Éviter le contournement de récompense sur les systèmes d’intelligence artificielle

Lorsque nous créons une technologie dotée d’intelligence, nous sommes parfois confrontés à certains problèmes. En effet, lorsque nous réalisons un système intelligent qui répond à un besoin, il se peut que les résultats obtenus ne sont pas ceux que nous espérons. Cela peut s’expliquer par un hack de la fonction de récompense. Beaucoup de systèmes utilisent une fonction de récompense permettant de définir le problème à résoudre et la manière dont notre système doit résoudre ce dernier. Ainsi, l’objectif du système intelligent est de maximiser cette fonction de récompense. En effet, plus la récompense est importante, plus le système sait que sa résolution de la tâche est correcte.
Contournement de la fonction de récompense
Le contournement de la fonction de récompense est un contournement réalisé par notre système intelligent. En effet, pour résoudre un problème complexe, il se peut que notre système découvre un autre moyen plus performant pour réaliser sa tâche. Cependant, cette autre méthode n’est pas valable. Cela est dû à une mauvaise définition de notre problème. Ainsi, ce hack est dû à une conception informelle de notre fonction de récompense. Or, cela peut avoir de graves conséquences sur notre environnement. En effet, notre système intelligent pense que sa manière de résoudre le problème est valide et il va continuer dans cette direction. Les conséquences sont donc empiriques. De plus, avec l’évolution de la technologie, nous avons à notre disposition davantage de puissance de calcul et nous pouvons désormais réaliser des systèmes toujours plus complexe. Cependant, plus le système est complexe, et plus l’apparition de ces hacks vont survenir et ce sera de plus en plus compliqué pour nous de comprendre comment ils apparaissent.
Pour illustrer le hack de la fonction de récompense, nous pouvons faire le lien avec l’expérience réaliser par Olds et Milner sur le circuit de récompense dans le cerveau. Dans cette expérience, une souris peut appuyer sur un bouton et déclencher une stimulation dans la zone du cerveau qui corresponds à la zone du plaisir. Ainsi, la souris va chercher à appuyer sur le bouton alors que normalement, elle va chercher à manger afin d’obtenir cette sensation de récompense. On voit ici un hack de notre fonction du plaisir de notre cerveau. On ne cherche plus à répondre à un besoin primaire, ici manger, on cherche à se faire plaisir (maximiser notre récompense). Ceci nous permet de faire un lien avec notre système intelligent. Nous allons nous intérressé à certain hack qui ont été abordé dans l’article de « Concrete Problems in AI Safety » écrit par Amodei D., Olah C., Steinhardt J., Christiano P., Schulman J. and Mané D. (2016)
Objectif partiellement observé
Lorsque l’on souhaite réaliser un système intelligent, l’un des premiers problèmes auxquels nous faisons face et de définir notre environnement pour notre système. C’est une tâche qui nous demande du temps, mais aussi qui peut provoquer des problèmes pour notre agent, car c’est sur cette représentation qu’il va baser son analyse et donc ces actions. Cela est d’autant plus vrai dans le cas d’un apprentissage par renforcement, ou nous allons chercher et évaluer les meilleures actions à réaliser en fonction de notre environnement. En effet, la perception de notre agent sur notre environnement est limitée. Si nous prenons le cas d’un robot aspirateur qui souhaite nettoyer le sol de notre maison, nous pouvons imaginer que sa fonction de récompense et de voir le moins possible de saletés dans la maison. L’un des problèmes que nous allons rencontrer est que les perceptions visuelles de notre robot vont être limitées, car nous n’avons pas de moyen afin de mesurer par exemple la saleté d’une maison. Enfin, l’autre problème que nous pouvons rencontrer est dû à la fonction de récompense que nous avons définie. En effet, le robot peut décider de fermer les yeux ou de se bloquer volontairement la vue lui permettant d’avoir une récompense maximale, à savoir ne pas voir de saleté dans la maison.
Systèmes complexes
La complexité d’un programme influe sur la probabilité d’avoir des bugs dans notre système. Ainsi, plus un système est complexe et plus nous avons un éventail de hack possible. En effet, nous aurons davantage d’actions et donc davantage de stratégies différentes qui seront réalisables pour notre système. Plus le nombre d’actions est important et plus le nombre de conséquences le sera aussi. Cependant, cela peut aussi être dû aux paramètr es que nous prenons en compte lors de la prédiction d’une action. En effet, en fonction de certaines valeurs ou en fonction d’une certaine condition, nous pouvons aussi retrouver des bugs. On privilégiera un système qui suit le principe du rasoir d’Ockham. Ce principe est que si nous devons choisir entre deux systèmes réalisant les mêmes tâches, il faudra choisir celui qui est le moins complexe.
