IPFS - Das System verstehen

Mit dem Ziel IPFS zu verstehen, bin ich heute angetreten. Dabei ging es mir nicht um "IPFS heißt InterPlanetary File System", was ist ein Hash und was sind die absoluten Basics des Konzeptes.
Das solltet ihr vielleicht schon wissen, bevor ihr den Artikel lest. Ich möchte mit dem minimal notwendigen technischen Blick das System verstehen und nicht einfach nur die Idee super finden.
Dazu habe ich mir Informationen gesucht, Blogs gelesen, Videos angeschaut, usw...
Ich habe die weiterführenden Links immer inline Verknüpft.
Euch erwartet jetzt meine Zusammenfassung des IPFS auf deutsch. Dabei habe ich einfach meine Gedankengänge und Schlussfolgerungen mit eingebaut und auch ein paar praktische Exkurse gemacht.
Vorweg ein kleines Dankeschön
Vielen Dank an @SemperVideo, der für den Einstieg in das Thema tolle Videos gemacht hat. Vielen Dank auch an @GaryTheGammarid, der im deutschen Discord Chat und unter diesem Artikel auf ein Problem mit IPFS aufmerksam gemacht hat.
Diese zwei waren für mich die Motivation, mich überhaupt näher mit dem Thema zu beschäftigen.
Überblick
IPFS - Das InterPlanetary File System kann über ein Modell aus mehreren Stufen/Layern/Schichten beschrieben werden.
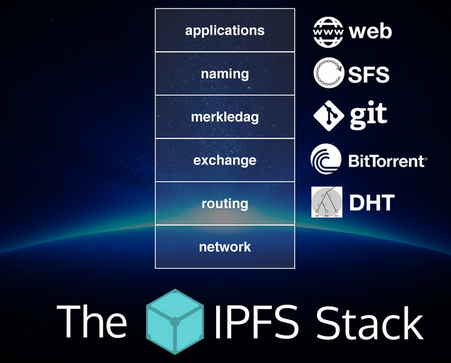
Lasst uns nun gemeinsam diese Stufen mal anschauen und ein paar Überlegungen anstellen. Wir starten von unten nach oben:
Stufe 1 - Identitäten (Namensvergabe)
Nenn mich "Klaus" oder besser doch "QmHUwFkz75Cpa9p2SamGEu8tDnQqUvANzYpimj9uead"
IPFS ist strukturell ein P2P Client-Netzwerk ohne zentrale Server. Die Clients sind die "Nodes" des Netzwerkes.
- Node A muss für Node B usw... identifizierbar sein.
Wie könnte man das machen: Einfach durch nummerieren? Das hätte mehrere Probleme:- Ich wüsste nicht, welche Nummer ich mir geben müsste ohne eine zentrale Instanz.
- Ich könnte mich einfach A nennen und mich somit als "A" ausgeben.
Wie löst man das Problem?
Mit Krpytographie:
- generiere ein Public-Private Key Pair
- hashe den Public Key -> das ist dann die "NodeId"
- Genau das passiert in der
ipfs initPhase. Die Keys werden der Datei"~/.ipfs/config"gespeichert.
- Genau das passiert in der
Wie reden nun 2 Nodes miteinander?
- Sie tauschen die Public Keys aus
- Sie hashen den erhaltenen Public Key und prüfen, ob er der NodeId des anderen entspricht
- Falls ja ist die andere Node identifiziert und es kann weiter gehen
- Falls nein wird die anderen Node als Fake abgestempelt
Stufe 2 - Netzwerken mit anderen Clients sprechen
Hier bin ich, wie geht's weiter?
IPFS läuft einfach auf allen vorhandenen Netzwerken. Die Node nutzt dafür ein Multiformat: multiaddr.
Das beinhaltet auf jeden Fall schon mal sämtliche lokal vorhanden IPv4 und IPv6 Adressen. Ihr seht das auch, wenn ihr den "ipfs daemon" startet.
