[논문 소개] Women also Snowboard: Overcoming Bias in Captioning Model
- 논문 정보
- 논문 제목: Women also Snowboard: Overcoming Bias in Captioning Model
- 논문 링킁: https://arxiv.org/abs/1803.09797
오늘 소개드릴 논문은 "Women also Snowboard: Overcoming Bias in Captioning Model"입니다. Trevor Darrell 아저씨가 저자로 있는 거로 알 수 있듯이 이 분야 논문 공장인 UC Berkeley의 논문입니다. 제목을 늘 그렇듯 잘 지은거 같습니다. "Women also Snowboard" 이 한문장으로 상황을 대강 알려줍니다. 주로 snowboard같은 운동이나, 혹은 더 위험한 운동같은 종목을 남자들이 더 즐기고 그렇기 때문에 데이터베이스에도 주로 남자들이 나오기 때문에 captioning model을 이용하여 caption을 생성해 보면 주로 남자를 지칭하는 단어로 생성합니다. 이 논문에서 나온 captioning뿐 아니라, 많은 classification 문제도 데이터베이스에서 많이 나온 일종의 편견을 고스란히 model에 가지고 있는 경우가 많습니다. 물론 우리 사회 자체가 그런 편견을 가지고 있죠. 그래서.. 이 논문은 제목에 나와 있듯이 "Overcoming Bias in Captioning Model"이 목적입니다. 그러나 그 많은 편견 중, 제목 첫 문장에 나오듯, 남여에 관한 문제를 주로 다루고 있습니다. (물론 다른 곳으로 확장할 수도 있는 방법이긴 합니다... 그런 데이터베이스가 준비될까 싶긴 하지만.. -_-)

