Ich finde die neue Version sehr gelungen und auf jeden Fall besser als die alte!
Ich habe heute ausgiebig getestet. Bei der Geschwindigkeit hast du einen großen Schritt gemacht. Die Suchergebnisse werden angemessen schnell angezeigt. Sogar mit Text-Snippet. Da bin ich echt begeistert! Ist es noch so, dass du den Body erst gesondert holst, wenn der Text nicht innerhalb des Body-Limits der Such-Request zu finden ist?
Die Ignore-Liste habe ich noch nicht getestet. Hinsichtlich des #deutsch -Tags wäre das aber sicher sehr sinnvoll und wirklich auch sehr bequem. Da du die Postanzeige sehr an Steemit anlehnst, ist das Look-and-Feel auch sehr bekannt.
Die Daten innerhalb der Ergebnisbox sind sehr übersichtlich und aus meiner Sicht ausreichend. Schön finde ich auch, dass du die Img-Größe an die Img-Box angepasst hast. Schmunzeln musste ich bei der Mitteilung, dass Bilder vom hive.blog nicht angezeigt werden :-) Dieser ist in Ordnung und auch nicht zu aufdringlich.
Das Label "Steemexclusive" ist in gut für den ersten Blick. Nimmst du die Daten aus der Tag-List oder fragst du dies noch gesondert ab?
Die App-Anzeige wäre jetzt für mich persönlich eher weniger interessant, stört aber nicht und macht die Anzeige auch nicht unübersichtlich.
Insgesamt wüsste ich jetzt gar nicht, was an deiner Suche noch zu verbessern wäre.
Vielen Dank also für deine Arbeit... Lesezeichen wurde gesetzt! :-D
Edit: Heute vormittag war mir noch aufgefallen, dass mir bei einer Suche sowas ähnliches wie "könnte noch interessant sein" vorgeschlagen wurde. Da war ich sehr verblüfft. Das wird wahrscheinlich am Ende der "richtigen" Suchergebnisse angezeigt. Ich kann jetzt gerade nicht sagen, ob diese Tipps wirklich passten...
Dickes Danke für's testen und die ausführliche Rückmeldung.
Ja genau. Über SDS kommen die max. möglichen 1000 Zeichen, weniger bringt zeitlich nicht viel. Wenn der Suchbegriff bzw. die Suchbegriffe nicht darin gefunden werden, wird der ganze Body geholt. Dadurch wird die Suche speziell bei mehreren Suchbegriffen deutlich langsamer. Mir ist noch nichts passendes eingefallen, wie das zu optimieren ist und zeitlich geht es ja so halbwegs.
Ach ja, "Maybe relevant" - das hängt ebenfalls mit mehreren Suchbegriffen zusammen, weil diese selten genau wie angegeben gefunden werden, z.B. bei "Apfelstrudel Rezept", da gibt es nur eine genaue Übereinstimmung. Bei allen anderen Ergebnissen sind die Suchbegriffe irgendwo im Text verstreut und werden deshalb unter "Maybe relevant" einsortiert.
Ist keine gesonderte Abfrage, wird aus json_metadata geholt.
Ich habe gerade eine neue Verlinkung eingebaut, das Profilbild ist jetzt mit SteemFollow verlinkt. Ab und zu finde ich das ganz praktisch.
Huch, und zack schon hat es mir etwas Zeit gespart, mit einem Klick sieht man die Daten von SteemFollow, dort ist dann ein Link auf SteemWorld - keine 20 Sek. und schon weiß man, wer hinter dem Acc steckt.
Mal guggen, hab schon was im Hinterkopf, bestimmte Accountdaten per Klick direkt in der Suche anzuzeigen. Da werd ich aber noch etwas brüten...
Habe noch nicht ausreichend „Performed“ (wie mein Neffe jetzt sagen würde), deshalb nur ein blöder Einwurf… ;-)
Jau!!! „Andere User haben auch gesucht…“
Ja, nee, @moecki, das ist ne Erwähnung wert, das kriegst du hin… ;-)
Dafür müssten wir aber zur Datensammelkrake à la Amazon mutieren... wollen wir das?! ;-))
Nee!!!!
Hab den Ironieknopf mal wieder nicht tief genug gedrückt... ;-)
Moin Chriddi,
meinst du, so ähnlich wie Google das z.B. macht, nach ein paar Buchstaben Suchvorschläge einblenden?
Jo, ganz praktisch. Bin aber wie Moecki für Steem eher weniger jau! Dazu müssten alle Eingaben "mitgeschrieben", also in einer Datenbank gespeichert und während der Eingabe ausgewertet werden. Ob das so gut ist, wenn alle Suchanfragen gespeichert werden?