Das könnte dann so oder so ähnlich aussehen:
Swarm listening on /ip4/127.0.0.1/tcp/4001
Swarm listening on /ip4/172.17.0.1/tcp/4001
Swarm listening on /ip4/185.24.123.123/tcp/4001
Swarm listening on /ip6/2a02:1234:9:0:21a:4aff:fed4:da32/tcp/4001
Swarm listening on /ip6/::1/tcp/4001
API server listening on /ip4/127.0.0.1/tcp/5001
Gateway (read-only) server listening on /ip4/0.0.0.0/tcp/8080
Stufe 3 - Routing
Wo geht's lang?
Hier geht es darum Inhalte/Content zu finden oder bekannt zu machen. IPFS nutzt dafür verteilte Hashtabellen (DHT).
DHT ist ein Konzept von dem es verschiedene Implementierungen gibt. Die Ziele davon sind:
- bekannt machen, dass eine Node Daten hat
- herausfinden, welche Nodes bestimmte Daten haben (gezielt finden)
Etwas abstrakt? -> Machen wir ein Beispiel - Praxisexkurs (1)
Wir suchen uns ein vorhandes Video im IPFS Netzwerk und wollen herausfinden, wo es überall liegt. Ein willkürlich gewähltes Beispiel ist das Tutorial von @SemperVideo "Raspberry Pi: IPFS-Node installieren"
# Rechtsklick -> Video-Adresse kopieren
https://scrappy.i.ipfs.io/ipfs/QmWpXDwA6xoBZmTiT7dGkhkNSBAsamGkpVGuHFVWCGk1aK
"QmWpXDwA6xoBZmTiT7dGkhkNSBAsamGkpVGuHFVWCGk1aK" -> ist also der Hash der Datei
Nun fragen wir mal ins Netzwerk, welche Nodes die Datei vorhalten:
ipfs dht findprovs QmWpXDwA6xoBZmTiT7dGkhkNSBAsamGkpVGuHFVWCGk1aK
QmXcy1qwtajcrABVrYLmMVss9X2tAUJW5jcLCuxwgQ7Rq1
Qmf5g6bSXxmbi7ciNf89ok4eBG2LSVoDrvQCni5tBH8Eqj
QmaJLsFGurEzueWdsuwq5bjKkZfHRNjkjgSuTpQT516xyq
Die 3 Antworten bedeuten für uns, dass die Datei auf 3 Servern verfügbar sein sollte. Diese 3 Antwort-Hashes sind die 3 NodeIds von den Nodes, die die Datei vorhalten.
Nun nehmen wir uns einfach mal die goldene Mitte und schauen mal, wie wir den Kollegen erreichen können.
ipfs dht findpeer QmaJLsFGurEzueWdsuwq5bjKkZfHRNjkjgSuTpQT516xyq
/ip4/127.0.0.1/tcp/4001
/ip4/127.0.0.2/tcp/4001
/ip4/84.200.206.112/tcp/4001
/ip6/::1/tcp/4001
Was machen wir nun mit der Info? Eigentlich gar nichts. Denn wenn wir eine Datei herunter laden wollen, suchen wir nicht manuell vorher die Node aus. Genau diese Aufgabe übernehmen die DHT für uns.
Wir können einfach sagen, ich will die Datei "QmWpXDwA6xoBZmTiT7dGkhkNSBAsamGkpVGuHFVWCGk1aK". Die Aufgabe des Routing Layers (DHT) ist es den effizientesten Weg zu der Datei zu finden und uns den geeigneten Sendepartner zu beschaffen.
Also los, laden wir die Datei mal zu uns:
ipfs get QmWpXDwA6xoBZmTiT7dGkhkNSBAsamGkpVGuHFVWCGk1aK
Saving file(s) to QmWpXDwA6xoBZmTiT7dGkhkNSBAsamGkpVGuHFVWCGk1aK
11.83 MB / 11.83 MB [=============================================================================================================================================================================================================================================] 100.00% 1s
# schauen wir mal ob sie da ist
ls -ahl | grep QmW
-rw-rw-rw- 1 root root 12M Feb 9 10:43 QmWpXDwA6xoBZmTiT7dGkhkNSBAsamGkpVGuHFVWCGk1aK
Ok Anfängerfehler: Schöner hash, aber ich bin Mensch und will lesbare Dateinamen. Da die Datei nun einmal schon da ist, finden wir schnell heraus, was es für eine Datei ist (Dateityp) und laden sie noch mal neu.
