AI로 필터버블 문제를 해결할 순 없을까?
대학 시절 Eli Praiser가 쓴 [The Filter Bubble - How The New Personalized Web Is Changing What We Read And How We Think]라는 책을 읽었다. 머리를 한 대 세게 얻어맞은 기분이었다. 그 후 이 주제는 오랫동안 내 관심사 분야에 올라 있었다.
필터버블. 물론 논란이 많은 개념이다. 필터버블 현상이 대의 민주주주의를 위협하고 있다는 시선도, 실체 없는 기우라는 시선도 있다. 개인적으로 나는 '내가 진짜 필터버블에 갇혀 있나?'라는 생각이 들 때가 몇 번 있었다. 가령, 나와 내 친구들 사이에서는 너무 당연한 것이 나의 준거집단에서 한 발자국만 벗어나면 튀는 목소리가 된다는 것을 어렴풋이 느꼈을 때가 그렇다. 이런 생각이 들 때마다 의도적으로 필터버블 걷어내기 작업을 한다. 페이스북에서 전혀 동의하지 않는 게시물에 '좋아요'를 누른다든지 따위 작업 말이다. 물론 페이스북 알고리듬을 들여다볼 수 없는 까닭에, 이 작업이 실제로 효과가 있는지 알 길은 없다.
각설하고, 요는 내가 필터버블에 관심이 있다는 것
필터버블을 감시하고, 이 버블을 터뜨리기 위한 가장 확실한 방법은 플랫폼 차원에서 접근하는 것이다. 실제로 [The Markup]이라는 미국의 데이터 기반 탐사보도 비영리 뉴스룸은 시민 브라우저(Citizen Browser) 프로젝트에서 SNS 플랫폼(페이스북) 차원에서 분석하고 가시화한다.
이 프로젝트를 눈여겨 보며, 그리고 감탄하며 나도 필터버블을 완화하기 위한 기술적 시도에 나서고 싶었다. The Markup처럼 플랫폼 차원의 접근은 현재 단계에서 불가하다는 판단에서, 지금 할 수 있는 수준에서 필터버블을 터뜨리는 방법을 고민해보았다.
일명, POP THE FILTER BUBBLE
POP THE FILTER BUBBLE은 자연어처리(NLP)와 데이터 기반 콘텐츠 추천 시스템을 결합해 필터버블 완화 효과가 있을 것으로 기대하는 뉴스 추천 시스템을 제안한다.
그 방법을 요약하자면,
(1) 목적 : 뉴스 콘텐츠에서의 필터버블 현상 완화
(2) 방법론 : 독자가 읽고 있는 뉴스와 다루는 소재는 같고 정치 성향은 다른 뉴스 콘텐츠를 추천
(3) 기술적 방법론 : 두 가지 모델을 결합한다. 기사 텍스트의 정치 성향 탐지 모델(feat. BERT) + 독자의 뉴스 이용 로그 및 기사 제목 텍스트를 이용한 추천 시스템 모델(feat. Deep Knowledge-Aware Network for News Recommendation)
모델의 성능 평가, 한계, POP THE FILTER BUBBLE Phase2에서 하고 싶은 것 등, 구체적인 내용은 아래 글에서 확인하길 바란다.
아래 글은 서수민 님과 함께 썼다는 것을 알려드립니다.
1.1. 확증편향을 일으키는 필터버블
우리는 흔히 IT 기술의 발전 덕분에 그 어느 때보다 다양한 정보에 쉽게 접근할 수 있다고 믿는다. 인터넷에 접속해 지구 정반대 편에서 일어나는 일도 빠르고 손쉽게 알 수 있고, 다양한 의견을 접할 수 있다는 기대다. 하지만 현실은 이 믿음과 판이하다. 우리가 접하는 정보를 ‘필터링' 하는 필터버블이 존재하기 때문이다.
필터버블은 온라인 사용자별로 필터링 된 정보가 마치 거품(버블)처럼 사용자를 가둬버리는 정보 필터링 현상이다. 2009년 12월 구글이 미국 내 사용자의 검색결과 개인 맞춤화를 도입한 후, 개인 맞춤화 정보 제공은 온라인 서비스의 성공 척도가 됐다고 해도 과언이 아니다.

