[저 세상 정리] MIT 6.S191 2강
[저 세상 정리]는 내 맘대로 이해한 강의 내용을 내 맘대로 정리하는 post이므로 매우 부정확할 수 있음
MIT 6.S191 Introduction to Deep Learning #2
두 번째 강의 내용은 sequential data를 처리하는데 적합한 network를 소개한다. 우선 sequential data의 특징을 알아보자. Sequential data는 example 하나당 data의 수가 다양하고 각 data는 서로 복잡하게 연관되어 있다. 우리가 쓰는 문장이나 음성의 wave form이 sequential data에 속한다.
그렇다면 sequence modeling은 어떻게 할까. 예시를 통해 sequence modeling이 얼마나 까다로운지 알아보자.
"This morning I took the dog for a walk."
이런 문장이 있는데 여기서 "This morning I took the dog for a" 까지만 주어지고 그 후에 올 단어("walk")를 예측하려면 어떡해야 할까. 이전 시간에 배웠던 NN을 생각해보면 network의 input size는 고정되어 있어야 한다. 즉 modeling을 할때 fixed length로 지정해줘야 한다. 하지만 위의 문장은 예시일 뿐이고 input으로 들어올 문장의 길이는 다양하기 때문에 이런 variable length input을 fixed length vector로 변환하는 것이 필요하다.
하나의 방법은 fixed window를 사용하는 것이다. 예를 들면 위의 예시 문장에서 "for a" (크기 2의 window)만 보고 "walk"를 예측하는 것이다.
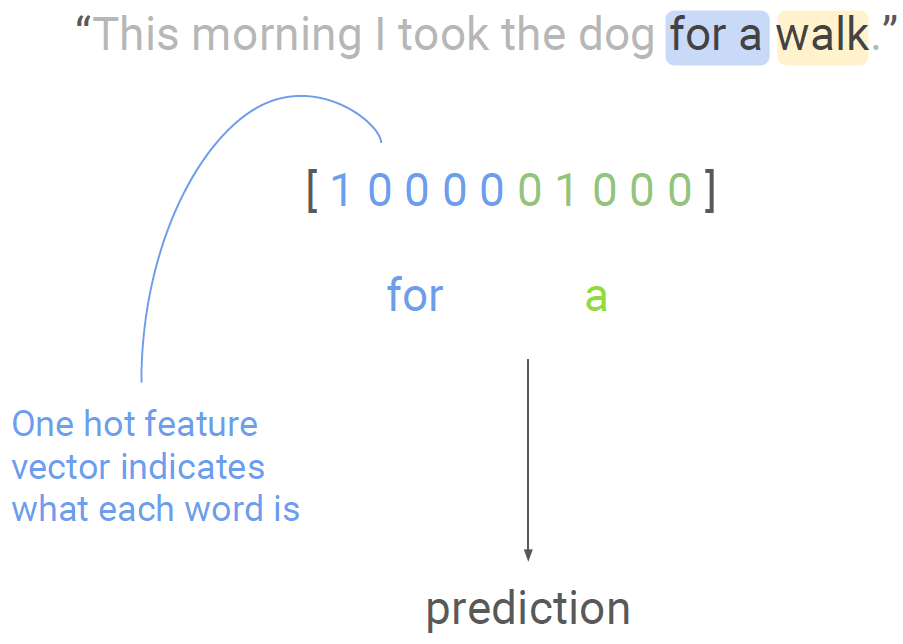
이런 방법을 사용하면 어떤 단어든 fixed length vector로 나타낼 수 있기 때문에 feed-forward network에 사용할 수 있다. 하지만 문제점이 있다. 다음 문장을 보자.
"In France, I had a great time and I learnt some of the ______ language."
빈칸에 들어갈 단어를 추론하기 위해서는 문장 맨 앞에서 정보를 얻어야한다. 하지만 fixed window를 사용한다면.. 한계점이 분명히 보인다. Fixed window를 사용하면 fixed length vector를 만들 수는 있지만 위의 예시처럼 오래 전(?)의 정보는 사용할 수 없게 된다. 이런 문제를 problem of long-term dependency라고 한다.
자, 그럼 다시, fixed length vector는 필요한데... fixed window는 별로다, sequence의 모든 정보를 활용하고 싶다! 그럼 fixed window 말고 그냥 sequence 전체를 써보자! 근데 어떻게?
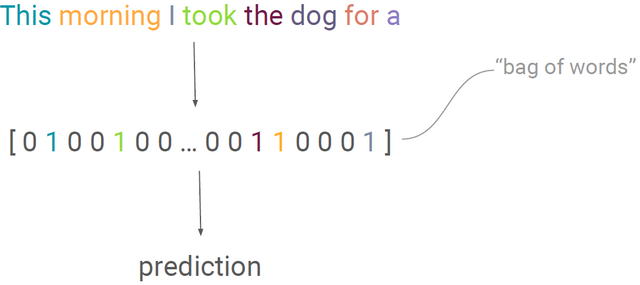
방법은 간단하다. "Bag of Words"라는 방법인데, 각 단어들이 그 문장 안에 얼마나 있는지 카운팅하는 것이다. 위의 벡터를 보면 각 slot은 단어를 의미하고 slot 내의 숫자는 그 단어의 출현 빈도를 나타낸다. 이 방법을 사용하면 단어 수에 상관없이, 즉 문장의 길이에 상관 없이 fixed length vector를 만들 수 있고 문장 전체를 활용할 수 있다. 하지만..bag of words는 sequence의 순서를 반영할 수 없다. 이는 sequential data를 다루는데 큰 문제로 작용할 수 있다.
"The food was good, not bad at all." vs "The food was bad, not good at all."
위 두 문장을 보면 완전 정 반대의 뜻이다. 근데 문장을 구성하는 단어의 종류와 그 수가 똑같기 때문에 완전히 동일한 bag of word를 갖는다.
자, 다시.....sequence의 순서도 놓치고 싶지 않고 sequence를 통으로 이용하고 싶기 때문에 fixed window도 싫다.
그럼 좀 절충안으로 좀 큰 window를 사용하는건..? a really big fixed window!!