Récompense abstraite
Les fonctions de récompenses complexes ont besoin de se référer à des concepts abstrait afin de pouvoir réaliser une prédiction ou choisir une action à prendre en compte. Pour illustrer cela, nous pouvons prendre les systèmes de réseaux de neurones. Cependant, ces derniers ont parfois des problèmes et peuvent être hacker. Cela est notamment le cas, lorsque nous avons une image et que nous insérons un bruit dans cette dernière. Ainsi, on peut transformer une image de panda en une image de gibbon, comme vous pouvez le constater avec l’image ci-dessous. C’est une attaque par contre-exemple contradictoire (adversarial counterexemple).
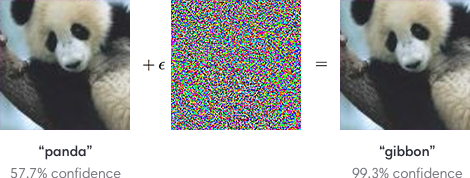
Source : https://openai.com/content/images/2017/02/adversarial_img_1.png
{kind=link}
Nous pouvons aussi avoir des problèmes avec notre fonction de récompense lorsque nous avons une fonction de récompense qui possède plusieurs dimensions. En effet, si une des valeurs que nous donnons est anormalement haute, cela peut poser problème pour notre système, car il ne saura pas comment la gérer.
Loi de Goodhart
Dans un premier temps, nous allons définir la loi de Goodhart. Cette dernière indique que lorsqu’une mesure devient un objectif, alors elle cesse d’être une bonne mesure. Pour illustrer cela, nous pouvons prendre le cas d’un robot qui nettoie le sol. Si on base notre étude sur la consommation d’eau de javel pour dire si notre robot a bien réalisé son travail, alors il suffit au robot de verser de l’eau de javel dans les égouts afin d’obtenir de bon résultat.
Récompense de la part de environnement
Lorsque nous attribuons une récompense à notre agent à partir de notre environnement, par exemple dans les systèmes d’apprentissage par renforcement, nous allons devoir calculer le score pour chacune des actions possibles. Cependant, dans cette approche, nous allons chercher à sélectionner la meilleure série d’actions possibles. Ainsi, rien empêche à notre système de manipuler ce score en fonction de comment ce dernier est implémenté dans notre système. Cela est notamment le cas lorsque nous avons un humain qui intervient lors de l’attribution des récompenses pour notre système.
Conclusion
Tout au long de cet article, nous avons pu visualiser certains contournements de la fonction de récompense dans les systèmes qui implémente une intelligence artificielle. Ce contournement peut mener à une exploitation de ces failles comme on pourrait le retrouver dans les jeux vidéo à travers des glitchs. De plus, ces failles peuvent être très difficiles à trouver, notamment dans des systèmes complexes et profonds. D’autre part, une fois qu’un agent à réussi à trouver un contournement dans sa fonction de récompense, il ne sera pas enclin à arrêter. Cela peut-être problématique lorsque nous utilisons un agent intelligent sur le long terme, car les conséquences peuvent être désastreuses.
Sources
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J. and Mané, D. (2016). Concrete Problems in AI Safety. [online] arXiv.org. Available at: https://arxiv.org/abs/1606.06565
https://fr.wikipedia.org/wiki/Rasoir_d%27Ockham
https://openai.com/blog/adversarial-example-research/
Lien original : https://www.technologieintelligente.fr/intelligence-artificielle/securite/eviter-le-contournement-de-recompense-sur-les-systemes-dintelligence-artificielle/
Article sur un sujet intéressant mais trop méconnu !
C'est vrai que lorsque nous parlons d'intelligence artificielle, nous sommes fascinés par les résultats, mais on ne pense pas, dès le départ, à créer un système sécurisé. Le point de la sécurité doit, à mon avis, être primordiale, car si nous n'avons pas confiance à un système, même s'il est performant, personne ne voudra l'utiliser.
Ce post a été supporté par notre initiative de curation francophone @fr-stars.
Rendez-vous sur notre serveur Discord pour plus d'informations
Félicitations ! Votre publication a été sélectionnée par @kaliangel pour sa qualité et a été upvotée par le trail de curation de @aidefr !
La catégorie du jour était : #informatique
Si vous voulez aider le projet, vous pouvez rejoindre le trail de curation ici!
Bonne continuation !
Rendez-vous sur le nouveau site web de FrancoPartages ! https://francopartages.xyz
This post has been voted on by the SteemSTEM curation team and voting trail. It is elligible for support from @curie.
If you appreciate the work we are doing, then consider supporting our witness stem.witness. Additional witness support to the curie witness would be appreciated as well.
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Please consider setting @steemstem as a beneficiary to your post to get a stronger support.
Please consider using the steemstem.io app to get a stronger support.