[논문 소개] What do Deep Networks Like to See?
- 논문 정보
- 제목: What do Deep Networks Like to See?
- 링크: https://arxiv.org/abs/1803.08337
- 학회 정보: CVPR 2018
오늘 소개시켜드릴 논문은 "What do Deep Networks Like to See?"이란 논문입니다. German Research Center for Artificial Intelligence (DFKI)에서 나온 논문으로 CVPR에 accept된 논문입니다. 역시 유럽에서 나온 논문이라 그런지 우리 나라처럼 제목이 딱딱하지 않네요. 딥러닝 네트웍은 무엇을 보고 싶어하는지에 대해서 쓰고 있습니다. 쉽게 말하면 딥러닝은 무엇을 판단할 때 (이 논문에서는 classification 모델에 대해서 정리했으니 판단이라고 하겠습니다.) 무엇을 보려고 하는지 좀 봐보자 입니다.
무엇을 보려고 한다는 질문에 대해서 지금까지 많은 논문은 어딜에 대해서 답해 왔습니다. 많이들 attention이라고 부르시기도 했는데, 판단을 할 때 어딜 보고 하냐는 거지요. 그것을 알아보는 방법론은 크게는 두가지로 나누어졌습니다. Perturbation based visualizations 방법은 input에서 일부 영역을 흔들어 주면서 판단 결과에 얼마나 영향을 미치는지 보는 방식이고, Backpropagation based visualizations 방법은 output으로 나온 결과를 기준으로 역으로 어디에 많은 영향을 받았는지 보여주는 방식입니다. 최근에 나온 gradCAM (https://arxiv.org/abs/1610.02391) 과 같은 방식이 여기에 속할거 같습니다. 이 두 방법론에 대해서는 Visualizing Deep Learning Networks (http://blog.qure.ai/notes/visualizing_deep_learning) 과 같은 블로그를 보시면 더 잘 보실 수 있을거 같습니다. 또한 최근에는 "Tell Me Where to Look: Guided Attention Inference Network" (CVPR 2018, https://arxiv.org/abs/1802.10171), "Object Region Mining with Adversarial Erasing: A Simple Classification to Semantic Segmentation Approach" (http://arxiv.org/abs/1703.08448v2, CVPR 2017)와 같이 그 두 개념을 혼합해서 좋은 결과를 낸 경우도 많이 있습니다.
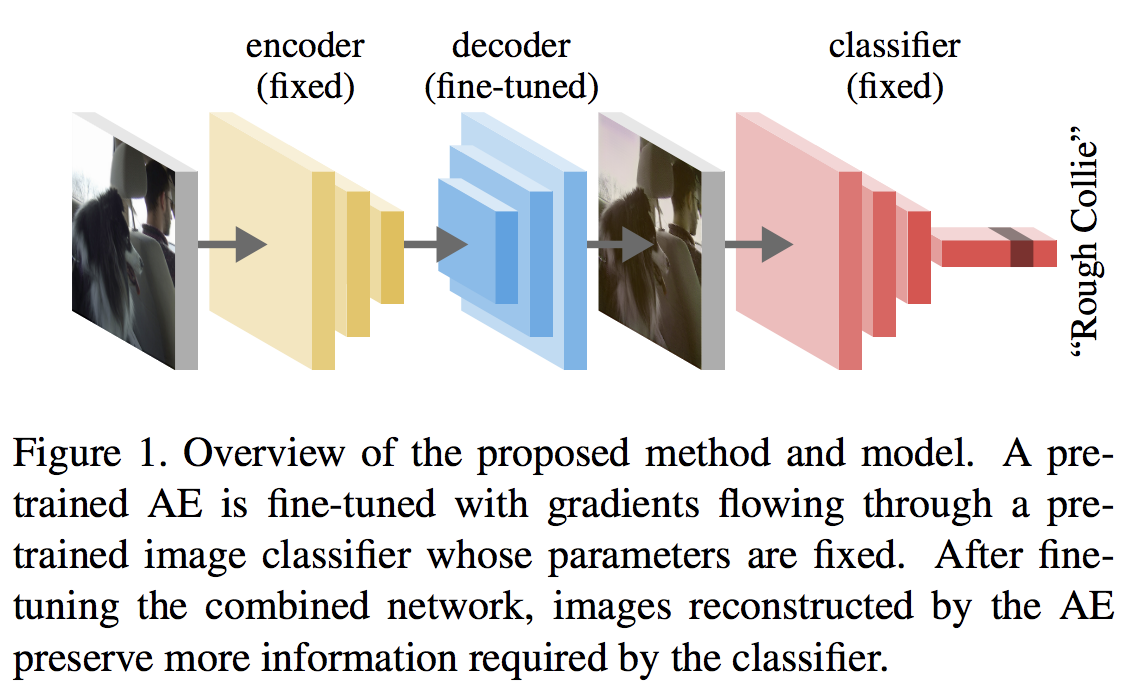
이제 다시 오늘 소개하는 논문으로 돌아와서, 이 논문은 어디를 보는지 보다는 어떤 그림을 보는지에 더 가깝습니다. 물론 조금 조작하면 어디를 보는지도 볼 수 있게 할 수 있죠. 논문의 아이디어는 아래 사진 한장에 정리될 수 있습니다.
 ![]
![]
위 그림과 같이 이 논문의 구조는 입력 영상을 한번 autoencoder를 거쳐서 다시 reconstruct된 영상이 정해진 classifier에 들어가는 구조입니다. 일단 재구성된 영상이 classifier에 들어가는 구조를 확인하실 수 있죠. 이제 다시 보면, encoder와 classifier는 fixed되어 있고, decoder만 fine-tuned된다고 적혀 있습니다. encoder가 fix되어 있는 이유는 일단 autoencoder 자체는 영상을 잘 재구성하는 autoencoder를 사용하기 때문이고, classifier가 fix된 이유는 classifier는 우리가 이미 잘 학습해 놓은 classifier를 사용하는 거입니다. 그럼 그렇게 고정해 놓고, fine-tuning을 하면 이 논문의 주장은 classifier에서 좀 더 활용하는 정보만 decode될거란 거죠. 한마디로 그렇게 fine-tune된 decoder를 활용하면 classifier에서 더 보려고 하는 정보가 담긴 영상이 재구성될 거란 말입니다.
이런 가정 아래 논문의 저자들은 여러 실험을 합니다. 기본적으로 선택의 기준이 뭔지는 모르겠지만, 5개의 구조 AlexNet, VGG-16 with batch normalization, Inception v3, ResNet-50, LeNet-5를 사용하여 테스트해 나갑니다. 아 그리고 AE 구조는 segNet을 선택했고요. 뭐.. 다른 구조에서도 비슷한 결과를 보일거 같지만, 가장 대표적인 결과를 보기 위해 이렇게 간듯 합니다.
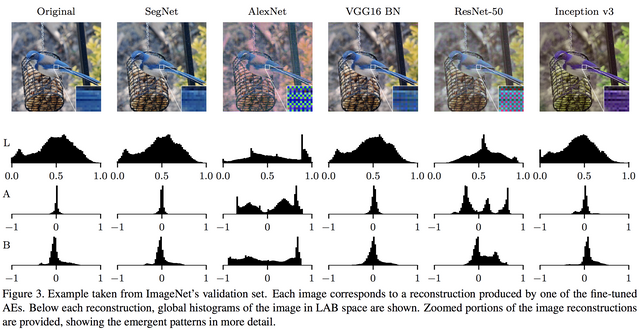
저는 영상쟁이라서 그런지 몰라도 이 결과가 가장 눈에 들어왔는데, 네트웍 구조에 따라 reconstruction된 영상의 특징이 많이 다릅니다. 솔직히 일부 페턴이 뭉개지거나 block artifact나 checkerboard 효과는 convolution 연산이 주고, upsampling 과정에서 세밀하지 못 하면 당연히 예상했던 바인데, 색 구조로 봤을 때 저렇게 다른 분포를 가질거라고는 예상을 못 했습니다. -_- .. 색을 판단에 사용하긴 한거니? ...