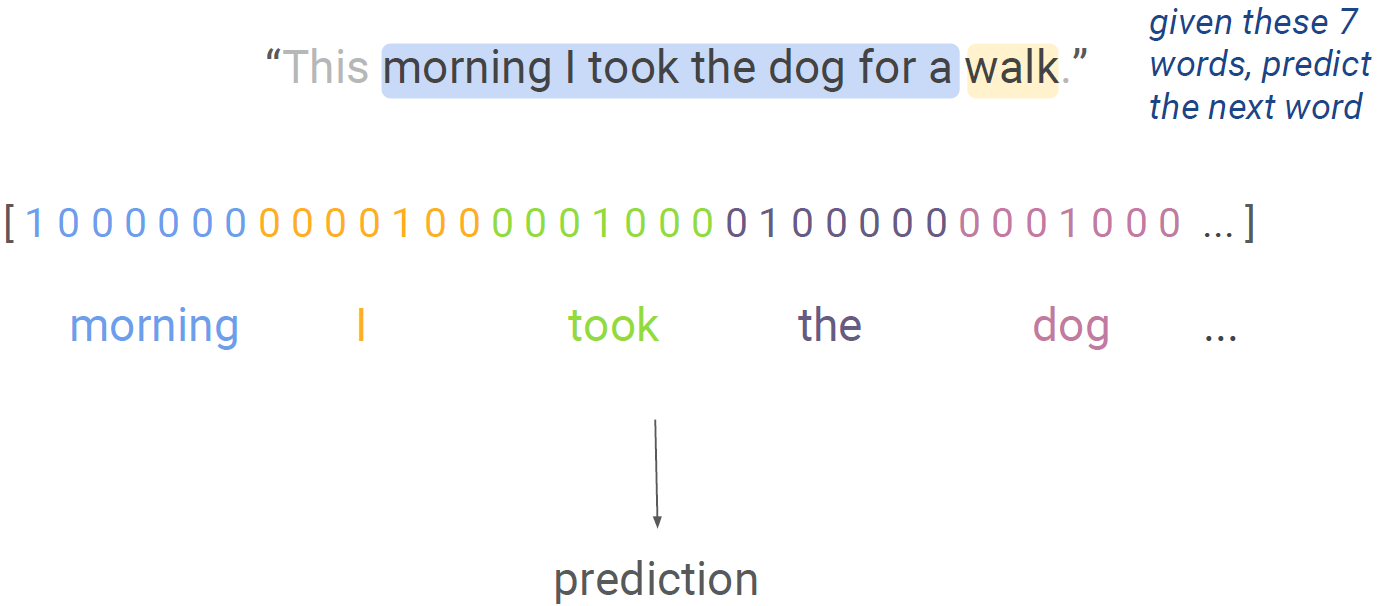
위 예시에서 크기 7의 window를 사용했는데 문장 길이를 고려하면 big window가 맞다. 아무튼 그 어느 문장이 와도 big enough한 fixed window를 쓴다고 해보자. 그래도 문제는 생기..ㄴ.....쒸익쒸익

문장 구조상 this morning은 문장 앞에 올 수도 있고 문장 뒤에 올 수도 있다. 문제는 this morning이 문장 앞에 오나 뒤에 오나 의미는 같은데 network는 그걸 모른다. 왜냐...vector의 앞 부분에 연결된 뉴런(weight)와 vector 뒷 부분에 연결된 뉴런(weight)가 서로 공유되지 않기 때문이다. 무슨 말이냐면, 만약에 this morning이 주로 문장 앞에 위치하면 network 입장에서는 this morning이 뒤에 있는 문장을 본 적이 없을 것이다. 따라서 this morning이 뒤에 위치한 문장을 받았을 때 전혀 새로운 문장으로 인식할 것이다. 일반화 시켜서 표현을 해보자면, network가 어떤 sequence를 학습했는데 weight가 서로 공유되지 않으면 sequence내 data의 순서가 뒤바뀐다면 새로운 sequence로 인식할 것이다.
위의 내용들을 정리해보면!! Sequence modeling을 위해서는
1. variable-length sequence 커버 가능해야하고
2. sequence 순서도 보존해야하고
3. problem of long-term dependency도 해결해야하고
4. sequence끼리 weight도 공유되어야함..
그래서 해결책은!!! RNN(Recurrent Neural Networks)
