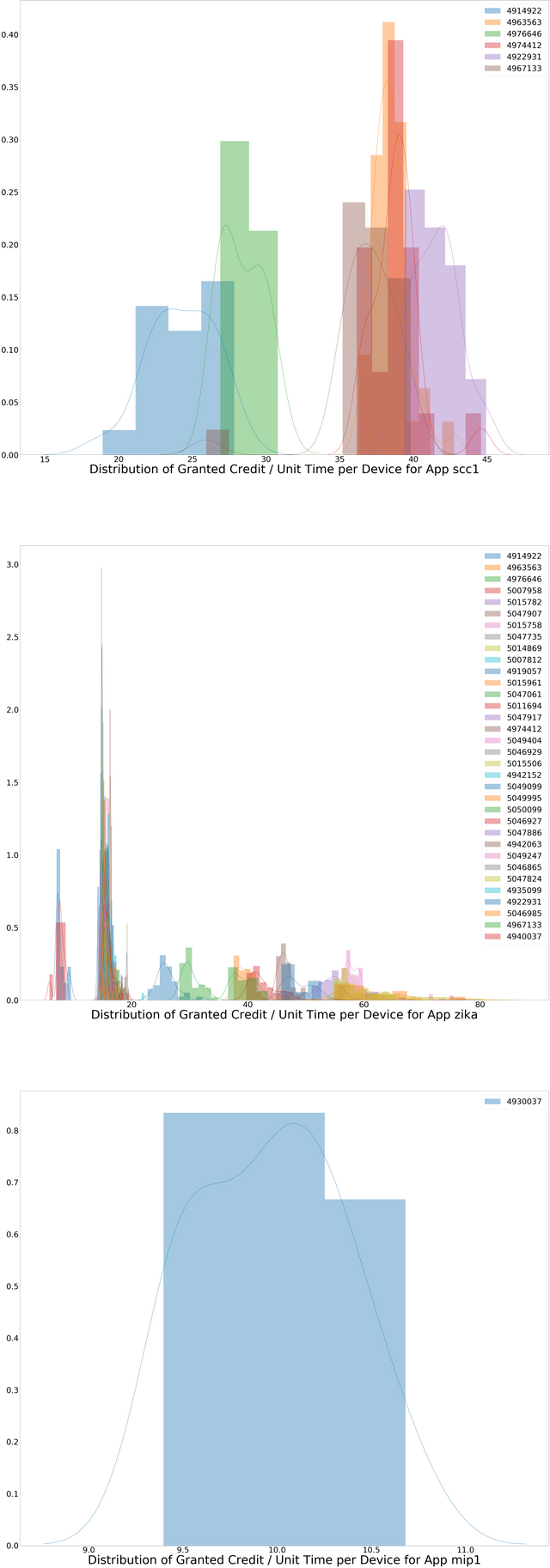
As can be seen from this histogram, some sort of selection rule must be devised to determine how to choose a single number for the WU/time of a hardware/application pair (this also applies to the hardware/project pair in the current proposal).
Since the expavg_credit in the host statistics export files field is a reflection of the RAC, it will change over time; furthermore, if a host is not reaching its maximum RAC, this value will not reflect the maximum WU/time that is required to construct the matrix M. A simple approach would be to take the maximum value of expavg_credit for any hardware/project pair, but this is likely insufficient for a number of reasons and such a rule must be carefully chosen.
Feasibility of Implementation
The primary piece of information that must be agreed upon by the network is the matrix M described in the pseudocode. Extensive conversations with @jamescowens and @cycy concluded with the fact that this matrix can be stored, and cross-verified, using similar methods to those currently used by the new scraper for statistics collection. The exact details by which the nodes converge to the same M must be discussed, but these are technical details that do not affect the viability of the proposal.
Conclusion
An updated GRC reward mechanism would have many benefits for the network, including rewards more closely associated with actual computing power contributions, the ability to improve the efficiency of the network, and the opportunity to create a GRC/green energy exchange to offset the carbon emissions from crunchers' hardware. This proposal can also bring the Gridcoin community closer to BOINC by helping to improve BOINC's source code, as well as attract non-Gridcoin BOINCers to Gridcoin with these new features as well as new, exciting opportunities enabled by this proposal.