Hihi, nee, ich meinte schon so eine nervige Spionageleiste. Aber eben als Spaß.
Sorry, werde nicht mehr zu (für mich) merkwürdiger Stunde irgendwo reingrätschen... ;-)
Komm gut ins neue Jahr!
Ich finde die Zeit jetzt absolut in Ordnung. Mir fällt da aktuell auch kein besserer Weg ein, außer man macht es asynchron und gibt bis zur Verarbeitung des gesamten Bodys den Kurz-Body ohne Suchtext-Highlight aus. Ob das aber bei deinem aktuellen Setup mit php sinnvoll umsetzbar ist, kann ich nicht beurteilen.
Ja, genau so hieß das. Ich konnte es nicht mehr rekonstruieren. :-)
Das verstehe ich jetzt nicht. Es sind doch alle Suchbegriffe irgendwo im Text verstreut?!
Finde ich auch praktisch. Ich habe ja auch einige Linkgs "verbaut". Man muss da bloß den Überblick behalten und nicht zu viel "verstecken", da die Mobiluser keinen Hover haben.
Bin gespannt. Das geht mir ja häufig auch so. Dies könnte noch eingebaut werden oder jenes... Ob sich das dann sinnvoll umsetzen lässt, muss sich dann zeigen oder in weiteren Denkphasen überprüft werden :-)
Bei mir ist es so, dass bei den Ergebnissen zuerst die 100% Treffer kommen, am Beispiel "Apfelstrudel Rezept" also genau dieser Text gefunden wurde. Unter "Maybe relevant" steht irgendwo im Text "Apfelstrudel" und irgendwo anders vielleicht auch noch "Rezept". Ich weiß gar nicht, ob für SDS evtl. schon einer von x Suchbegriffen ausreicht, ich nehme halt was kommt :-)
Hmm, grummel... gerade gesehen, deine Suche liefert bei "Apfelstrudel Rezept" die gleichen Ergebnisse, bei dir wird aber z.B. beim Beitrag von svinsent das Beitragsbild angezeigt - bei mir kommt da nichts:
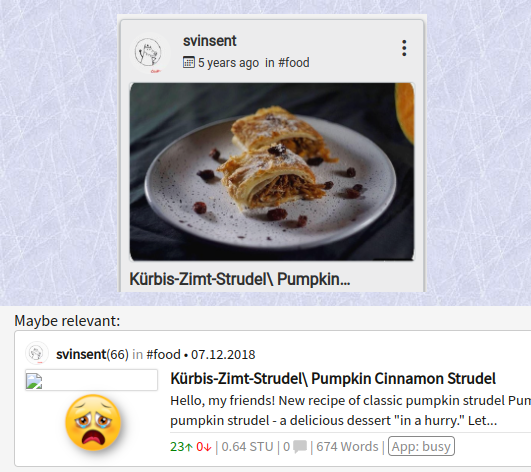
Der Grund ist, bei dem Beitrag ist weder in json_images noch in json_metadata ist ein brauchbares Bild vorhanden, alle von ipfs.busy.org - und das geht ins Leere. Das stellt sich mir natürlich die Frage, wo nimmst du Lümmel das Bild her :-)
Ah, jetzt hab ich's. Du suchst als erstes nach dem ganzen String. Ich teile den String gleich in einzelne Wörter auf und suche nach den Einzelwörtern. So erscheinen bei mir gleich alle Posts, die beide Wörter beinhalten.
Aber wenn ich das richtig sehe, musst du für "Maybe relevant" eine zweite Abfrage machen, oder?
Tscha, habe hier eine Raubkopie der ipfs-Datenbank liegen ;-)
Probier mal die URLs wie gehabt an
https://steemitimages.com/133x0/anzuhängen. Ist verblüffend, aber da erhalte ich die Bilder. Im Beitrag werden sie ja auch angezeigt. :-)Oh, Steem hängt heute ganz schön, hatte deinen Kommentar bei Steemworld schon gesehen, auf steemit kam er dann so 30 Min. später.
Jetzt steh ich aber am Schlauch, du suchst nach Einzelwörter, pro Wort eine gesonderte SDS Abfrage? Und dann baust das erst zusammen? Das versteh ich jetzt nicht.
Bei mir ist eine Abfrage, die ich in einer Schleife durchgehe, Ergebnisse bei denen der String (wie viel Wörter auch immer) nicht enthalten ist, werden in einem extra "maybe relevant" Array gespeichert. Also nur eine Abfrage. Aber liegst sogesehen schon richtig, für die Ausgabe läuft dann eine weitere Schleife.
Ah - mir schwant da was, glaub ich hatte die steemimage Variante auch probiert, dann aber doch am Ende die Parameter angehängt, &width oder so. Da muss ich genauer schauen wie das bei mir läuft. Danke für den Tipp!
EDIT:
Dank deinem Tipp ist der Strudel ist wieder da!
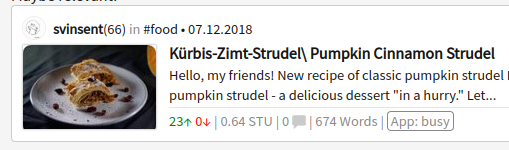
Bevor ich
https://steemitimages.com/133x0/vor die IMG-Url setze, hab ich noch eine IF-Abfrage eingebaut, damit, falls die externe Quelle erreichbar ist, diese verwendet wird. Es kommen ja Bilder von Peakd (die meine Suche komischerweise nicht mag) und auch noch von anderen externen Quellen.Ich hab das gerade getestet, wenn man irgend ein Bild nimmt z.B. von pixabay oder weissdergeierwoher.de und davor
https://steemitimages.com/133x0/einfügt, dann zieht sich steemit eine Kopie davon. Wenn meine trüben Augen um 07:35 Uhr morgens das richtig sehen, würde die Suche sonst Kopien von allen externen Bildern verursachen. Das muss ich mir nochmal genauer anschauen, wenn ich wieder was sehe.So, für mich wird's jetzt echt Zeit! Dir wünsch ich einen guten Start ins neue Jahr, hoffentlich ohne Brummkopf :-)
Nein, das ist nicht notwendig. Ich mache auch nur eine Abfrage, aber mit den Wörtern als einzelne Strings.
Ich (man beachte das Leerzeichen zwischen den beiden Anführungszeichen):
https://sds0.steemworld.org/content_search_api/getPostsByText/"Apfelstrudel" "Rezept"Du (vermutlich):
https://sds0.steemworld.org/content_search_api/getPostsByText/"Apfelstrudel Rezept"Das verstehe ich nun noch nicht. Wenn der String nicht enthalten ist, dürftest du das Ergebnis doch vom SDS auch nicht zurückbekommen.
Woran machst du das fest? Meinst du deshalb ist das Bild vom ipfs noch abrufbar?
In dem Fall wäre die If-Abfrage sinnvoll, aber wieder ein Zeitfresser - allerdings nur, wenn das häufiger vorkommt.
Ich hoffe, du bist gut gestartet und das Brummen lässt schon etwas nach ;-)
Guten Start für dich ins neue Jahr!
Ah, so machst du das. Ja, liegst du richtig mit deiner Vermutung, wenn exact match aktiviert ist, dann ist die Abfrage
getPostsByText/"Apfelstrudel Rezept"/ansonsten ohne Anführungszeichen:getPostsByText/Apfelstrudel Rezept/. Letzteres liefert die gleichen Ergebnisse wie deine Abfrage, soweit ich das sehen kann.Wenn du nach "Python Witness Pricefeed" suchst, findet SDS jede Menge Einträge, bei dir ist der einzige 100% Treffer, das ist dein Post vom October 2023, an dritter Stelle. Bei mir wird der gleich als erstes einsortiert, alle anderen sind dann Maybe relevant.
An der Stelle schon wieder Danke! Hab gerade noch einen Bug entdeckt und behoben, vorher war dein Post auch an dritter Stelle.
Suchst du mit
getPostsByText/"Python Witness Pricefeed"/dann findet SDS nur noch deinen Eintrag.Mit dem String (wie viel Wörter auch immer) meinte ich die Suchbegriffe, z.B. wäre "Python Witness Pricefeed" der String, der nur einmal gefunden wird.
Wenn exact match aktiviert ist, dann sollte das aber stimmen, also dass SDS keine anderen Ergebnisse liefert.
Gerade nochmal mit diesem Bild probiert, nach Aufruf mit vorangestellten
https://steemitimages.com/133x0/ist das Bild immer so abrufbar, die erstellte Kopie ist in der original Größe. Das kannst mit jedem beliebigen Bild machen, steemitimages.com zieht sich eine Kopie.Aber, ich glaube, Entwarnung! Zumindest teilweise, denn soweit ich weiß, zieht sich der Steemit-Server sobald ein Post abgesetzt wird, sowieso eine Kopie von den enthaltenen Bildern. Heißt auch, Bilder von Copy-Paste Posts werden auch auf steemit verewigt.