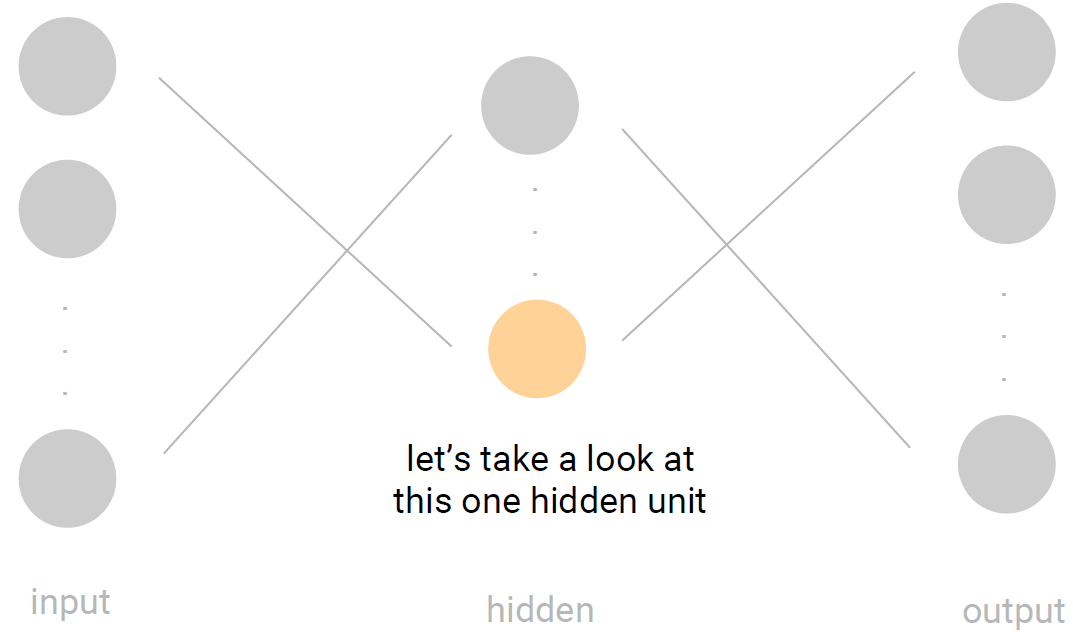
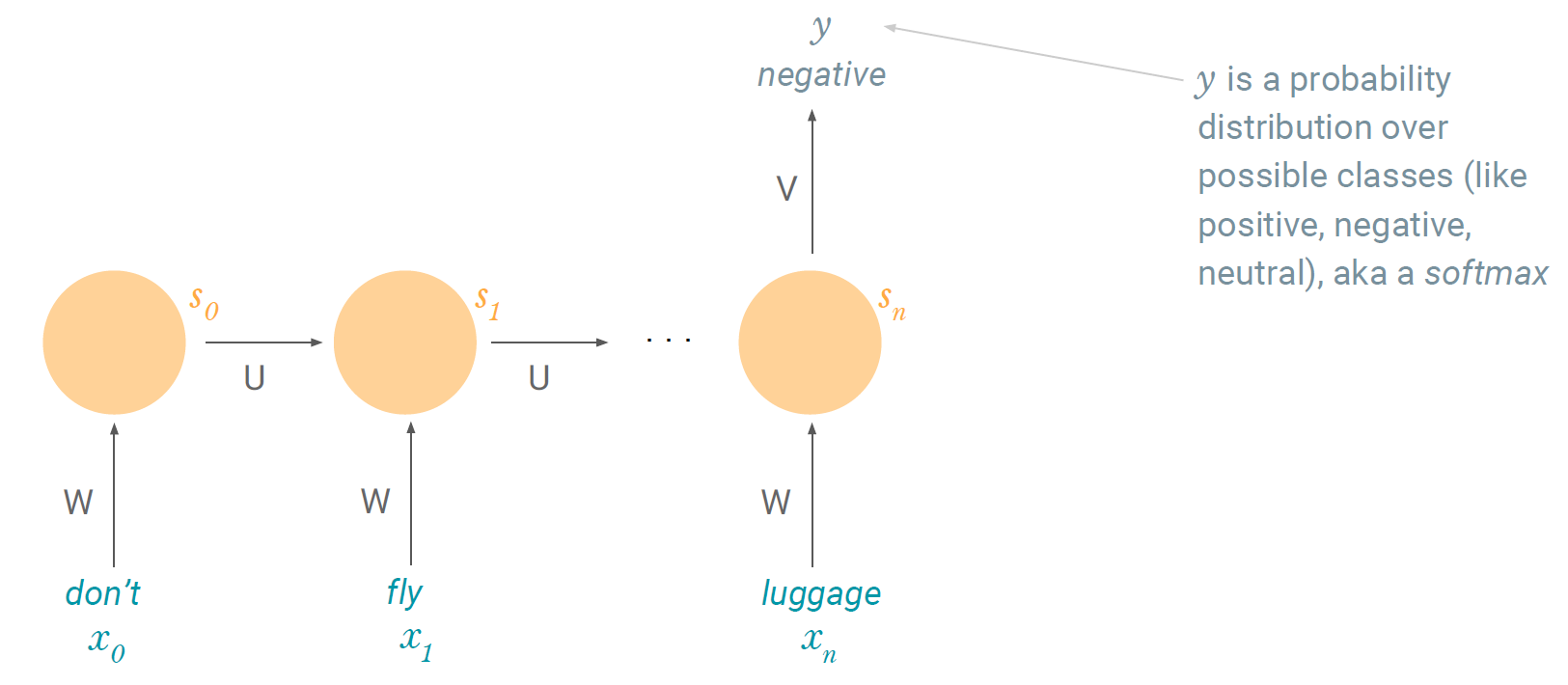
저번 시간에 우리가 배웠던 NN은 위와 같은 구조를 갖는다. RNN도 구조는 비슷한데 핵심인 뉴런(perceptron)의 기능이 조금 다르다.
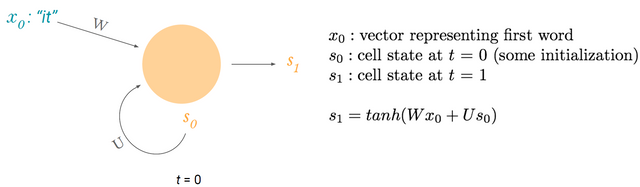
위 그림은 RNN cell(뉴런)의 기능을 도식화한 것이다. Sequential data이기 때문에 time step 't'가 있는데, 위 그림은 초기 t=0 일 때를 나타낸다. 다음 그림을 이어서 보자.
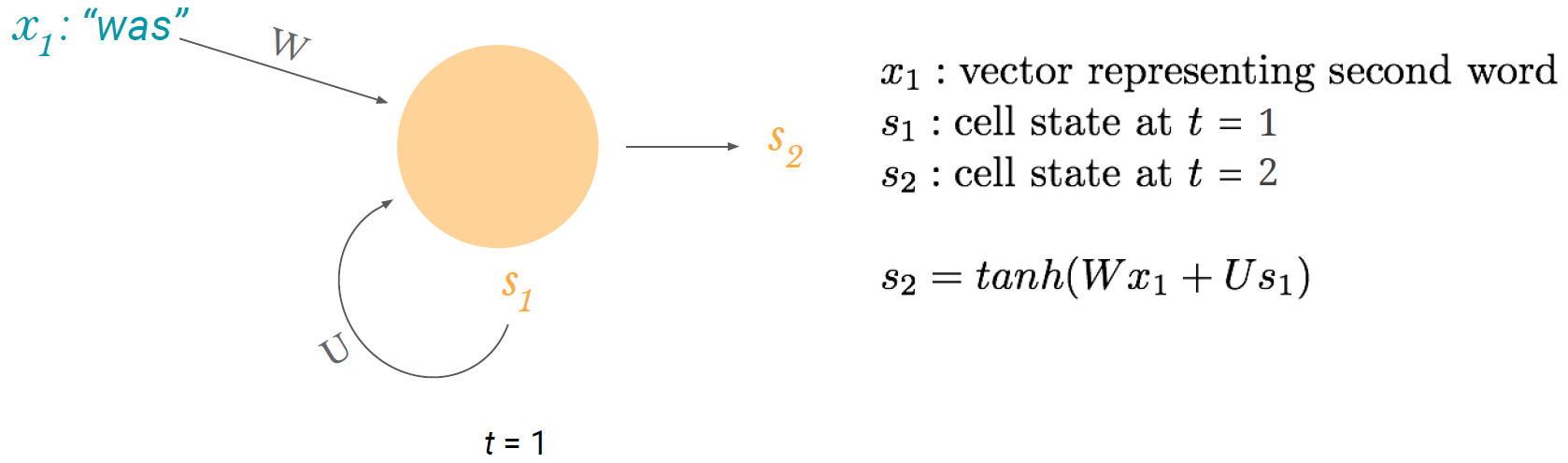
새로운 input으로 x_1이 들어오고 방금과 같은 과정을 거쳐 다음 time step으로 s_2를 전달한다. 눈썰미가 좋다면 눈치챘을 사실! Sequential data이기 때문에 time step이 있다고 했고, 그에 따라 모든 notation에는 time step이 sub로 표기된다. 단 W와 U만 제외하고.. W와 U는 모두 weight matrix를 뜻하는데, time notation이 없다는 것은! 모든 time step에서 동일한 W와 U를 공유한다는 뜻이다. (parameter sharing)
주목할 점은 또 있다. 다음 time step으로 cell state(s)를 전달하는 과정을 보면 현재 time step에서 새로 들어온 input(x) 뿐만 아니라 현재 time step의 cell state도 같이 넘기는 것을 볼 수 있다. 정리해보면 미래의 cell state는 과거의 모든 정보를 담는다. (long-term dependency)
이런 구조를 시간에 따라 unfolding 해보면...