온라인 서비스를 제공하는 기업들은 개인 맞춤화 알고리즘으로 사용자가 온라인에 남긴 데이터, 인구통계학적 특성을 기반으로 동질의 정보를 사용자에게 많이 노출하는 방식으로 사용자가 접하는 정보를 설계한다. 검색 서비스를 예로 들면, 똑같은 단어를 검색하더라도 누가 검색하느냐에 따라 서로 다른 결과가 나오는 것이다.
이같은 개인 맞춤화 알고리즘은 사람들이 다양한 정보를 접하는 것을 막고 유사한 정보를 소비하게끔 유도한다. 이로써 ‘인터넷을 통해 다양한 정보와 의견을 접할 수 있다'는 믿음과 정반대로 사람들은 점점 동질의 정보를 소비한다. 그리고 이같은 ‘정보 노출의 설계'는 ‘의사결정의 설계'로까지 이어진다. 사용자가 다양한 정보를 접할 기회를 가로막아 확증편향의 함정에 쉽게 빠지게 만드는 것이다.
필터버블과 이로 인한 확증편향은 특히 필터버블이 뉴스 콘텐츠를 필터링할 때 심각한 사회 문제로 작용한다. 정치·사회·이념의 양극화를 일으키는 요인으로 작용하고, 이는 대의민주주의를 위협으로까지 이어질 수 있다. 필터버블을 처음 주장한 엘리 프레이저는 필터버블이 비민주적인 사회를 불러올 수 있다는 점을 경고했다.
1.2. 필터버블을 터뜨리는 뉴스 추천 시스템 제안
뉴스 콘텐츠에서의 필터버블 현상을 막기 위해 본 프로젝트에서는 ▲텍스트의 정치 성향 탐지 모델 ▲사용자의 뉴스 이용 로그 및 제목 텍스트를 이용한 추천 시스템 모델을 결합해 새로운 뉴스 추천 서비스를 제안하려 한다.
**2. BERT 파인튜닝을 이용한 텍스트의 정치 성향 탐지 모델**
본 프로젝트팀은 텍스트를 입력하면 해당 텍스트의 정치 성향을 탐지하는 모델을 개발했다. 정치 성향이 진보일 때는 0, 보수일 때는 1을 출력한다.
2.1. 훈련 데이터
텍스트의 정치 성향을 탐지하기 위해 the Ideological Books Corpus(IBC) 데이터의 일부를 사용했다. IBC는 2013년 Gross가 만든 데이터로, 정치적 편향이 뚜렷하다고 알려진 미국 인사들의 저작물을 모은 데이터다. 정치학자들이 메뉴얼화된 기준에 따라 저자의 정치 성향을 판단해, 저자의 저작물에 이 정치 성향을 라벨링 한 형태다. 저작물(document) 단위로 이뤄져 있고 각 저작물에는 저자의 정치적 성향에 따라 ‘진보(lib)', ‘중도(neutral)', ‘보수(con)' 중 하나의 라벨링이 달려있다.
본 프로젝트에서는 전체 IBC 데이터를 사용하지 않고 2014년 Mohit Iyyer 등이 IBC 데이터를 한 차례 더 가공해 만든 IBC 일부 데이터를 사용했다. Mohit Iyyer 연구팀은 Political Ideology Detection Using Recursive Neural Networks 연구에서 저작물(document) 단위를 문장 단위로 쪼개고 정치적 편향이 뚜렷하지 않은 문장을 제외했다. 그리고 크라우드소싱 플랫폼을 이용해 문장 단위 정치 성향 라벨링 작업을 했다. 이렇게 만들어진 재가공 IBC 데이터세트는 진보 성향 문장 2025개, 중도 성향 문장 600개, 보수 성향 문장 1701로 구성돼 있다. 본 프로젝트에서는 중도 문장 600개를 제외한 진보 및 보수 문장만을 사용했다.
2.2. BERT 파인 튜닝
텍스트 정치 성향 탐지기를 개발하기 위해 파이토치 프레임워크가 제공하는 BERT 파인튜닝 모델을 이용했다.