file QmWpXDwA6xoBZmTiT7dGkhkNSBAsamGkpVGuHFVWCGk1aK
QmWpXDwA6xoBZmTiT7dGkhkNSBAsamGkpVGuHFVWCGk1aK: ISO Media, MP4 Base Media v1 [IS0 14496-12:2003]
ipfs get -o "Tutorial_Raspi_IPFS_Node_installieren_SemperVideo.mp4" QmWpXDwA6xoBZmTiT7dGkhkNSBAsamGkpVGuHFVWCGk1aK
Saving file(s) to Tutorial_Raspi_IPFS_Node_installieren_SemperVideo.mp4
11.83 MB / 11.83 MB [=============================================================================================================================================================================================================================================] 100.00% 0s
ls -ahl | grep Tutorial
-rw-rw-rw- 1 root root 12M Feb 9 10:54 Tutorial_Raspi_IPFS_Node_installieren_SemperVideo.mp4
Nach diesem kurzen Ausflug in die Praxis, zurück in die Theorie.
Wer noch etwas mehr über DHT an sich verstehen will, dem lege ich das 8:44 Minuten Video ans Herz:
Stufe 4: Exchange
Es ist ein Geben und ein Nehmen.
Stufe 3 (Routing, DHT) hat uns den optimalen Weg zu einer Datei gezeigt. Jetzt geht es um das eigentliche Senden und Empfangen.
Die Daten werden dazu in Blöcke unterteilt und der Exchange-Layer ist dafür verantwortlich diese Blöcke zu verteilen.
Das Protokoll was hierfür verwendet wird, nennt sich Bitswap.
Bitswap erfüllt zwei wesentliche Aufgaben:
- Akquirieren von Blöcken die ein Client anfragt
- Übergeben von Blöcken an Nodes, die sie haben wollen, in einer sinnvollen Weise
Man kann sich das als einen Marktplatz vorstellen, dessen Anreiz es ist Daten zu replizieren.
- Wenn sich Nodes verbinden tauschen sie 2 Listen
- "Das hab ich"-Liste (have_list)
- "Das will ich"-Liste (want_list)
- Jede Node kann dabei ihre eigene "Bitswap Strategie" haben
- Wenn zwei Nodes Blöcke austauschen, zählen sie mit wieviel Daten sie teilen und wieviel Daten sie bekommen.
- Man könnte anders sagen: Sie bauen ein Guthaben (builds credit) und Schulden (builts debt) auf.
- Die Buchführung zwischen 2 Nodes wird im "BitSwap Ledger" (Kassenbuch) gemacht
- Das heißt eine Node hat entweder mehr gesendet oder mehr empfangen. Daraus lässt sich eine Bewertung ableiten und eine Node die nichts beiträgt, kann so aus dem System entfernt werden.
Kurzer Exkurs in die Praxis (2)
Jetzt müsste ja meine Node bei einem der Peers von unserem Download vorhin "Schulden" haben:
ipfs bitswap ledger QmXcy1qwtajcrABVrYLmMVss9X2tAUJW5jcLCuxwgQ7Rq1 \\
&& ipfs bitswap ledger Qmf5g6bSXxmbi7ciNf89ok4eBG2LSVoDrvQCni5tBH8Eqj \\
&& ipfs bitswap ledger QmaJLsFGurEzueWdsuwq5bjKkZfHRNjkjgSuTpQT516xyq
Ledger for <peer.ID Xcy1qw>
Debt ratio: 0.000000
Exchanges: 0
Bytes sent: 0
Bytes received: 0
Ledger for <peer.ID f5g6bS>
Debt ratio: 0.000000
Exchanges: 0
Bytes sent: 0
Bytes received: 0
Ledger for <peer.ID aJLsFG>
Debt ratio: 0.000000
Exchanges: 0
Bytes sent: 0
Bytes received: 0
Irgendwie ist das aber nicht das erhoffte Ergebnis. Die Anzeige sagt mir: Es gibt keine "Schulden" und überhaupt keinen Austausch. Ich habe die Datei aber bekommen und das waren die 3 Peers, die sie hatten.