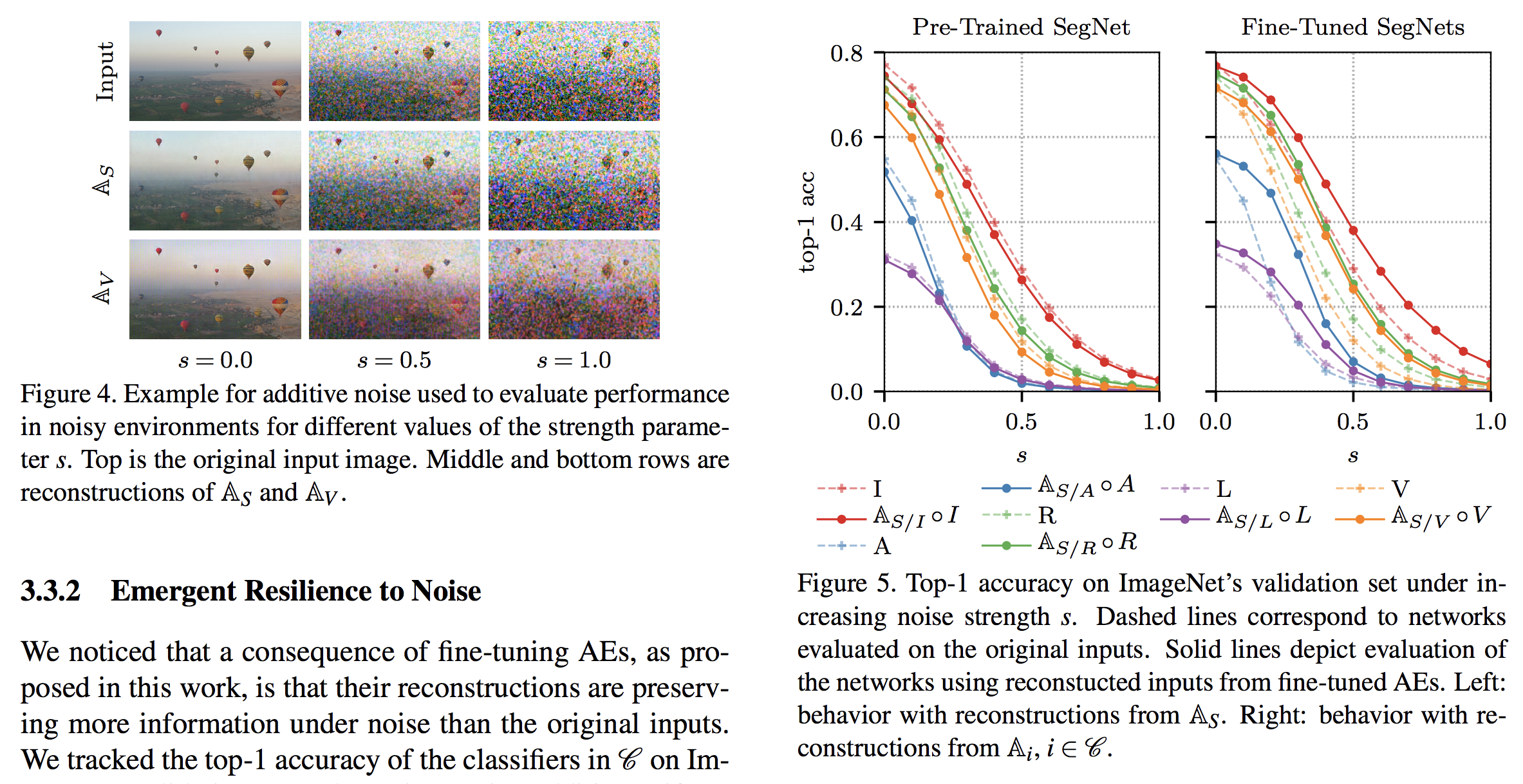
그리고 이렇게 AE를 거쳐 재구성된 영상을 사용할 경우, 그게 fine-tuned된 AE라면 노이즈에 강인하다고 밝히고 있습니다. 이 부분은 어찌 보면 당연한건데, 그런 노이즈를 보지 않고 판단하기에 그런 노이즈가 재구성 영상에서 많이 줄어들고 이 과정에서 AE가 일종의 denoising filter역할을 하기 때문인거 같습니다.
그리고 독일이기에 그런지 아니면 딥러닝 이슈때문에 갑자기 나타난 그룹이 아니라서 여러 다양한 실험으로 분석을 이어갑니다. 성능 옛다 먹어라~ 하는 논문보다 그래서인지 훨씬 재밋게 읽었고요. 다른 분석으로 확장 가능성이 큰 논문이라고 생각합니다. 그리고 리뷰 초반에 언급한데로 어디를 보고 하는지에 대한 질문도 중요하고, 어떤 영상에 대한 질문도 중요하다고 생각합니다. 그런 점에서 정확도를 많이 높일 수 있거나 팬시한 방법은 아니지만 분석을 위해 나름 의미 있는 연구라고 생각합니다.
리뷰 끗... CVPR은 언제나 기대되는 학회...