BERT(Bidirectional Encoder Representations from Transformers)는 구글이 만든 언어 모델로, 자연어처리(NLP) 분야에서의 전이학습(transfer learning)을 위해 고안됐다. BooksCorpus 800만 단어와 영어 위키백과 2500만 단어를 사전 훈련해 생성한 사전 학습 모델(pre-trained BERT model)을 제공하고, Transformer의 encoder 부분만 사용한다. BERT를 사용하면 사전 훈련된 고성능 언어 모델을 전이학습 시켜 다른 자연어처리에 적용할 수 있다. 또 Transformer는 모든 토큰을 순서대로 입력받는 RNN과 달리 모든 토큰을 한 번에 받아 처리하기 때문에 학습이 빠르다는 점 등 장점이 있다.
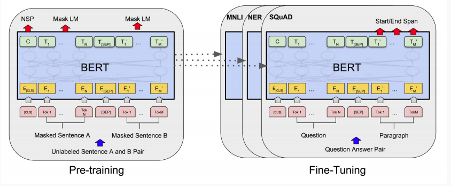
BERT 파인튜닝(Fine-Tuning)은 사전 학습된 BERT 모델 아키텍처 위에 레이어를 하나 추가해 모델을 훈련함으로써, 개별 태스크를 더 잘 수행하도록 한다.
2.3. 텍스트 정치 성향 탐지 모델 개발 과정
정치 성향 탐지 모델을 개발하기 위해 BERT가 제공하는 ‘bert-base-uncased’ 토크나이저로 텍스트를 토크나이징하고, 각 문장에 처음과 끝에 스페셜 토큰 [CLS]과 [SEP]를 추가했다.
토크나이징 예시 :
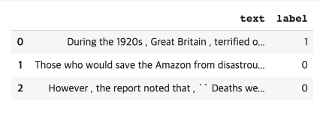
Original: Those who would save the Amazon from disastrous helter-skelter deforestation are also working out the details of schemes to certify soy , cattle , and other Amazonian products as having been sustainably produced ; already there is in place in Brazil a two-year moratorium on forest destruction to plant soy .
Token IDs: [101, 2216, 2040, 2052, 3828, 1996, 9733, 2013, 16775, 2002, 21928, 1011, 15315, 20042, 2121, 13366, 25794, 2024, 2036, 2551, 2041, 1996, 4751, 1997, 11683, 2000, 8292, 28228, 12031, 25176, 1010, 7125, 1010, 1998, 2060, 9733, 2937, 3688, 2004, 2383, 2042, 15770, 8231, 2550, 1025, 2525, 2045, 2003, 1999, 2173, 1999, 4380, 1037, 2048, 1011, 2095, 26821, 24390, 2006, 3224, 6215, 2000, 3269, 25176, 1012, 102]
이후 패딩을 통해 모든 문장의 길이를 일치시키고, 어텐션 마스크(Attention Masks)를 만들었다. 이와 같은 전처리를 마친 데이터를 파이토치 프레임워크에서 사용할 수 있게 토치 텐서(torch tensor) 데이터 타입으로 바꾸고, 파이토치 data.Dataset으로 사용자 정의 데이터세트를 만들었다.
이렇게 만들어진 데이터세트 예시는 다음과 같다.
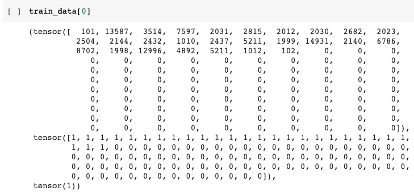
첫 번째 텐서는 문장을 토큰화해, 토큰ID로 바꾼 train_input, 두 번째 텐서는 어텐션 마스크인 train_mask, 마지막 텐서는 정치 라벨인 train_labels다.
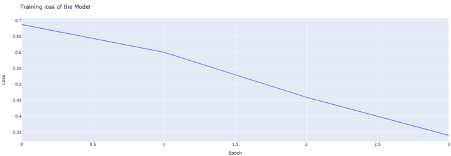
이렇게 준비된 훈련 데이터세트으로 BERT가 제공하는 사전 학습 모델인 BertForSequenceClassification 모델을 기본으로 사용했다. 이 모델은 12개 레이어로 구성된 기본 사전 학습 BERT 위에 텍스트 분류 과제를 위한 추가 linear layer를 추가한 모델이다. 모델 훈련을 위한 epoch은 4 , 배치 사이즈는 16, 옵티마이저로는 AdamW를 사용했다.
