Générer une voix à partir d'audio - WaveNet

Les progrès de la technologie, notamment dans le domaine de l'intelligence artificielle, nous pousse à reproduire les facultés humaines telles que la voix. Ainsi, il nous est désormais possible, à partir d'enregistrements d'une voix d'une personne, de la reproduire. Différents systèmes existent dont WaveNet. Dans cet article, nous allons chercher à comprendre le fonctionnement de ce système.
Réalisation avec l'architecture WaveNet.Source : https://deepmind.com/blog/wavenet-generative-model-raw-audio/
Les enregistrements audios
Afin de pouvoir réaliser notre système, nous allons avoir besoin de données. Ainsi, nous allons utiliser des enregistrements audios de personnes qui parlent. Pour chacun de ces enregistrements, nous allons avoir la transcription écrite de ce qui est dit.
L'un des premiers problèmes que nous faisons face est comment extraire les informations d'un signal audio. En effet, un signal audio de fréquence fixé à 44,1 kilohertz, a une valeur numérique codée sur 16 bits ayant donc pour valeur -32 768 et +32 767. De plus, la fréquence d’échantillonnage va participer à la qualité de l'audio, mais va rajouter davantage d'information. Ainsi, au lieu d'étudier chacun des points indépendamment, nous allons utiliser un modèle simplifiant cette démarche. Ainsi, pour le modèle WaveNet, un réseau de convolutions dilatées est utilisé. Ce type de réseau va nous permettre de réduire le nombre de calculs à réaliser tout en gardant une qualité de traitement suffisante. En effet, si nous regardons la figure ci-dessous, nous pouvons nous apercevoir du nombre de points présents et ainsi du nombre de calculs à réaliser si nous devons prendre chacun des points indépendamment.

Aperçu d'un enregistrement sonore.
Source : https://medium.com/@evinpinar/wavenet-implementation-and-experiments-2d2ee57105d5
Architecture de WaveNet
L'architecture de WaveNet est composée de plusieurs résidus réalisant des opérations bien précises. De plus, WaveNet fait intervenir des convolutions dilatées. Nous allons dans un premier temps, essayer de comprendre les convolutions dilatées.
Convolution dilatée - Dilated Convolution
Dans une convolution classique, nous parcourons l'ensemble de notre image avec un filtre. Ce filtre est consistant, c'est-à-dire qu'il forme un bloc. Dans le cas d'une convolution dilatée, le filtre s'est dilaté laissant des espaces lors de la prise des valeurs, comme vous pouvez le constater à l'aide de la figure ci-dessous. Ainsi, dans cette configuration, nous diminuons le nombre de calculs, mais nous réduisons aussi l'information que nous prenons en compte. En effet, dans une convolution classique, la matrice de sortie que nous obtenons est plus conséquente. De plus, elle détaille davantage les informations liées aux blocs qui se juxtaposent contrairement à une convolution dilatée.

Animation d'une convolution dilatée.
Source : https://towardsdatascience.com/review-dilated-convolution-semantic-segmentation-9d5a5bd768f5
Implémentation des convolutions dilatées
Dans le cas classique d'une convolution, nous aurions eu un système tel que nous pouvons le voir à l'aide de la figure ci-dessous.

Ici, nous cherchons à prédire la nouvelle valeur en nous basant sur les 5 dernières entrées.
Source : https://medium.com/@evinpinar/wavenet-implementation-and-experiments-2d2ee57105d5
Sur cette figure, l'ensemble des couches cachées interviennent dans le traitement. Cependant, avec l'implémentation d'un système de convolutions dilatées, seul certain nœud présent dans les couches cachées intervient. Vous pouvez visualiser cela à l'aide de la figure ci-dessous.

Utilisation de convolutions dilatées, avec une taille de réception de 16.
Source : https://medium.com/@evinpinar/wavenet-implementation-and-experiments-2d2ee57105d5
Comme vous avez pu vous en rendre compte, une convolution dilatée nous permet de prendre davantage de données, tout en ayant un nombre de calculs moindre par rapport à une convolution classique.
Modèle récurrent
Lors de l'étude d'un signal audio, les anciennes fréquences ont une influence sur le son. Ainsi, notre modèle doit s'appuyer sur les anciens résultats afin de déterminer la prochaine fréquence. Nous devons donc mettre en place un réseau récurrent, c'est-à-dire un réseau qui prend en compte la dernière prédiction réalisée. Ainsi, la valeur prédite devient une valeur d'entrée à la prochaine itération.
Ainsi, pour prédire une nouvelle valeur, nous allons nous appuyer sur toutes les anciennes valeurs d'entrée de notre donnée. Nous pouvons écrire cela sous la forme d'une équation :
Ici, T représente l'ensemble des valeurs que nous allons prendre en considération. Et x représente l'ensemble des entrées. Ainsi, sur notre modèle, nous aurons :