References
[1] Internal Hardware Optimization, Hardware Profiling Database, and Dynamic Work Unit Normalization
Appendix
Pseudocode for Original Proposal

Modified RAC Code
The original code can be found here. A main function and a fake time counter were added to the original to make the code suitable for simulations.
#include <iostream>
#include <math.h>
#define SECONDS_PER_DAY 86400
using namespace std;
void update_average (
double work_start_time, // when new work was started // (or zero if no new work)
double work, // amount of new work
double half_life,
double& avg, // average work per day (in and out)
double& avg_time, // when average was last computed
double& fakeTime // new, for simulations
) {
//double now = dtime();
double now = fakeTime;
if (avg_time) {
double diff, diff_days, weight;
diff = now - avg_time;
if (diff<0) diff=0;
diff_days = diff/SECONDS_PER_DAY;
weight = exp(-diff*M_LN2/half_life);
avg *= weight;
if ((1.0-weight) > 1.e-6) {
avg += (1-weight)*(work/diff_days);
} else {
avg += M_LN2*work*SECONDS_PER_DAY/half_life;
}
}
else if (work) {
// If first time, average is just work/duration
//
cout << "avg_time = " << avg_time << "\n";
cout << "now = " << now << "\n";
double dd = (now - work_start_time)/SECONDS_PER_DAY;
avg = work/dd;
}
avg_time = now;
}
int main() {
double RAC = 0;
double timeOne = 1;
double timeTwo = 1;
double totalCredit = 0;
double timeInterval = 3600; // new; time in seconds between each RAC update
double work_start_time = 0; // when new work was started // (or zero if no new work)
double work = 200; // amount of new work
double half_life = 604800;
double& avg = RAC; // average work per day (in and out)
double& avg_time = timeOne; // when average was last computed
double& fakeTime = timeTwo; // new; for simulation
for (int i=0; i<1500; i++) {
if (1) {
if (i % 24 == 0) {
cout<<"week " << i/168 + 1 << ", day " << (i/24)%7 + 1 << "; current hour = " << i << "; ";
cout<<"totalCredit = " << totalCredit << "; ";
//cout<<"fakeTime = " << fakeTime << "; ";
cout<<"RAC = "<< RAC << "\n";
}
}
fakeTime += timeInterval;
update_average(work_start_time, work, half_life, avg, avg_time, fakeTime);
totalCredit += work;
}
cout<<"Final totalCredit = " << totalCredit << "\n";
cout<<"Final fakeTime = " << fakeTime << "\n";
cout<<"Final RAC = "<< RAC;
return 0;
}
Example of a Host Statistics Export File
<host>
<id>10</id>
<userid>641059</userid>
<total_credit>823243.112985</total_credit>
<expavg_credit>0.071538</expavg_credit>
<expavg_time>1333480853.984610</expavg_time>
<p_vendor>GenuineIntel</p_vendor>
<p_model>Intel(R) Core(TM) i7 CPU 950 @ 3.07GHz [Family 6 Model 26 Stepping 5]</p_model>
<os_name>Microsoft Windows 7</os_name>
<os_version>x64 Edition, (06.01.7600.00)</os_version>
<coprocs>[BOINC|6.10.58][CUDA|GeForce GTX 460|1|1023MB|30448]</coprocs>
<create_time>1086269299</create_time>
<rpc_time>1347796849</rpc_time>
<timezone>7200</timezone>
<ncpus>8</ncpus>
<p_fpops>2230397818.915570</p_fpops>
<p_iops>8494754137.090450</p_iops>
<p_membw>125000000.000000</p_membw>
<m_nbytes>12882857984.000000</m_nbytes>
<m_cache>262144.000000</m_cache>
<m_swap>17175875584.000000</m_swap>
<d_total>159939297280.000000</d_total>
<d_free>35758538752.000000</d_free>
<n_bwup>75689.857377</n_bwup>
<n_bwdown>107630.036610</n_bwdown>
<avg_turnaround>95433.503340</avg_turnaround>
<credit_per_cpu_sec>0.056947</credit_per_cpu_sec>
<host_cpid>1cf9941bde51c9743b1f0e63a96e74a3</host_cpid>
</host>
Example of World Community Grid WU File
{"ResultsStatus": {
"ResultsAvailable": "2586",
"ResultsReturned": "100",
"Offset": "0",
"Results": [
{
"AppName": "zika",
"ClaimedCredit": 75.43766926617201,
"CpuTime": 1.6173177777777779,
"ElapsedTime": 1.6184435683333331,
"ExitStatus": 0,
"GrantedCredit": 75.43766926617201,
"DeviceId": 5007958,
"ModTime": 1555951087,
"WorkunitId": 1087822805,
"ResultId": 928128208,
"Name": "ZIKA_000420711_x5k6k_ZIKV_NS1_MD_model_5_s2_0097_0",
"Outcome": 1,
"ReceivedTime": "2019-04-22T16:38:01",
"ReportDeadline": "2019-05-02T12:06:23",
"SentTime": "2019-04-22T12:06:23",
"ServerState": 5,
"ValidateState": 1,
"FileDeleteState": 0
},
...