이런 남여에 관한 Bias에 대한 문제를 정의하기 위해서 이 논문에서는 위와 같은 Right for the Right Reasons 이라고 표현하면서 Captioning model이 gender 정보를 판단할 때 어디를 보고 하는지를 확인합니다. 확인하는 방법은 GradCAM과 Saliency map을 활용합니다. 위 그림에서 보실 수 있듯이 잘못 판단할 때, 그러니깐 남자인지 여자인지를 말해야 하는 단어를 생성할 때 사람을 보지 않고 주위를 보고 판단하고 있는 것을 볼 수 있습니다.
이 문제를 해결하기 위해서 이 논문에서는 두개의 새로운 (다시 보면 새롭진 않지만..) loss를 제안합니다.
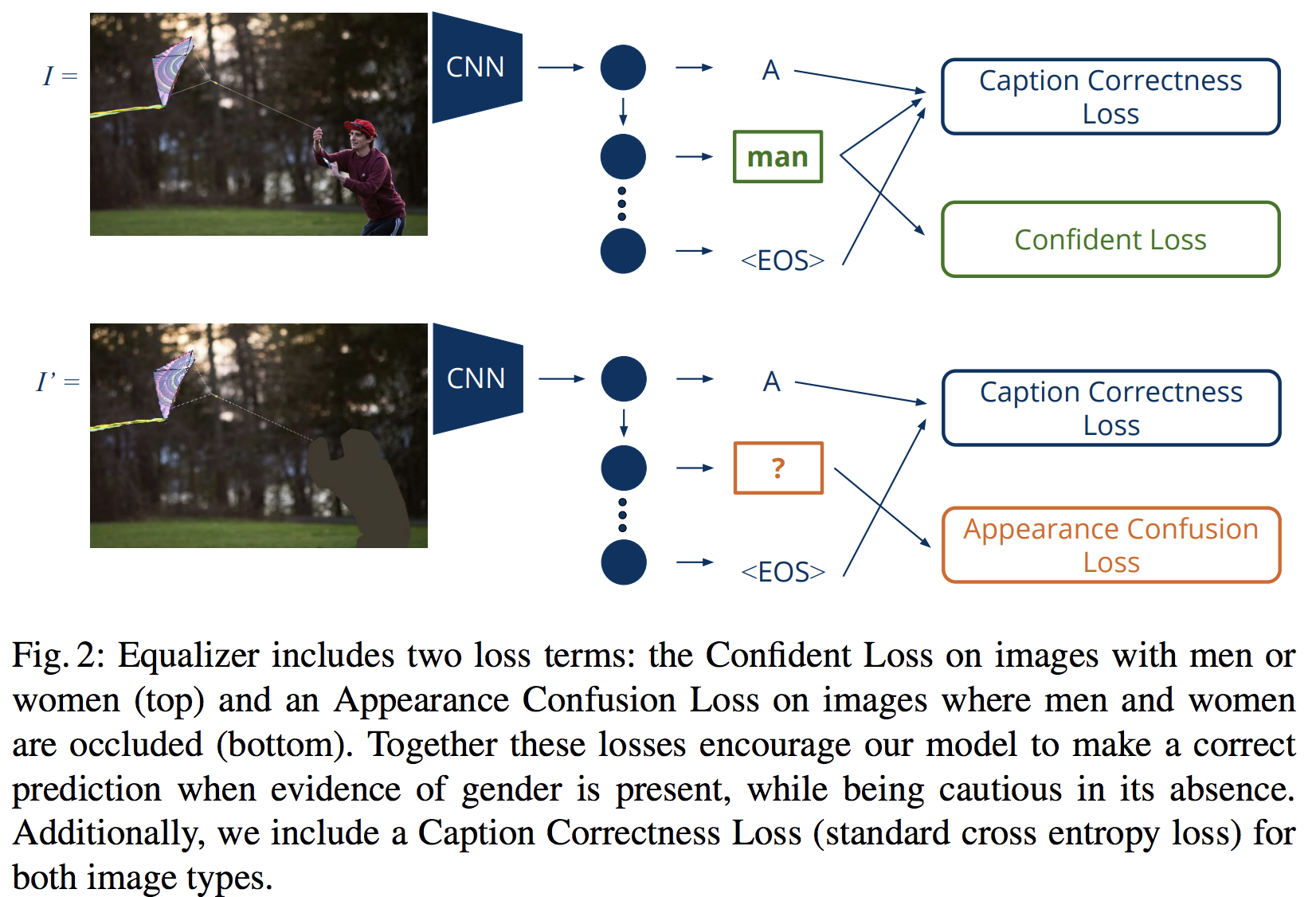
위 논문의 그림을 보시면 아주 간략히 (읽지 않으면 이해 안 갈만큼만) 설명이 되어 있는데, 그 loss는 Confident Loss와 Appearance Confusion Loss입니다.
먼저 Appearance Confusion Loss은 남자인지 여자인지 구별할 정보가 없으면 남여를 구분을 잘 못 하게 하는 loss입니다. 그러니깐, 주위환경이나 상황을 보고 남여를 한쪽으로 찍지 못 하게 하는 겁니다. 찍게 한다면 주로 그 상황에 많이 나오는 성별로 찍는게 학습 정확도에서 높을거니 그러지 말라는 겁니다. 그럼, 이제 궁금한게 남여를 구분할 수 있는 정보라는 것에 대한 의문인데 위 사진을 보시면 사람 부분을 지워진 사진을 제공(정확히는 마스크 정보)하고 그 사진에 대해서 남여를 잘 못 맞추도록 하는겁니다.

위는 그 Appearance Confusion Loss을 위한 confusion function에 대한 수식인데, I'는 위의 그림처럼 남여를 구분할 수 있는 영역인 사람 영역이 지워진 그림입니다. 그래서 결과적으로 아래와 같이 됩니다.
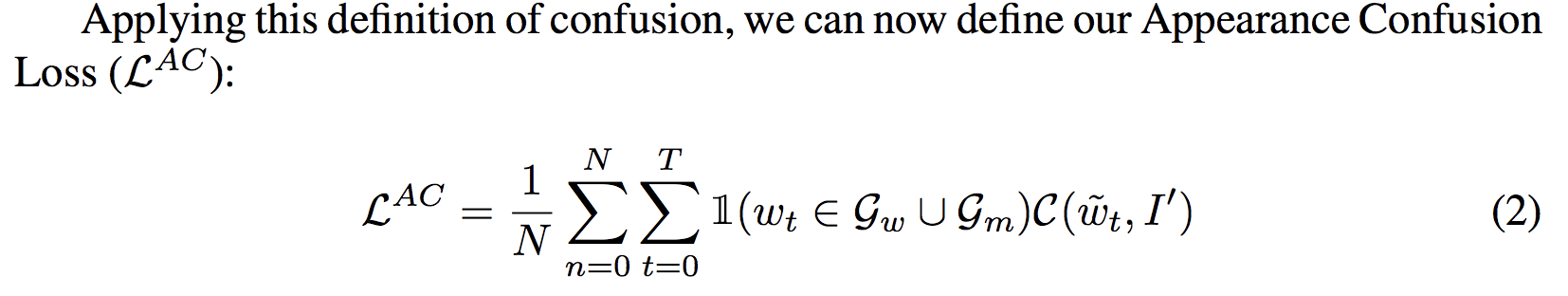
위와 같이 되면, 사람 영역이 없으면 헷갈리게 하라는거죠.