2.4. 모델 성능 평가
2.4.1. IBC 데이터를 이용한 평가
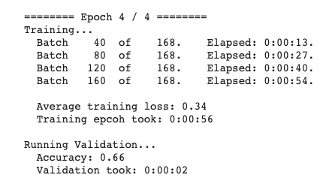
모델은 검증 데이터세트에서 정확도 최대 0.66을 보여줬다. 테스트 데이터세트에서의 정확도는 약 0.60을 기록했다.
2.4.2. 별도 뉴스 데이터를 이용한 평가
모델 성능을 살피기 위한 두 번째 방법으로 AllSides 사이트가 제공하는 AllSides Media Bias Ratings가 평가한 미디어 정치 성향 평가를 활용했다.

AllSides Media Bias Ratings는 온라인 사용자들에게 미국 온라인 매체들의 정치 성향을 5개 단계(진보 편향 - 진보 - 중도 - 보수 - 보수 편향) 중 하나로 라벨링 하게 하고, 라벨링에 대한 커뮤니티 피드백을 6개 단계(absolutely disagree - somewhat disagree - disagree - somewhat agree - agree - absolutely agree)로 제공한다.
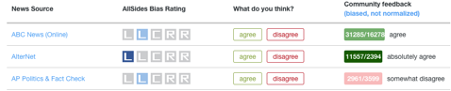
이 서비스를 참고해 정치 성향 평가에 대한 커뮤니티 피드백 단계 중 absolutely agree를 받은 진보 편향 매체 2개(AlterNet, The New Yorker)와 보수 편향 매체 2개(National Review, The Federalist), 총 4개 매체를 골랐다. 그리고 각 매체의 최근 정치 기사의 첫 문장을 발췌해 우리의 모델로 정치 성향을 탐지해, 그 결과가 집단지성이 탐지한 정치 성향과 일치 여부를 살펴보았다.
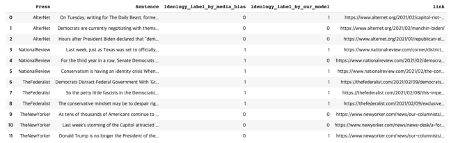
그 결과, 12개 중 9개 문장에 대한 정치 성향 탐지에 성공해 75% 정확도를 보였다.
3. 필터버블을 터뜨리는 뉴스 추천 시스템
이제 앞에서 만든 텍스트의 정치 성향 분류 모델에 콘텐츠 추천 알고리즘을 더한 뉴스 추천 시스템을 제안한다.
이에 뉴스 기사 추천 알고리즘 중 DKN(Deep Knowledge-Aware Network for News Recommendation)을 사용자가 가장 좋아할 만한 기사를 추천해주는 기존의 방식으로 학습하고, 이를 앞서 개발한 텍스트 정치 성향 탐지 모델과 결합하여 필터버블을 완화할 수 있는 추천 모형을 제안한다.
3.1 훈련 데이터 - MIND(A Large Scale Dataset for News Recommendation)
추천 알고리즘 학습에 MIND 데이터세트을 사용하였다. MIND는 Microsoft에서 뉴스 추천 알고리즘의 연구를 위해 공개한 데이터로, Microsoft News에서 수집한 100만 명의 사용자와 160,000건의 기사 정보로 이루어져 있다. 수집 기간은 2019.10.12 부터 2019.11.22.까지 총 6주이다. 사용자 정보는, 각 사용자의 익명화된 아이디와 그들이 클릭한 기사 로그 기록을 포함하고, 기사 정보는 기사 아이디와 category, title, abstract을 포함한다. 본 프로젝트에서는 전체 데이터 중 5만 명의 사용자를 샘플링한 MIND-small 데이터세트을 사용하였다. 추천 알고리즘 학습에는 기사 정보 중 title만 사용하였고, 마지막 추천 단계에서는 정치 기사만 남겨서, title과 abstract 텍스트를 정치 성향 탐지 모델에 사용하였다.
