Création et utilisation d'un réseau antagoniste génératif (GAN) pour générer des images de nombre

Le progrès de l'intelligence artificielle ne cesse d'augmenter. Il nous est désormais possible de générer des images à l'aide de réseaux de neurones et plus particulièrement en utilisant un réseau antagoniste génératif. Ainsi, vous avez sûrement vu passé des images de visages de personnes qui ont été générer à l'aide de l'intelligence artificielle. Dans cet article, nous allons mettre en place un réseau antagoniste génératif pour pouvoir générer des images de nombre écrit par une personne. Vous pouvez retrouver l'intégralité du code ici. Bien entendu, rien ne vous empêche de réaliser le même type de réseau, mais pour d'autres cas d'application.
Réseau antagoniste génératif
Dans un précédent article, nous avons vu le fonctionnement des GANs. Pour rappel, un réseau antagoniste génératif est composé en deux parties, à savoir un générateur et un discriminant. L'objectif du générateur est de générer des images. Quant au discriminant, son objectif est de déterminer si une image qu'on lui donne est une image vraie ou fausse. On entend par faux le cas ou l'image a été générée par notre générateur. Ainsi, l'objectif final du générateur est de créer une image qui passe à travers le jugement de notre discriminant. Et l'objectif final de notre discriminant est donc de déterminer toutes les images qui ont été générées.
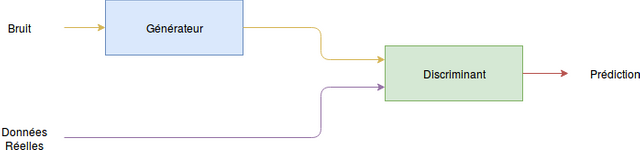
Schéma du fonctionnement d'un réseau antagoniste génératif.
Création de notre générateur
Nous allons, dans un premier temps, créer un générateur. Pour ce faire, notre générateur va chercher à créer une image à partir d'une entrée qui va correspondre à un bruit que nous allons générer. Ce bruit est un vecteur de valeurs aléatoires. Ce vecteur va nous permettre de définir les caractéristiques que nous souhaitons générer pour créer notre image.
Pour rendre l'image réaliste, il nous faut l'améliorer en ajoutant des éléments. De ce fait, nous réalisons l'étape inverse d'une classification. Pour rappel, lors d'une classification, nous cherchons à extraire les informations présentes sur une image, afin de pouvoir déterminer la catégorie d'appartenance de cette dernière. Ici, nous cherchons n'ont pas a extraire, mais à faire le processus inverse, c'est-à-dire à ajouter des éléments correspondant à notre label, permettant de rendre notre image la plus détaillé possible.
Pour ce faire, nous allons dans un premier temps utiliser une couche entièrement connectée indiquant les caractéristiques que nous souhaitons. Puis, nous allons transformer notre vecteur de sortie en une matrice, représentant notre image. Enfin, nous allons avoir plusieurs couches de convolutions permettant de rajouter les détails nécessaires à notre image.
def generator (self):
model = Sequential()
#
model.add(Dense(128 * 7 * 7, activation="relu", input_dim=self.latent_dim))
model.add(Reshape((7, 7, 128)))
# Scalling up the image (resizing)
model.add(UpSampling2D())
#
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
#
model.add(Conv2D(32, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
#
model.add(Conv2D(self.channels, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
#
# Create our input layer with the latent dimension
noise = Input(shape=(self.latent_dim,))
img = model(noise)
#
return Model(noise, img)
Création de notre discriminant
Dans le cas du discriminant, nous allons chercher à déterminer si l'image que nous passons en paramètre est une image qui a été générée ou non. Pour ce faire, nous allons réaliser un classificateur avec une seule catégorie, indiquant si l'image a été générée ou non.
Pour rappel, lors d'une classification, nous avons deux phases. La première servant à l'extraction des informations. Elle est réalisée à l'aide de réseaux de neurones de convolution. La seconde sert à la classification. Elle se base sur les informations extraites et est réalisée par une couche entièrement connectée de neurones.
def discriminator(self):
model = Sequential()
#
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
#
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(ZeroPadding2D(padding=((0,1),(0,1))))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
#
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
#
model.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
#
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
#
model.summary()
#
img = Input(shape=self.img_shape)
validity = model(img)
#
return Model(img, validity)
Réaliser le lien entre le générateur et le discriminant
Une fois, nos deux systèmes créés, nous allons devoir les liées. En effet, dans le cas du générateur, il va se baser sur les résultats du discriminant. Dans le cas ou ce dernier nous répond que l'image passée en paramètre est une image générée, alors le générateur va devoir s'améliorer. Dans le cas inverse, si il nous répond qu'il s'agit d'une vraie image alors qu'elle a été générée, nous allons devoir corriger notre discriminant.
Pour réaliser cela, nous allons, dans un premier temps, générer notre discriminant et lui appliquer à la sortie une fonction d'erreur. Cette dernière permettra de corriger le choix de notre discriminant lorsque nous lui passerons une image. Ainsi, il s'améliorera à chaque image que nous lui donnerons.
Puis, nous allons devoir construire notre générateur. Nous allons lui fournir en entrée un bruit lui permettant de réaliser une image. Pas ailleurs, nous récupérons la sortie de notre générateur et nous la donnons en entrée de notre discriminant. Cela permet de réaliser le lien entre nos deux systèmes. Enfin, nous appliquons une fonction d'erreur qui permettra d'améliorer notre générateur en fonction des résultats que le discriminant donnera.
# Build our discriminator
self.discriminator = self.discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
#
# Build our generator
self.generator = self.generator()
#
# The generator takes noise as input and generates images
input_noise = Input(shape=(self.latent_dim,))
img = self.generator(input_noise)
#
# For the combined model we will only train the generator
self.discriminator.trainable = False
#
# The discriminator takes generated images as input and determines validity
valid = self.discriminator(img)
#
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
self.combined = Model(input_noise, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
Entraînement de notre système
Une fois nos modèles créés, il va nous falloir les entraîner sur des données. La première étape va être de sélectionner nos données. Puis, nous allons générer un ensemble de bruits que nous allons donner à notre générateur. Ce qui nous permet de récupérer des images générées. Enfin, il ne nous reste plus qu'à donner ces images en entrée à notre discriminant. Enfin, une fois, notre discriminant corrigé, nous allons corriger notre générateur. Nous répétons ces opérations un nombre de fois déterminé (jusqu'à que nous obtenons des résultats qui nous satisfont).
# Select random images
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
#
# Sample noise and generate a batch of new images
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
gen_imgs = self.generator.predict(noise)
#
# Train the discriminator (real classified as ones and generated as zeros)
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
#
# Train the generator (wants discriminator to mistake images as real)
g_loss = self.combined.train_on_batch(noise, valid)
Résultat
Nous avons générer des images sur la base d'entraînement MNIST qui est une base de données regroupant des photos de chiffre écrit à la main. Pour cela, nous avons utilisé le code que vous pouvez retrouver sur github et l'exécuter sur google collab.

