[백호잉 딥러닝논문리뷰] Deep Reinforcement Learning with Dobule Q-learning
인사글
안녕하세요. @backhoing입니다.
앞서 알려드렸듯이 제 글의 주요 주제는 논문 리뷰가 될 것입니다.
논문 리뷰라고 해서 어렵게 생각하실 수도 있지만 논문을 전문적으로 평가하는 것은 아닙니다.
졸업논문을 준비하면서 읽은 논문의 내용을 정리하고 개념을 소개해서
해당 논문에 대한 의견과 아이디어를 공유하는 것이 주요 목적입니다.
추후 졸업논문에 필요한 논문이고 조금 더 공부하고 싶은 논문이라고 생각 될 때에는 수식에 대한 설명도 추가할 예정입니다.
모든 내용을 번역해서 적기보다는 최대한 저만의 언어로 변경하고 요약해서 정리할 것입니다.
이해를 도울 수 있는 배경지식들은 전부 설명하기 보다는 잘 정리된 곳의 링크를 추가하도록 하겠습니다.
저도 모든 내용을 이해하고 글을 쓰면 좋겠지만 공부를 하면서 글을 작성하는 것이기 때문에 많이 부족한 부분이 있을 것입니다. 그래도 하루하루 발전하는 모습을 보여드릴 수 있도록 노력하겠습니다.
글을 읽어보시고 추천하고 싶은 논문이나 좋은 아이디어는 언제나 환영입니다.
학기가 시작되고 나면 실험조교를 진행할 텐데 아마 아두이노에 대해서 다룰 듯합니다.
수업을 진행하면서 학생들이 진행 한 실험 과정과 수업내용에 대해서도 간단히 글을 쓸 예정입니다.
제가 쓴 글이 많은 사람에게 관심 있는 주제는 아니지만 한 분이라도 도움을 받으실 수 있으면 좋겠습니다.
제가 소개해드릴 논문은 2015년에 나온 Deep Reinforcement Learning with Double Q-learning (Hado van Hasselt and Arthur Guez and David Silver)입니다.
최근 강화 학습(reinforcement learning)에 관련된 논문을 읽어보기로 마음먹고 처음으로 선택한 논문입니다.
읽다보니 DQN(Deep Q-Network)을 공부하기 시작한 저에게는 어려운 주제였습니다.
그래도 논문의 목적과 사용된 기술들의 개념 그리고 결과에 대해서 간단히 정리해보려고 합니다.
DQN에 대해서 알고 계시고 성능 개선 방법을 찾고 계신 분에게 추천드릴 수 있는 논문입니다.
Abstract
- Q-learning algorithm 문제점 소개 : 특정 조건에서 action value를 과평가(overstimate)한다.
논문의 전체적인 내용을 요약한 abstract 부분 처음 시작의 내용입니다. 자신의 기술이 현재의 기술(이 방법도 결국 같은 곳에서 제안한 기술입니다.)보다 좋다는 것을 증명해야 하는 것이 논문의 주요 내용이기 때문에 현재의 기술의 문제점을 언급하며 자신의 기술이 나온 배경을 설명하는 방식을 사용하여 장점을 부각시키고 있습니다. 이러한 방식이 조금 치사해 보이지만 장점을 부각시키는 효과는 탁월하다고 생각합니다.
위의 문장은'이 문장 이해할 수 있겠어? 아니면 돌아가'라고 말하는 듯했습니다. action value가 무엇인지, action value를 과평가하면 어떤 문제가 발생하는지등...(바로 접고 돌아갔어야 했는데ㅠㅠ)
문장을 이해하기 위해 개념을 간단히 소개하면 Q-learning이란 강화 학습 중에서 가장 대표되는 알고리즘입니다. 특정한 환경(environment state, 바둑판의 배열의 상태나 게임의 현재 화면 등을 말합니다.)일 때 에이전트(Agent, 행동의 주체)가 자신이 취할 수 있는 행동(Action) 중에서 가장 이득이 되는 방향으로 학습하는 방법을 말합니다. 이때 해당 action을 했을 때 받을 수 있는 보상의 값을 action value라고 합니다.