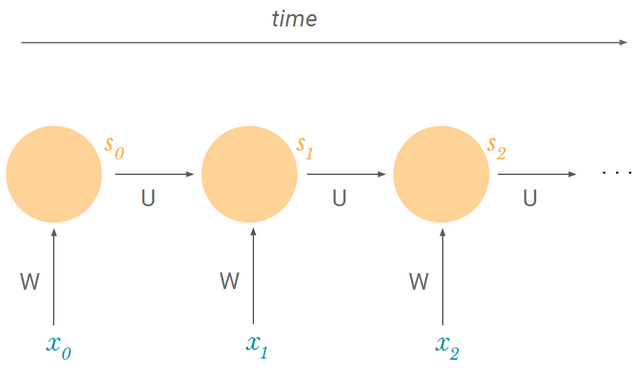
문제를 해결했으니 학습을 시켜봅시다. 얘도 NN과 똑같이 backpropagation을 하는데 time이 추가되었으니 backpropagation through time, 줄여서 BPTT라 한다.
우선 loss를 구해보자.
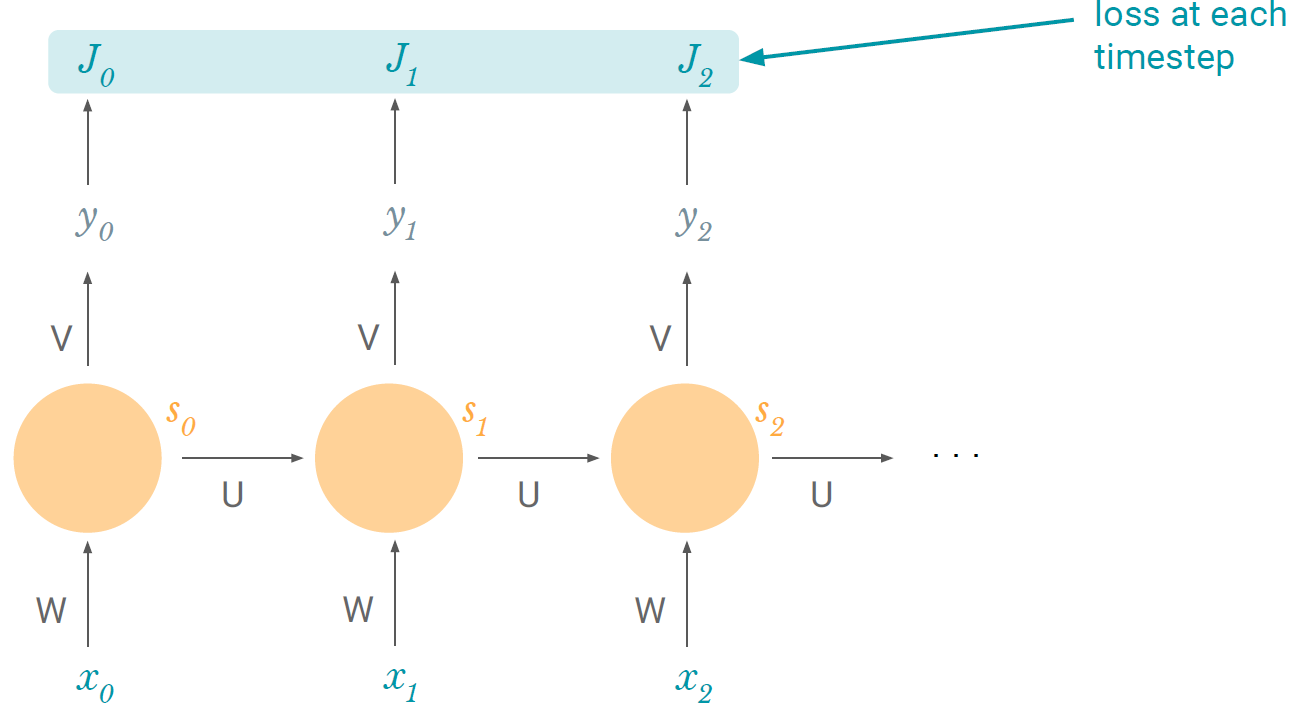
위 그림처럼 각 time step마다 loss를 구할 수 있고, 그들을 다 합친 것이 total loss이다. Gradient도 마찬가지다. 각 time step마다 gradient를 구하고 모두 합하면 total gradient가 된다. 다음 그림을 보고 chain rule을 사용하여 W에 대한 time step t에서의 gradient를 구하는 과정을 알아보자.
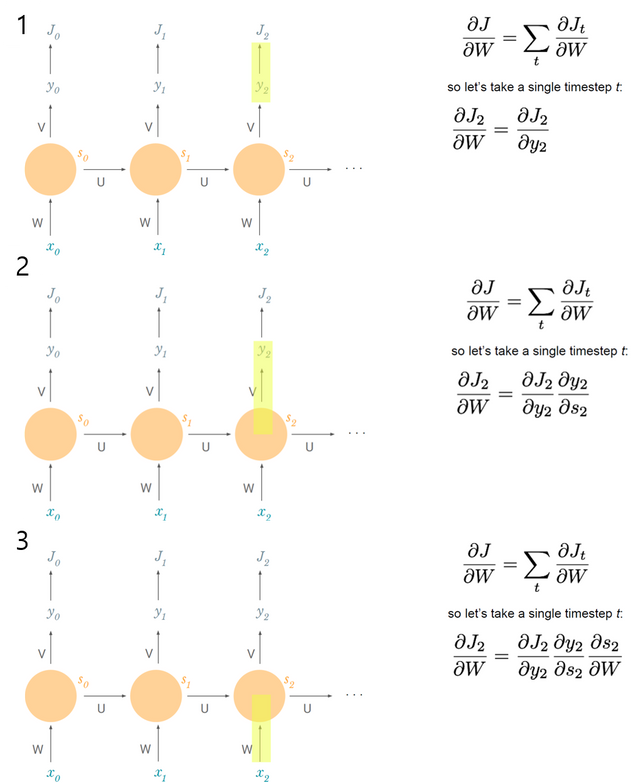
끝! 인데 끝이 아니다. (!?) RNN의 chain rule은 그리 간단하지 않다...ㅜ 다음 그림..
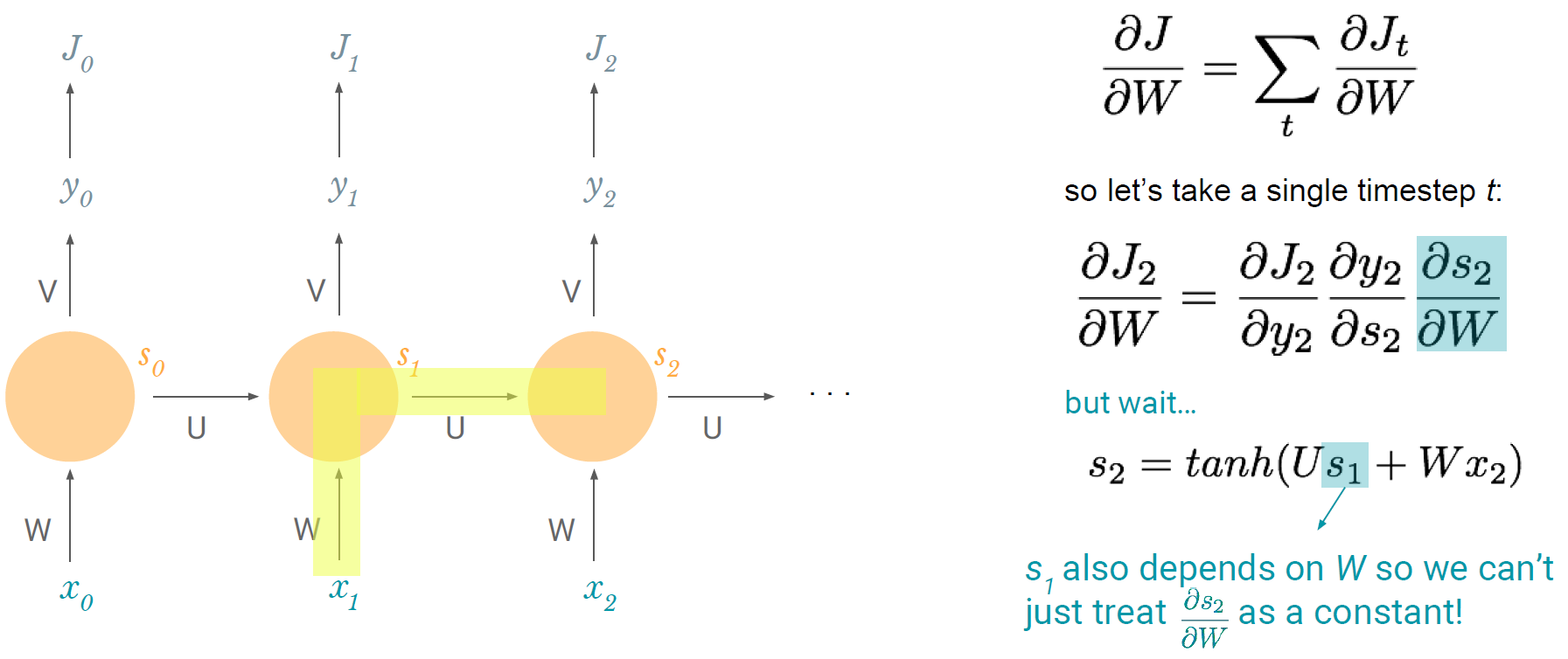
끝인 줄 알았지만 안 끝난 이유는 다음과 같다. s_2는 s_1과 연관이 있고 s_1은 또 W와 연관되어 있다. 다 얽히고 설켜서 chain rule을 위와 같이 끝내면 안되고, s_2와 W의 관계를 다시 chain rule을 이용하여 풀어줘야 한다.