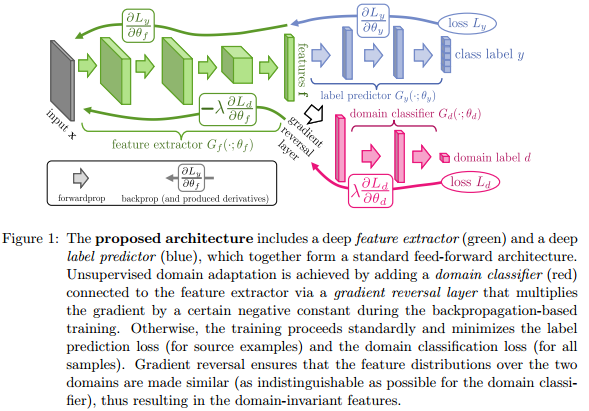
이 이러한 방식의 loss는 어찌 생각해보면 domain adaptation에 사용이 되었던 방식과 유사합니다. 좀 오래 전 논문이긴 하지만, Domain-Adversarial Training of Neural Networks (http://arxiv.org/pdf/1505.07818v4.pdf) 이란 논문에서 아래와 같이 합니다. classification에 대해서 그러니깐 class label은 맞추도록 학습하고, domain 정보는 못 맞추도록 학습니다. 그러니깐 맞춰야 할 상황에서 맞춰야 할 문제는 맞추도록 그리고 맞추지 못해야 할 문제는 못 맞추도록 학습하는게 .. -_- 다른 분은 아니라도 전 비슷하게 생각되었습니다.
이제 다시 논문으로 돌아와서, Confident Loss는 남/여를 판단할 정보가 있으면 확실히 판단하도록 하는 loss입니다.

위 수식에서 보실 수 있듯이 판단을 하게 하면 애매하게 찍지 않고 좀 확실히 판단하도록 강요하는거 같습니다.
그래서 결과적으로 loss는 일반적인 cross entropy loss와 함께 위에서 소개한 두 loss를 한마디로 적절히 잘 섞어서 사용합니다.
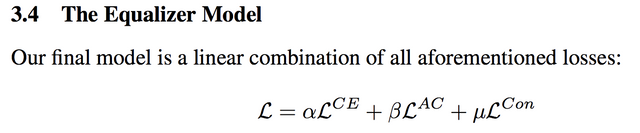
논문의 아이디어는 끝입니다. -_- 정리하면 사람 영역을 가린 영상을 보고 주위 환경을 통해 남/여를 찍지 못 하게 하고, 그리고 정보가 있을 때는 확실히 하도록 하고.. 그래서 잘 되게 잘 학습하자.. 끗
전 이 논문의 아이디어보다는 결과가 재밋었는데요..
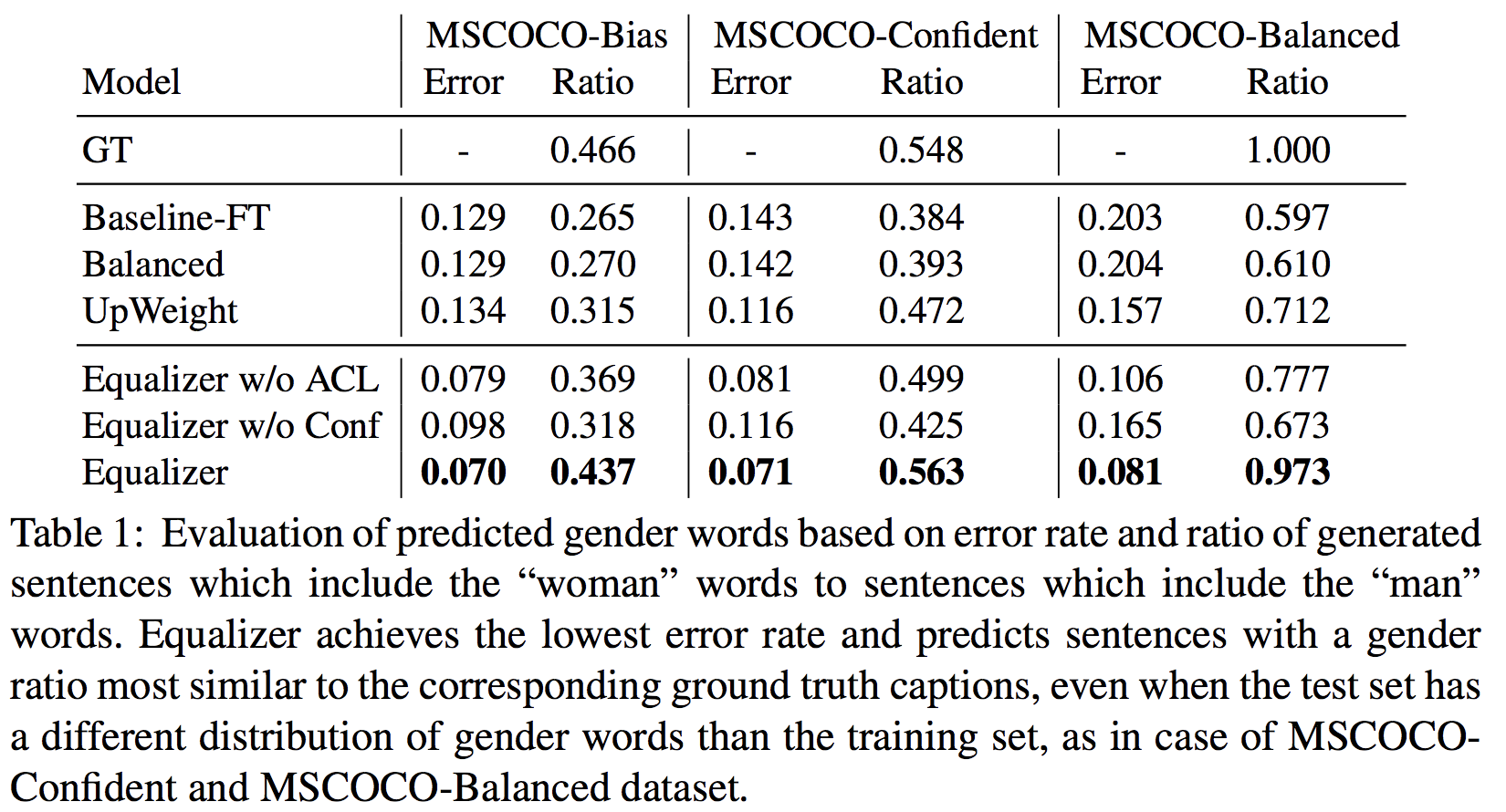
남/여를 구분하는 영역에서 정확도가 올랐고, 남여 단어 생성 비율이 비슷해졌습니다. -_- 오.. 워킹하네요.