]
}
}
Sounds good. But I also foresee "little" projects being abandoned. As there is no GRC "incentive" for them, crunchers would focus on own preferences.
Myself is crunching TNGrid because of "high" reward, we are a few around the world. Just imagine they loose 100 crunchers....little projects are "dead".
Just my opinion.
Good comment @javierf and maybe this can be taken into consideration setting up the reward system.
In order to address that problem, we discussed ways to incentivize crunching smaller projects if they fall below a certain threshold; that solution is discussed in the third point of the "Impact of the Changes" section.
However, I'd like to point out a few things:
Personally, I advocate for total normalization without artificial incentives - I think that there are other ways to incentivize people to crunch smaller projects than the incentives that we currently have in place.
However, I understand that others in our community do not agree, and that's what the compromise was intended to address - there is still a way to economically incentivize crunching smaller projects whilst also dropping our current reward mechanism in favor of the one that I'm proposing. For that reason, I don't think that this issue affects the viability or desirability of adopting this proposal, since it also has many other benefits.
I just used TNGrid as an example. Even though that 46% sounds great, and, as per prorject's status site, total number of users today is 600. Lets imagine Gridcoin is half, which would leave project with 300 hosts...which sounds to me an almost "dead" project. Just compare with SETI or LHC. If GRC incentive moved 1% of gridcoin RAC to TNGrid, project would end "tomorrow".
I dont like artificial manipulation of the incentives. However, the word "incentive" itself needs to be helpful for projects needing it.
Fair enough. Ultimately the decision would have to be voted on, and it's certainly within our power to maintain some sort of artificial incentive to crunch smaller projects if that's what we decide we want. Alternatively, we might find other ways to make sure that projects get the crunching power they need - like developing a tool that allows new users to spread their processing power equally across all projects (or something like that), or increasing education efforts so that crunchers know about the importance of the smaller projects. In general, I think that eliminating the artificial incentives eliminates a huge distraction from the actual projects themselves, which is actually one of the reasons I started writing on this topic (I mentioned this in my earliest posts regarding Gridcoin's incentive mechanism).
Thanks for the update @ilikechocolate.
I understand that your proposal might not be perfect but from where we are now this would be a big step forward.
Personally I see the magnitude calibration between teams as critical. I moved recently with my laptop from WCG to Yoyo and my magnitude jumped 500%, which is too much.
Looking forward to see the next steps.
Thank you :)
This is a really cool idea, even if it could take away incentives to explore/crunch lesser known projects. Ideally we could even use this sort of system to encourage people to retire super old systems.
(e.g. there are still 450 Pentium 4 systems actively running BOINC)
However, there are bunch of annoying issues that I've come across while working on QuickMag, that could present serious problems for calculating M fairly.
Potential Issues:
All good points. In order:
coprocswas that bad, I'll have to think about that more. When the process is a bit further along it would be great to have your insight.Congratulations @ilikechocolate! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPVote for @Steemitboard as a witness to get one more award and increased upvotes!
Congratulations @ilikechocolate! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Vote for @Steemitboard as a witness to get one more award and increased upvotes!