3.2. 추천 알고리즘 - DKN(Deep Knowledge-Aware Network for News Recommendation)
3.2.1 알고리즘 선정 이유
DKN은 뉴스 텍스트 엔티티의 지식그래프 구조를 활용한 콘텐츠 기반 추천 알고리즘이다. 뉴스 추천을 위한 다양한 알고리즘 중 DKN을 선정한 이유는 두 가지 이다. 첫째, 뉴스 기사는 음악, 영화 등 다른 콘텐츠에 비해 수명이 매우 짧아서 협업필터링보다는 콘텐츠기반 필터링이 보다 효과적이다. MIND 데이터세트의 경우도 대부분의 기사가 2일 이내에 클릭률이 0으로 떨어지는 모습이 나타났다. 둘째, 기사의 ‘논조’를 반영하기 위해서는 지식 그래프 구조가 효과적일 수 있다고 보았다. 논조는 단어들이 어떠한 구조로 연결되었는가에 의해 결정되기 때문이다.
3.2.2. 알고리즘 설명
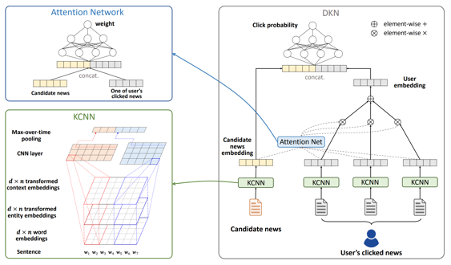
DKN은 KCNN(Knowledge-aware Convolutional Neural Network)를 통한 기사 임베딩과, 사용자별 로그 기록을 사용한 attention network의 두 단계를 통해 이루어진다. 후보 기사 하나와, 사용자의 로그 기록을 인풋으로 하여, 해당 사용자가 후보 기사를 읽을 확률을 예측하고 실제 사용자가 그 기사를 읽었는지 여부와 비교하는 방식으로 학습한다.
먼저, KCNN은 텍스트를 word embedding, entity embedding, context embedding의 3가지 채널로 표현하여 CNN을 통해 특징을 추출하는 것이다. 텍스트를 3채널로 표현하는 방식은 다음과 같다. 예를 들어, "Donald Trump to deliver State of the Union address next week" 이라는 기사 제목이 있다면, 이 텍스트는 단어 수준에서는 [10, 34,45,334,23,12,987,3456,111,456,432]와 같이 인코딩 되고, 첫 번째 단어와 두 번째 단어인 ‘Donald Trump’가 한 개의 엔티티로 추출되어 엔티티 수준에서는 [45, 45,0,0,0,0,0,0,0,0,0]와 같이 인코딩 된다. 단어와 엔티티 수준에서 인코딩된 텍스트 인풋을 가지고 word embedding, entity embedding, context embedding을 추출한다. word embedding은 word2vec, Glove 등의 방식을 사용하여 단어를 임베딩 하는 것으로, 이번 프로젝트에서는 사전 학습(pre-trained) Glove를 통해 word embedding initialization을 설정하였다. entity embedding과 context embedding은 지식 그래프를 사용한다. 문장에서 엔티티를 찾아내어 지식그래프와 매칭시키는 entity linking 이후, corpus의 엔티티 중 1단계 내로 이어진 엔티티를 연결하여 corpus의 sub-graph를 얻는다. 다음으로 TransE를 사용한 네트워크 임베딩을 실시하여 각 entity embedding을 얻는다. 또한 엔티티별로 한 단계로 연결된 엔티티의 임베딩을 평균낸 context embedding을 얻는다. entity embedding과 context embedding을 통해 단어의 정보 뿐 아니라 텍스트의 엔티티들이 서로 어떠한 관계를 가지고 있는지 까지 반영할 수 있게 된다. 이렇게 얻어진 word-embedding, entity embedding, context-embedding을 3가지의 채널로 쌓아, 컬러 이미지에 적용하는 것과 같은 3-channel CNN을 텍스트에 적용하여 특징을 추출하여 기사 별 1차원의 임베딩 벡터를 얻는다.