Seltsam - ich habe keine Ahnung warum das so ist. Wer weiß wieso, kann das gerne kommentieren!
Stufe 5: Objekte
Wie organisieren wir die Daten?
Über merkleDAG. Wer das noch nie gehört hat, ist damit nicht allein. Wir sind schon mindestens zwei :)
Abbildung eines "DAG - directed acyclic graph"
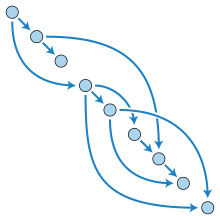
Nehmens wir's mal auseinander:
- Die Daten werden in einem Graphen abgebildet. Das heißt man kann von Stelle X1 auf X2 verweisen.
- Jeder Teil dieses Graphen wird als Objekt bezeichnet
- So ein Objekt kann Daten enthalten
- und/oder Links zu anderen Objekten
- Diese Links nennt man Merkle Links und das sind die Hashes der Zielobjekte
Diese Art der Organisation hat einge nützliche Features:
- Inhaltsadressierung
- Jeder Inhalt kann eindeutig identifiziert werden, durch das Hashing, Multihashing, Verketten von Hashes
- Fälschungssicherheit
- Jeder Inhalt kann mit seiner Checksumme geprüft werden. Wenn Daten bei dem Transfer manipuliert werden oder kaputt gehen, würde das auffallen.
- Deduplizierung
- Wenn der Content gleich ist, ist logischerweise auch der Hash gleich. Demnach muss eine Datei die exakt so bereits vorhanden ist, nicht nochmal hinzugefügt werden.
Etwas weiterführende Details und eine Visualisierung findet ihr zum Beispiel hier.
Stufe 6: Versionierung
Hier soll eine an git angelehnte Versionierung stattfinden. Dazu konnte ich aber keine Informationen finden, die ich verstanden hätte und überspringe den Punkt deshalb erstmal.
Stufe 7: Namensgebung
Nenn mich wie du willst, gib mir deinen Namen...
Aufrund der Hashingkette ist Content, wie in Stufe 5 gelernt, adressierbar. Das hätte zur Folge, dass eine Änderung die Adresse verändern würde.
Um das Problem zu lösen, werden Zusätze genutzt (Labels und Pointer), die den eigentlichen Inhalt nicht verändern.
Dieses System heißt IPNS (Inter-Planetay Naming System) - sozusagen das Namenssystem von IPFS. Das funktioniert grob so:
- Die Startadresse einer Node ist
/ipns/<NodeId><- beachtet das ipns - Der Inhalt auf den sie zeigt kann verändert werden, indem ein IPFS Objekt auf diese Adresse zeigt
- Durch das Publizieren signiert der Besitzer der Node mit dem Private-Key der bei
ipfs initentstanden ist den Pointer (Verweis/Zeiger).- So können andere Nutzer prüfen ob die Objekte authentisch sind
- Genau wie bei IPFS Pfaden starten auch IPNS Pfade mit einem Hash und dann geht's weiter mit einem Unix-Format ähnlichen Pfad
- IPNS Einträge werden ebenfalls über DHT bekannt gegeben und aufgelöst
Etwas theoretisch - kurze Überlegung für die Praxis (3)
- Ich könnte auf die Idee kommen eine Website im IPFS anzubieten.
- Sagen wir meine Website ist nur eine Datei "index.html"
- Ich kann die Datei erstellen und in IPFS adden, dann hab ich einen Hash den ich mit jedem teilen kann.
- Die Datei wird repliziert auf andere Nodes und so weiter, alles was wir bisher gelernt haben.
- Wenn ich meine Website jetzt ändern will, folgt ->
- Ich erhalte einen neuen Hash und im Prinzip eine neue Datei, so dass meine "Besucher" immer noch auf der alten landen und die neue gar nicht mitbekommen.