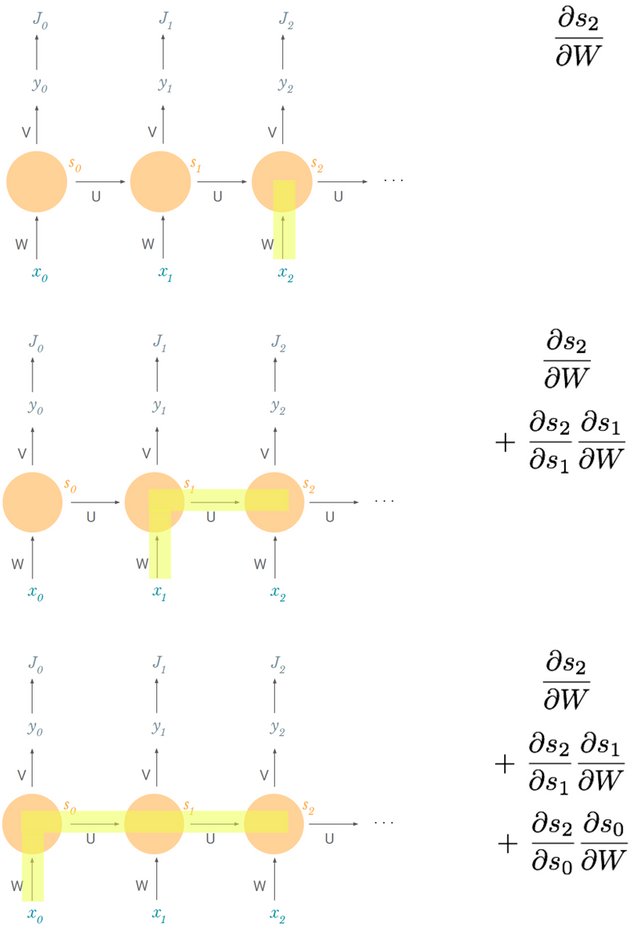
드뎌 완성.. 수식으로 일반화하여 표현하면
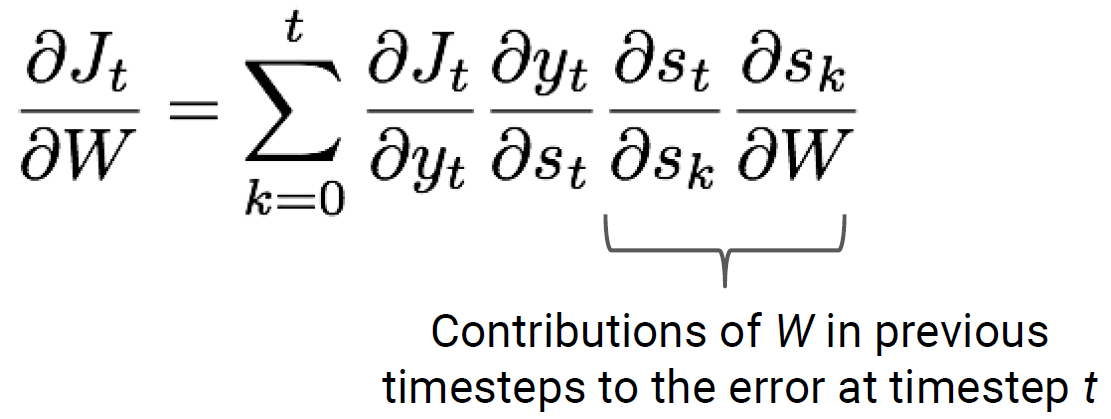
이렇게 loss를 구하고 gradient를 이용하여찾으면 global minimum을 training 끝이다. (이론상으로는...)
RNN은 사용상의 문제점이 있다. 바로 vanishing gradient 문제다. 다음 그림을 보고 s_n을 s_0로 편미분하는 것을 생각해보자.
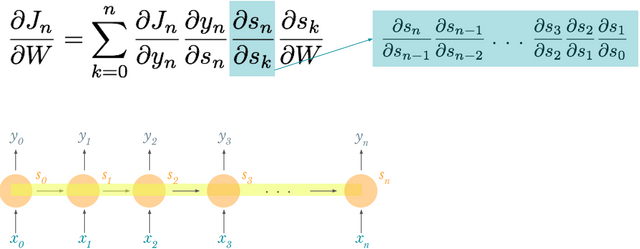
식을 보면 알겠지만 n이 커질수록 곱연산 또한 많아진다. 왜 이게 문제가 되냐! 저 곱연산에 사용되는 term 하나만 떼어와서 보면
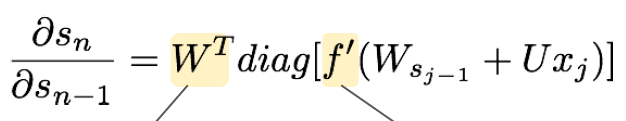
이렇게 생겼는데, 이 수식이 어떻게 유도됐는지는 여기서 중요한 것이 아니고 왜 이 수식이 문제가 되느냐다. 보통의 W는 가우시안 분포로부터 추출되기 때문에 대부분 1보다 작은 값을 갖는다. 그리고 activation function인 f는 보통 tanh나 sigmoid를 사용하기 때문에 f'은 1보다 작은 값을 갖는다.
다시, 전체 곱연산 수식을 보자. 위의 의미대로 저 식을 계산해보면 계속해서 1보다 작은 값을 곱하고 있는 것이고 그에 따라 결과값도 매우 작을 것이다.
자 그러면! n과 0의 차이가 클수록(n이 커질수록) 에러가 강제로 작아진다. Backpropagation을 통해 에러를 교정해 나가야하는데 먼 과거일 수록 에러가 강제로 작아져서 교정할 수가 없게 되는 문제점이 있다. 상대적으로 가까운 과거의 에러가 크게 다가오는 것이다(short-term dependency). 결국 problem of long-term dependency 재발..
해결책 1. activation function 교체
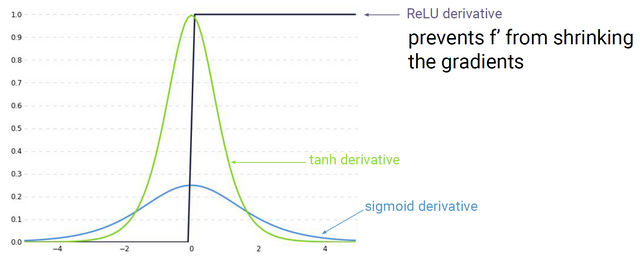
ReLU 함수는 input x가 음수이면 0, 0 이상이면 x를 반환하는 함수다. 따라서 0보다 큰 범위에서 미분값은 1로 동일하기 때문에 vanishing gradient 문제를 해결할 수 있다.
해결책 2. weight matrix 초기화 방법
가우시안 분포에서 추출하는 대신 identity matrix로 초기화하면 weight로 인해 gradient가 감소하는 문제를 해결할 수 있다.
해결책 3. 좀더 정교한 cell 사용
이런 정교한 cell의 종류에는 여러가지가 있는데 LSTM(Long Short Term Memory)이나 GRU(Gated Recurrent Unit)가 대표적이다. 이 수업에서는 LSTM만 조금 다룬다. LSTM은 크게 3 부분으로 나뉜다.