기사별 임베딩을 얻은 후에는, 사용자의 기록을 고려한 attention network를 거쳐 사용자가 후보 기사를 읽었는지 예측한다. 사용자의 로그 기록에 해당하는 기사들의 임베딩 벡터와 후보기사의 임베딩 벡터에 어텐션을 적용해, 로그 기록 각 기사에 대해 후보 기사에 대한 어텐션 가중치를 구한다. 다음으로 로그 기록 기사 임베딩을 가중 평균 내어 사용자의 임베딩 벡터를 넣는다. 마지막으로 후보 기사의 임베딩과 사용자 임베딩을 concat하여 해당 사용자가 후보 기사를 읽을 확률을 예측한다.
3.2.3. 추천 시스템 학습 과정
학습에 사용한 하이퍼 파라미터는 다음과 같다.
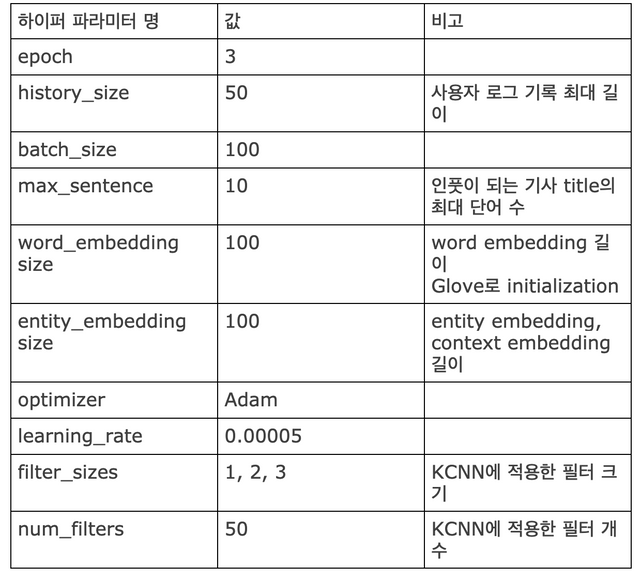
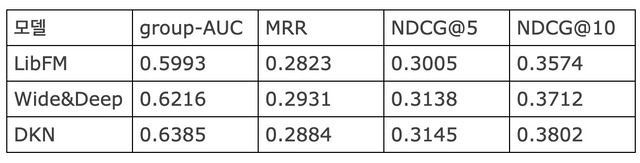
MIND-small을 사용한 DKN 학습 결과를 MIND 논문에서 제시한 baseline인 LibFM, Wide&Deep과 비교한 결과는 다음과 같다. (LibFM, Wide&Deep은 MIND-large를 사용한 결과)
3.3. 필터버블을 터뜨리기 위한 추천시스템 개발 과정 및 결과
DKN을 사용하는 경우, 두 가지 방식의 추천이 가능하다. 사용자의 이전 기록을 모두 고려하여 추천 기사 리스트를 묶어서 제공할 수도 있고, DKN 학습 과정에서 추출된 각 기사 별 임베딩을 사용하여 사용자가 지금 당장 읽고 있는 기사와 관련된 글을 추천(item2item방식)할 수도 있다. 본 프로젝트에서는 후자의 방식을 이용하고자 한다. 추천 모델은 MIND-small 데이터를 모두 사용하여 학습하였으나, 추천 과정에서는 논조의 차이가 가장 두드러지게 나타나는 정치기사만 사용하였다. 전체 기사 중 정치 카테고리에 속하고, title과 abstract이 모두 존재하는 3393개의 기사를 대상으로 필터버블을 터뜨리기 위한 추천을 실험해보았다.
첫째, DKN을 통해 각 기사의 단어, 엔티티 구조가 담긴 기사 별 KCNN 임베딩을 얻는다. 둘째, KCNN 임베딩으로 코사인 유사도를 계산하여 특정 기사와 비슷한 기사를 찾는다. 코사인 유사도가 높은 기사를 살펴본 결과, 실제로 비슷한 주제를 다루고 있음을 알 수 있었다. 셋째, 정치성향 분류모델을 사용하여 추천 대상이 되는 기사와 유사도는 높으면서 정치 성향은 다르게 예측된 기사를 추천한다. 정치성향 분류 모델 적용 결과 3393개의 기사 중 1745개가 liberal, 1648개가 conservative로 분류되었다. 이 과정을 통해 정치 기사에 대하여, 비슷한 주제를 다루면서도 논조가 다른 기사를 추천하고자 하였다.