Architecture de WaveNet.
Source : https://medium.com/@evinpinar/wavenet-implementation-and-experiments-2d2ee57105d5
Description des résidus
Chacun des nœuds présents dans notre réseau va réaliser plusieurs opérations. Pour illustrer notre discours, vous pouvez suivre avec le schéma ci-dessous. Nous allons nous intéresser à la partie gauche du schéma. En effet, la partie droite représente le dernier nœud nous permettant de réaliser notre prédiction.
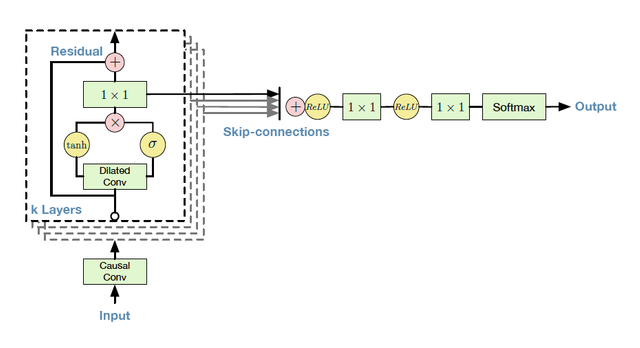
Schéma des résidus.
Source : https://medium.com/@evinpinar/wavenet-implementation-and-experiments-2d2ee57105d5
Dans ce bloc, nous retrouvons une porte d'activation correspondant à :
Ici, nous réalisons une convolution entre les entrées x et les poids W. Par la suite, nous réaliser une multiplication élément par élément entre les deux résultats des fonctions tanh et sigma. Puis, nous réalisons la somme avec notre valeur d'entrée. Cette technique de réutiliser la valeur d'entrée nous permet d'avoir des réseaux de plus en plus complexe. En effet, a force de réaliser des opérations, le réseau se concentre sur le détail et perd la notion de notre donnée initiale.
Réalisation de la prédiction
Lorsque nous allons réaliser une prédiction, notre modèle va chercher à déterminer une valeur sur 16 bits, ce qui correspond à un total de 65535 possibilités. Ainsi, nous avons énormément de possibilités et c'est problématique. Pour éviter de choisir parmi autant de possibilités, nous devons réduire notre champ de prédiction. De plus, lors de la réalisation de ce modèle, les auteurs ont remarqué que nous étions plus sensibles au changement dans des petits sons que ceux dans des grands sons. De ce fait, après standardisation, nous devons faire plus attention aux valeurs proches de 0 que celle proche de 1. Cette standardisation, une transformation non-linéaire, est appelé Companding transforms et a pour formule :
Notre objectif avec cette fonction est de d'augmenter notre précision sur les valeurs sensibles. Ainsi, nous transformons nos valeurs afin que les valeurs sensibles, c'est-à-dire les valeurs proches de 0 deviennent des valeurs proches de -1 et 1. Enfin, avec cette fonction, les valeurs moins sensibles ont moins de possibilités. Vous pouvez le constater avec la figure ci-dessous, nous montrant les nouvelles valeurs obtenues avec cette fonction. Bien entendu, nous avons réduit les valeurs de prédiction et nous sommes passé à 256 possibilités.

Illustration de la fonction Companding transforms.
Source : https://medium.com/@kion.kim/wavenet-a-network-good-to-know-7caaae735435
Bien entendu, nous devons après cette prédiction, transformer ce résultat afin que l'on puisse réaliser un son.
Personnalisation de l'audio
Afin de préciser au système la langue, mais aussi le type de voix que nous souhaitons générer, nous devons fournir à notre système des paramètres. Pour cela, il nous suffit renseigner lors de la première entrée dans notre système le type de voix que nous souhaitons, la langue, l'intonation...
Conclusion
À travers cet article, nous avons vu le fonctionnement du réseau WaveNet et plus précisément son architecture. Pour plus d'information, nous vous invitons à aller lire le papier de ce réseau. Bien entendu, de nouveaux modèles ont été imaginés afin d'être plus précis et plus rapide. De ce fait, aujourd'hui, nous pouvons utiliser ce genre de réseau afin de générer des voix à partir de texte. Cependant, cette technologie peut-être employé dans le but de réaliser de mauvaises intentions, notamment l'usurpation d'identité. Nous essayerons de revenir sur cette problématique dans un autre article.
Bibliographie
https://medium.com/@kion.kim/wavenet-a-network-good-to-know-7caaae735435
https://medium.com/@evinpinar/wavenet-implementation-and-experiments-2d2ee57105d5
https://towardsdatascience.com/review-dilated-convolution-semantic-segmentation-9d5a5bd768f5
https://arxiv.org/pdf/1609.03499.pdf
https://media.ccc.de/v/emf2018-406-wavenet-whats-behind-googles-voice#t=1428
https://deepmind.com/blog/wavenet-generative-model-raw-audio/
Lien original : https://www.technologieintelligente.fr/intelligence-artificielle/reseau-de-neurones/generer-une-voix-a-partir-daudio-wavenet/
Félicitations ! Votre post a été sélectionné de part sa qualité et upvoté par le trail de curation de @aidefr !
La catégorie du jour était : #intelligence-artificielle
Si vous voulez aider le projet, vous pouvez rejoindre le trail de curation ici!
Bonne continuation !
Rendez-vous sur le nouveau site web de FrancoPartages ! https://francopartages.xyz
Ce post a été supporté par notre initiative de curation francophone @fr-stars.
Rendez-vous sur notre serveur Discord pour plus d'informations
Une explication très précise sur le fonctionnement de cette nouvelle technologie. Upvoté à 100% !
Merci pour cet article super intéressant ;-) !
Le rendu est vraiment pas mal !