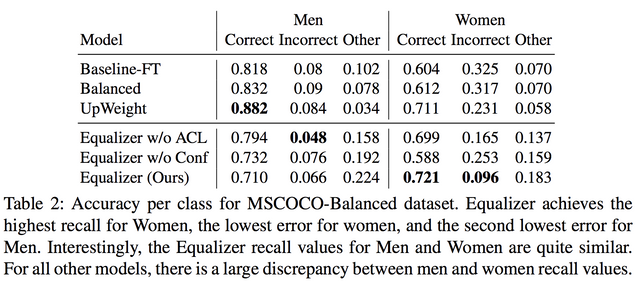
그렇다고 전체적으로 늘 최강의 성능을 보이는건 아닌데, UpWeight(남여 단어에 대해 좀 더 웨이팅을 높게 주는 방식)이 더 좋을 때도 있지만 확실히 여자에 대해서는 성능이 좋습니다. 이 점이 이 논문의 기술이 좋았다고 평가하기는 좀 그런게, 편견도 일종의 정보라고 볼 수 있다는 생각이 들어서입니다. 물론 그런 편견을 배제하니 상대적으로 손해를 보던 여자에 대한 정확도가 보상이 되었지만, 아무래도 정보를 독립적으로 보게 하는 면이 없지 않나 싶기도 하고요.

아무래도 ACL을 추가한게 남/여를 판단할 때 좀 더 사람을 보게 하는거 같습니다.
이 논문의 아이디어나 방법론이 좋았다기 보다는 이 논문이 생각하는 문제가 좋았고, 그것을 어떻게든 분석해서 보여주는거 같아 좋았습니다. 이 논문은 읽으면서 다른 기술적 사실보다는 오히려 신문 사회면이 더 생각났습니다. 뭐 사회학 하시는 분들은 이미 이런 류의 고민들을 많이 분석하셨겠지만, 실제로 데이터에서, data driven 방식이 뜨다보니 역시 AI라고 불리우는 여러 영역에서도 남/여 좀 더 넓게 말해서는 빈도로 본 주류와 비주류에 대한 문제 의식이 나타나기도 하는 거 같다는.. 그런 생각이..
물론 이런 loss가 새롭거나 그런건 아닌거 같습니다. 위에 domain adaptation에 대한 논문도 소개했는데, Focal Loss for Dense Object Detection (https://arxiv.org/abs/1708.02002)도 비슷하게 (비슷한가?) 데이터베이스 내에서 적은 수의 class나 event에 집중할 수 있도록 해 주기도 합니다.
뭐.. 그냥.. 오늘도 제가 읽을 수 있는 어려운 수학 없는 제일 쉬운 논문 정리.. -_- ..