실험 결과의 예시로 두 가지 사례를 제시한다. 첫 번째 사례는 “The Many Ways That Joe Biden Trips Over His Own Tongue” 기사이다. 해당 기사는 정치 성향 분류 모델에서 ‘conservative’로 분류되었으며, Joe Biden이 이민자 정책에 대해 말을 바꾼 것에 대한 비판 내용을 담고 있다. 한편 KCNN 임베딩으로 계산한 코사인 유사도가 두 번째로 높은 ‘Latino Iowans are playing a bigger role in the caucuses and Democrats are paying attention’ 기사는 정치 성향 분류 모델에서 ‘liberal’로 분류되었다. 추천 대상 기사와 유사하게 BIden의 이민자 정책에 대해 다루고 있지만, 논조는 바이든의 이민자 정책이 Iowa 라틴계 유권자들의 마음을 이끌고 있다는 긍정적인 내용이다. 따라서 주제는 비슷하지만 논조가 다른 이 기사를 함께 추천할 수 있다.
두 번째 사례는 “Warren's $52T 'Medicare-for-all' plan revealed: Campaign still claims no middle-class tax hikes needed” 기사이다. 해당 기사는 정치 성향 분류 모델에서 ‘liberal’로 분류 되었으며, 민주당 대선 후보인 Warren의 ‘Medicare-for-all’ 정책이 중산층 세금 인상을 필요로 하지 않는다는 내용을 담고 있다. 한편 코사인 유사도가 2번째로 높지만, 정치 성향 분류 모델에서 ‘conservative’로 분류된 ‘Warren's health care plan pledges no middle-class tax increase’은 같은 주제를 다루면서도, 실제로는 세금 인상 없이 정책을 실행하기는 무리라는 주장을 하고 있다. 따라서 이 기사를 함께 추천할 수 있다.
4. 남는 질문들과 앞으로의 계획
위에서 제안한 방법은 같은 사안을 다룬 기사 중 정치성향이 상반된 기사를 추천하는 방식이다. 그 성능에 대한 평가를 차치하고서라도 남는 질문이 있다. 과연 이 방법이 필터버블을 터뜨리는 데 유효할 것인가? 콜럼비아 대학과 뉴욕 대학이 공동 연구한 결과에 따르면, 소셜미디어에서 반대 정치 성향에 노출되면 오히려 정치 양극화가 심화된다고 한다. (자세한 내용은 이 글을 참고 : Exposure to opposing views on social media can increase political polarization) 예상 가능하듯, backfire 때문이다.
사실 이 지점을 POP THE FILTER BUBBLE을 시작할 때부터 우려한 점이다. 때문에 처음 디자인 한 모델은 정치 성향을 0과 1, 바이너리로 분류하는 것이 아니라 0~1 사이 확률값으로 구하는 것이었다. 궁극적으로는 독자가 자신이 읽고 있는 기사가 0(진보)과 1(보수) 사이 숫자로 표현된 정치 성향 바(bar)에서 어느 지점에 위치하는 지 확인하고, 바에서 정치 성향 포인트를 바꿔가며 다양한 정치 성향을 가진 유사 소재 기사를 선택해 읽게 하는 것이었다. 이건 Phase 2에서 해야지. 🥰🥰🥰
5. 참고 문헌
-The Filter Bubble - How the new personalized web is changing what we read and how we think (2012.04, Eli Pariser)
-Political Ideology Detection Using Recursive Neural Networks (2014.06, Mohit Iyyer 외 3인, ACL Anthology)
-BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(2019.05, Jacob Devlin 외 4인, arVic)
-DKN: Deep Knowledge-Aware Network for News Recommendation(2018.04, H Wang, F Zhang, X Xie, M Guo)
-MIND: A Large-scale Dataset for News Recommendation(2020.07, F Wu, Y Qiao, JH Chen, C Wu, T Qi, J Lian)
좋은 논문 잘 읽고 갑니다~~^^
긴 글 읽어주셔서 감사합니다 :) 논문이라기엔 사이드 프로젝트를 포스팅으로 푼 정도에요 ㅎㅎ