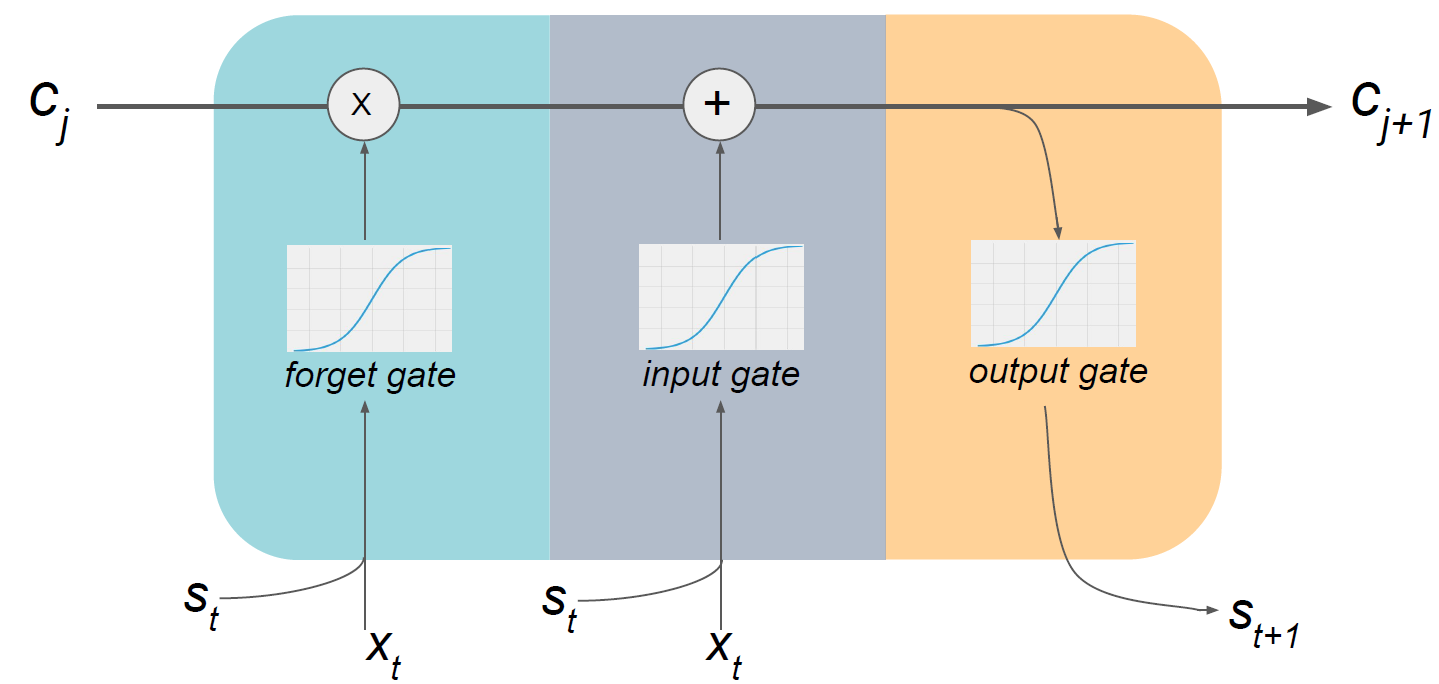
1. 이전 state에서 별로 관련 없는 부분을 잊어버리는 forget gate
2. cell state를 선택적으로 update하는 input gate
3. cell state의 certain part를 output하는 output gate
1번을 착각하면 안되는 것이 무조건 잊어버리는 것이 아니라 그대로 유지할 수도 있다. 그리고 RNN에서는 cell state가 곧 output이었는데 LSTM은 그 둘이 구분이 된다.
뭐 이정도로만 LSTM을 다루고 있다. 다음은 LSTM이 어떻게 사용되고 있는지 성공 사례를 보여주는 그림들로 마무리 한다.
1. 트위터 감정 분석(classification)
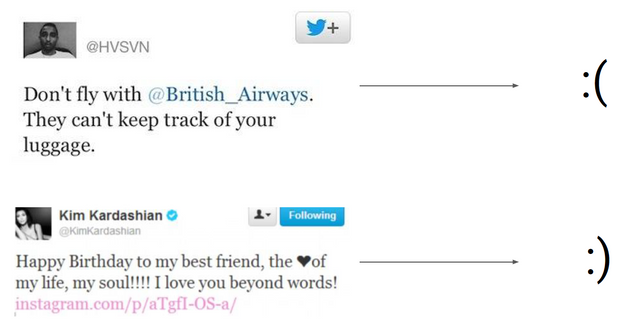
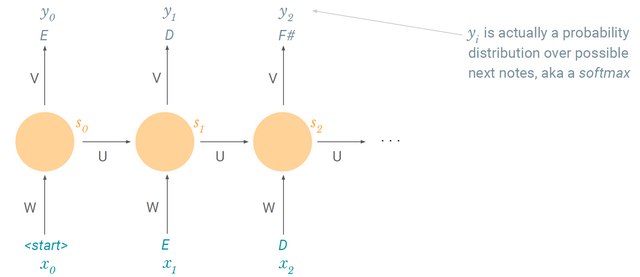
2. 음악 생성(generation)
3. 번역(translation)
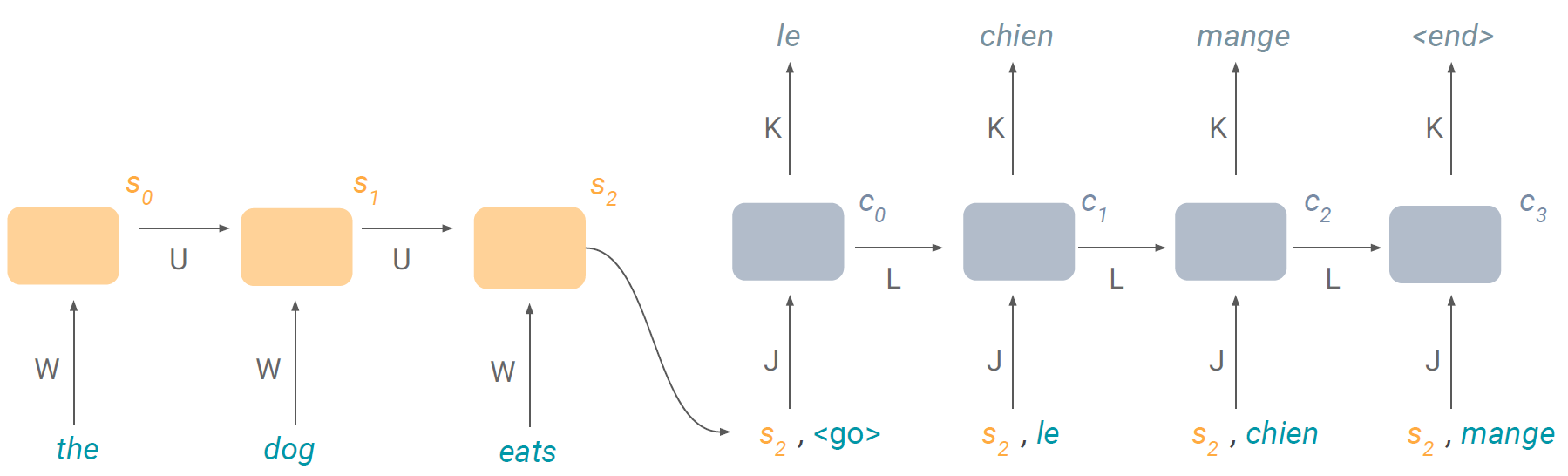
번역 문제는 조금 복잡하다. 보통 번역의 경우 두 가지의 RNN을 쓴다. 하나(왼쪽)은 인코더, 다른 하나는 디코더로 사용한다. 위 그림에서 인코더는 s_2를 디코더의 input으로 전달하고 있다. 즉 "the dog eats"라는 sequence를 하나의 vector로 인코딩(summarize)하여 디코더로 전달하는 것이다. 반대로 디코더의 입장에서는 input sequence의 정보로 받은 것이 fixed length vector s_2밖에 없다. 만약 sequence의 길이가 매우 길다면, 인코딩된 하나의 vector내에 sequence의 모든 정보를 제대로 담을 수 있을까? 이런 문제에 대안으로 나온 것이 'attention' 방법이다.

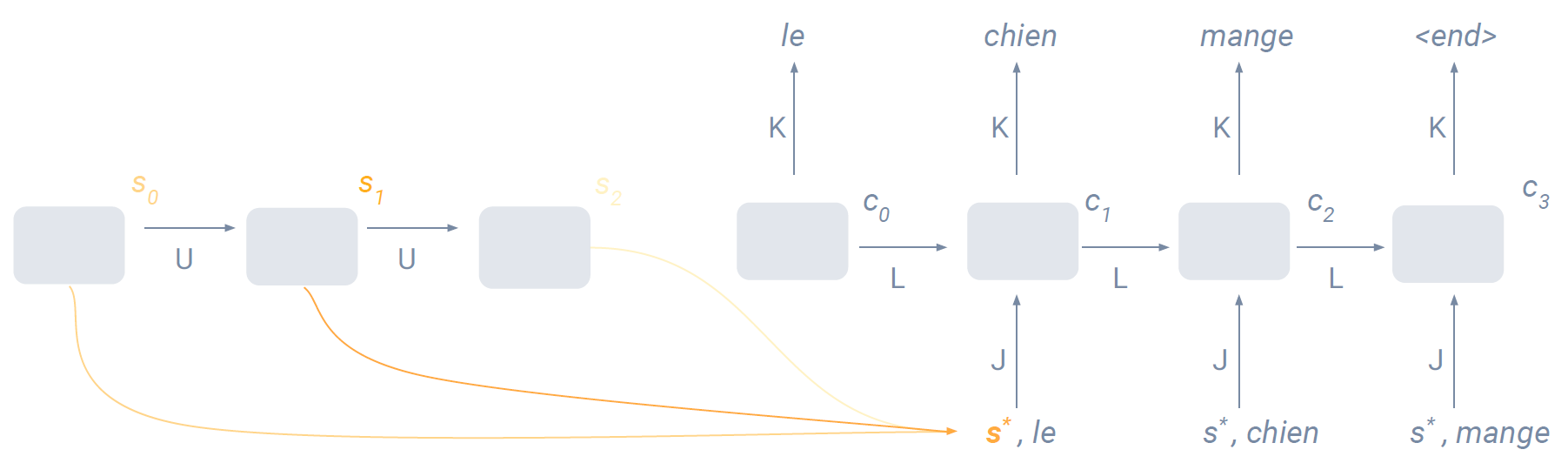
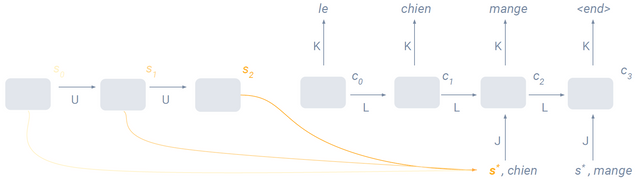
Attention 방법은 인코더가 최종 cell state를 전달하는 것이 아니라 각각의 cell state를 weighted sum하여 디코더 각 cell에 전달한다. 이때 디코더의 time step에 따라 weighted sum되는 값이 달라진다. 예를 들면 t=0일때는 인코더의 t=0일 때 cell state의 weight를 가장 높게 줄 수있고 t=1일 때는 인코더의 t=3일 때의 ... 뭐 이런식으로..
아무튼 RNN은 활용도가 굉장히 높은 모델이다. 그 근거는 수업 자료를 복붙하며 이번 포스트를 마무리...
● extending our models to timeseries + waveforms
● complex language models to generate long text or books
● language models to generate code
● controlling cars + robots
● predicting stock market trends
● summarizing books + articles
● handwriting generation
● multilingual translation models
모든 이미지 자료는 MIT 6.S191 수업 자료에서 가져왔습니다. http://introtodeeplearning.com/
Hey @yskoh, want free resteems? All ya gotta do is follow me...
Congratulations @yskoh! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Do not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness to get one more award and increased upvotes!
Congratulations @yskoh! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Do not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness to get one more award and increased upvotes!