Résultat lors de la 1 ère itération.

Résultat lors de la 5000ème itération.

Résultat lors de la 10000ème itération.

Animation des résultats toutes les 20 itérations sur les 10000.
Comme vous pouvez le constater, nous obtenons des résultats plutôt corrects. Bien entendu, vous pouvez constater que nous avons réalisé énormément d'itération. Cependant, il est possible d'arrêter notre système bien avant. Cela dépend du résultat que vous voulez obtenir.
Conclusion
Dans cet article, nous avons vu la mise en place d'un réseau antagoniste génératif. Nous avons vu comment accorder les deux composants principaux de notre système, à savoir le générateur et le discriminant. De plus, nous avons pu tester ce type de réseau sur la base de données MNIST et obtenir des résultats plutôt performants. Bien entendu, nous pouvons utiliser ce type de réseau pour d'autres cas d'application, comme vous avez sûrement pu le constater sur des visages humains. Cela pourra être le sujet d'un autre article.
Lien original : https://www.technologieintelligente.fr/intelligence-artificielle/cas-dapplication/creation-et-utilisation-d-un-reseau-antagoniste-generatif-gan-pour-generer-des-images-de-nombre/
Encore une idée de post tres original et hyper captivant, bravo
Merci beaucoup pour ton retour, ça fait plaisir :)
This post has been voted on by the SteemSTEM curation team and voting trail. It is elligible for support from @curie.
If you appreciate the work we are doing, then consider supporting our witness stem.witness. Additional witness support to the curie witness would be appreciated as well.
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Bonjour, je tiens à dire que ChatGPT est vraiment intrigant. Personnellement, j'ai exploré ses capacités en utilisant des plateformes telles que Image GPT . J'ai trouvé cela particulièrement utile pour améliorer les services de support client, optimiser les tâches répétitives et même créer du contenu créatif à des fins de marketing. J'espère que mes informations vous seront d'une grande aide.