- Jetzt müsste ich ja jedem Bescheid sagen, dass es eine neue Website gibt - und das bei jeder Änderung. Das wird nie funktionieren.
- Die Lösung wäre, dass ich nicht auf meine Website direkt verweise, sondern auf einen "Alias" hinter dem ich den Inhalt dann beliebig austauschen kann.
- Und richtig heiß
 wird es dann, wenn ich den Alias nicht nur an einer Stelle habe, sondern der auch noch im Netzwerk verteilt wird (mit allen Vorteilen des Systems)
wird es dann, wenn ich den Alias nicht nur an einer Stelle habe, sondern der auch noch im Netzwerk verteilt wird (mit allen Vorteilen des Systems)
- Und richtig heiß
- Genau diese Aufgabe übernimmt IPNS
Fazit
Ich habe heute einiges über IPFS gelernt und ich hoffe, dass jetzt mit diesen Grundlagen weiter in das System einsteigen kann. Vor allem hoffe ich, dass euch der Artikel auch weiter geholfen hat und freue mich über Kommentare!
This is a test comment, notify @kryzsec on discord if there are any errors please.
Being A SteemStem Member
Ich hoffe da kommt noch mehr und ich verstehe dadurch jetzt auch wieder etwas mehr.
Grade so englische Seiten durch zuarbeiten oder mit den Entwicklern in englisch zu kommunizieren fällt mir doch eher schwer.
Da finde ich es gut mal so etwas zusammengefasst zu erfahren was du so raus gefunden hast.
Mich interessiert aktuell vor allem wie ich gut einen eigenen Node betreiben kann, der auch was zum System beiträgt und auf was man so achten muss wenn man den konfiguriert.
Danke für deinen Kommentar. Es freut mich, wenn das jemand hilft. Ich werde mich in nächster Zeit weiter mit ipfs und dem Betreiben einer eigenen ipfs node beschäftigten und die Erkenntnisse hier teilen.
Erstmal danke für die Erwähnung :D
Bitte entschuldige, dass ich so lange gebraucht habe ... Die letzten Tage gingen drunter und drüber.
Nun weiß ich auch wo ich die ipfs config finde, super :D (unter Linux hätte ich sofort so gesucht ... aber unter Windoof bin ich immer noch zu sehr an die grafische Oberfläche gebunden, wie es scheint).
Die Erklärungen waren echt aufbereitet! Sehr schön nachvollziehbar und gar nichtmal so technisch. Ich denke hiermit wird jeder gut verstehen wie das IPFS aufgebaut ist und wie es im groben funktioniert.
Leider simmt es, dass es bei meinem aktuellen Problem nicht wirklich hilfreich ist.
Aber Anhaltspunkte liefert es dennoch. Denn anscheinend spielt die Verteilung da eine Rolle, wenn es darum geht, dass die Internetfähigkeit meines Rechners komplett zusammenbricht. Laut @SemperVideos Kommentar unter meinem Beitrag soll dies angeblich nicht das angestrebte Verhalten sein.
Mal sehen wann es da neue Entwicklungen gibt. Vielleicht soll es aber einfach nur auf dedizierte Server ausgelegt sein. In diesem Fall fände ich es schwierig das darüber weiter zu betreiben. Ich hoffe die angekündigte Desktop App von @DTube wird da ein bisschen Zügelung betreiben und Kontrolle ermöglichen.
Wir werden sehen :)
Der Post wird auf jedenfall resteemed! Upvote hattest du ja bereits von mir erhalten.
Danke für die Ausführliche Behandlung des Themas
Ich habe IFPS auf einem Ubuntu V Server installiert.
Ich möchte Videos von anderen anpinnen, damit ich diese auf meinem Server habe und dann weiter verteilt werden können und damit die Daten nicht so schnell aus dem Netzwerk gelöscht werden.
Wie mache ich das am besten? Mit ipfs pin add >Hash< dauern kleine Bilder schon sehr lange, ganze Video extrem lange. So lange das ich das dann schon abbreche. Gibt es vielleicht sogar die Möglichkeit, dass ich die Hash Werte in eine Text Datei packe und der Server arbeitet die nach und nach ab?