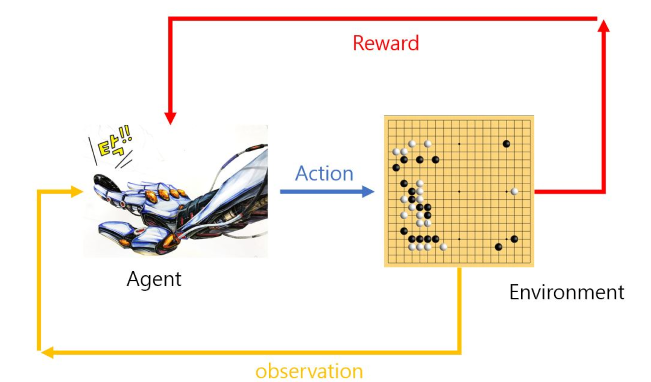
(그림을 혼자 만들어보려고 시도해보고 있습니다만 어렵네요.)
-김성훈 교수님의 모두를 위한 RL강좌를 보시면 강화학습에대한 개념을 더 쉽게 이해하실 수 있을 것입니다.
특정 조건이란 Q-Value(action value)에 noise가 많은 상태에서 가장 큰 action value를 취할 때를 말하는 것으로 생각됩니다. 예로 해당 행동에 대해서 가장 큰 이득이 되는 값을 가질 때 주사위의 기대값은 3.5입니다. 그러나 100번을 던진 후 가장 큰 값을 취한다고 할 때는 3.5보다 큰 값을 가질 가능성이 큽니다. 모든 값에 대해서 동일하게 과평가된다면 문제가 없지만 Q-value에서는 다를 수 있다는 점이 문제가 됩니다.
위의 내용을 정리해보면 보상받을 값에 따라서 다음 행동이 결정이 되는데 잘못된 행동에 대한 action value가 과평가되면 잘못된 방향으로 학습이 될 수 있음을 알 수 있습니다.
- 해결 방법 : Double Q-learning을 적용한다.
DQN이란 이름은 Q 함수를 'Deep Neural Network로 구성했기 때문에 붙여진 이름입니다.
본 논문에서 제안하는 방법은 Double Q-learning을 DQN에 적용하는 것입니다. (Deep Double QN)
Abstract에는 자세한 설명이 없지만 설명을 조금 붙이면 다른 sample로 학습된 서로 다른 fuctions approximator를 사용하여 하나는 가장 좋은 행동을 선택하는 곳에 사용하고 다른 하나는 선택된 행동에 대한 값을 계산하는 곳에 사용한다. 두 fuctions approximators가 다른 sample로 보기 때문에 동일한 행동을 과평가 하지 않는다는 설명입니다.
(해당 설명을 이해하기 위해서는 조금 더 학습이 필요할 듯 합니다.)
- 결과 : 과평가를 줄이고 몇 개의 게임에서는 더 좋은 성과를 보였다.
결과에서는 처음 말했던 문제를 해결하고 실전에 적용하여 좋은 성능을 보임을 나타내었습니다.
Abstract 내용을 읽는 것도 아직 힘이 듭니다. 논문을 많이 읽으신 분들은 abstract를 5분 안에 읽는다고 하시던데 아직 저는 멀었네요. 본문의 내용은 논문을 더 자세히 읽고 다음 글에 정리하도록 하겠습니다.
스스로 홍보하는 프로젝트에서 나왔습니다.
오늘도 좋은글 잘 읽었습니다.
오늘도 여러분들의 꾸준한 포스팅을 응원합니다.
다음 글을 빨리 준비해야하는데 어렵네요 ㅠㅠ
잘 준비해서 또 홍보하겠습니다.
본문내용 기대되네요 ㅎㅎ
넵~ 기대해주세요.
정확히 이야기하면 DDQN (Deep Double QN)이군요. 애초에 Q-Learning에 Deep 이 붙은 이유는 Q-Learning의 function을 deep neural network로 모사하자는 철학으로부터 시작하고, 여기에 Double Q-learning을 붙인 개념입니다. Q Learning의 장점은, 어떤 내재적 모델의 구조를 가정하지 않도고 강화학습을 할 수있다는 것입니다.
추후에 DDDQN (Dueling Double Deep Q-Network) 도 같이 살펴보시면 좋겠습니다.
Sarsa 혹은 Sarsa(lambda), TD(0) 등과도 한번 대비해서 살펴보세요. 응원드립니다. :)
피드백 감사드립니다~! 말씀해주신 내용 참고해서 내용을 수정했습니다.
링크해주신 github도 같이 살펴보도록 할게요~
와...정리해놓으신거 보고 사실 이해를 하나도 못했다는...ㅠ,ㅠ
얼마전에 보내주신 스팀달러 잘 받았습니다~
아이들에게 도움을 주셔서 진심으로 감사합니다^^
넵~! 좋은일 해주셔서 감사합니다~!
팔로우하고 갑니다 맞팔해주세요^^
넵~ 저도 팔로우 갑니다~!
Congratulations @backhoing! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOP