Datenstrukturen: Das Set / Menge
Das Set / Eine Menge
Die Sets (deutsch: Mengen) bilden neben Listen eine zweite wichtige Gruppe von Datenstrukturen. Genauso wie mit Listen kann man mit Sets auch Objekte verwalten. Allerdings gibt es im Vergleich zu Listen einige Unterschiede, die ich gerne erklären möchte.
Ein wichtiger Unterschied ist, dass Sets keine Indizes haben. Es wird also nicht Garantiert, dass die Einfügereihenfolge eingehalten wird. Das liegt an der Verfahrensweise, wie Objekte in das Set eingefügt werden.
Als Beispiel wird zu jedem Objekt was eingefügt wird ein Hashwert berechnet (Hashset). Dieser wird auch verwendet, um Duplikate im Set zu vermeiden. Das ist zudem ein weiterer Unterschied zu Listen. Sets erlauben keine Duplikate.
Bevor ein Objekt eingefügt wird, wird überprüft, ob das Set diesen Hashwert bereits enthält. Falls ja, dann handelt es sich um ein Duplikat.
Da Sets keine Indizes haben wird ein sogenannter Iterator verwendet, um das komplette Set zu durchlaufen, um Objekte zu finden oder zu entfernen.
Mithilfe von Sets lassen sich Mengenoperationen durchführen. Man kann zwei Sets miteinander verschmelzen (Vereinigung); nur Objekte suchen die in beiden Sets gemeinsam vorkommen (Schnittmenge) oder nachsehen, ob gleiche Objekte in dem anderen Set auch vorkommen (Differenz).
Beispiele
Seien A={1,2,3,4} und B={2,3,5,7,11} zwei Mengen, und X sei das jeweilige Result, was auch eine Menge ist.
Eine Vereinigung (Union) aus A und B wäre dann: X_1={1,2,3,4,5,7,11}. Bitte beachten: Es gibt keine Duplikate, auch wenn die 3 in beiden Mengen vorkommt.
Eine Schnittmenge (Intersection) aus A und B wäre: X_2={2,3}. Diese kommt zustande, da die Elemente 2 und 3 in beiden Mengen vorkommen.
Die Differenz (Difference) aus A und B (A ohne B) enthält die Elemente X_3=A\B={1,4}. Diese kommen Ausschließlich in der Menge A vor.
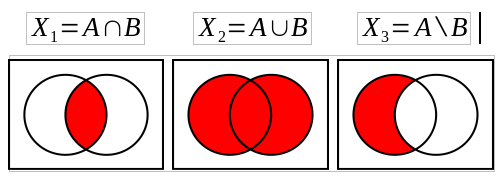
Abbildung: Mengenoperationen auf zwei Sets
Anwendungsbeispiel
Listen und Sets sind zwei Datenstrukturen, um Objekte zu verwalten. Theoretisch kann man alles was man mit Listen machten möchte auch mit Sets erledigen. Um zu entscheiden, ob nun eine Liste oder das Set die richtige Wahl ist, hier ein paar Entscheidungshilfen:
- Muss die Einfügereihenfolge eingehalten werden (Auslesen einer Datei, Speichern von Datensätzen, ...)? -> Liste
- Muss man nach Prioritäten unterscheiden (Termine, Threading, ...)? (Priority Queue)
- Dürfen Wörter, Zahlen oder andere Datensätze nicht doppelt vorkommen? (Set)
Quelle
http://conference.scipy.org/proceedings/scipy2010/pdfs/mckinney.pdf
Du hast ein Upvote von unserem Kuration – Support Account erhalten.
Dieser wird nicht von einem Bot erteilt. Wir lesen die Beiträge. (#deutsch) und dann entscheidet der Kurator eigenverantwortlich ob und in welcher Stärke gevotet wird. Unser Upvote zieht ein Curation Trail von vielen Followern hinter sich her!!!
Wir, die Mitglieder des German Steem Bootcamps möchten "DIE DEUTSCHE COMMUNITY" stärken und laden Dich ein Mitglied zu werden.
Discord Server an https://discord.gg/Uee9wDB