What is data mining?
Definition
Data mining, also popularly referred to as knowledge discovery from data (KDD), is the automated or convenient extraction of patterns representing knowledge implicitly stored or captured in large databases, data warehouses, the Web, other massive information repositories, or data streams.

Introduction
Analyzing large amounts of data is a necessity.
Every enterprise benefits from collecting and analyzing its data:
- Hospitals can spot trends and anomalies in their patient records
- Search engines can do better ranking and ad placement
- Environmental and public health agencies can spot patterns and abnormalities in their data
The problem then becomes how to analyze the data.
This is exactly the focus of this blog series. I will provide coverage of all the related methods.
The exposition is extremely accessible to beginners and advanced readers alike.
The blog will give the fundamental material first and the more advanced material in follow-up posts.
Goals
We are deluged by data—scientific data, medical data, demographic data, financial data and marketing data.
People have no time to look at this data. Human attention has become the precious resource.
So, we must find ways to automatically:
- Analyze the data
- Classify it
- Summarize it
- Discover and characterize trends in it
- And to automatically flag anomalies
This is one of the most active and exciting areas of the database research community.
Emerging of data mining
The computerization of our society has substantially enhanced our capabilities for both generating and collecting data from diverse sources.

A tremendous amount of data has flooded almost every aspect of our lives. This explosive growth in stored or transient data has generated an urgent need for new techniques and automated tools that can intelligently assist us in transforming the vast amounts of data into useful information and knowledge.
This has led to the generation of a promising and flourishing frontier in computer science called data mining, and its various applications.
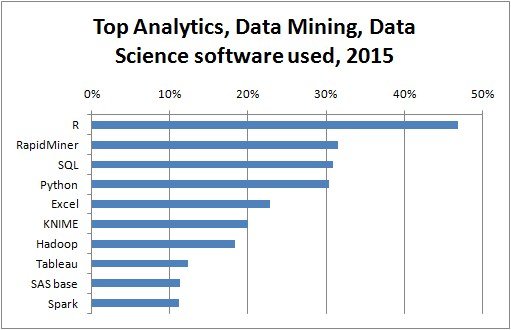
Data mining emerged during the late 1980s, made great strides during the 1990s, and continues to flourish into the new millennium.
Why data mining?
We live in a world where vast amounts of data are collected daily. Analyzing such data is an important need.

Next section looks at how data mining can meet this need by providing tools to discover knowledge from data. In section Data Mining as the Evolution of Information Technology, we observe how data mining can be viewed as a result of the natural evolution of information technology.
Moving toward the Information Age
“We are living in the information age” is a popular saying; however, we are actually living in the data age. Terabytes or petabytes of data pour into our computer networks, the World Wide Web (WWW), and various data storage devices every day from business, society, science and engineering, medicine, and almost every other aspect of daily life.
This explosive growth of available data volume is a result of the computerization of our society and the fast development of powerful data collection and storage tools.
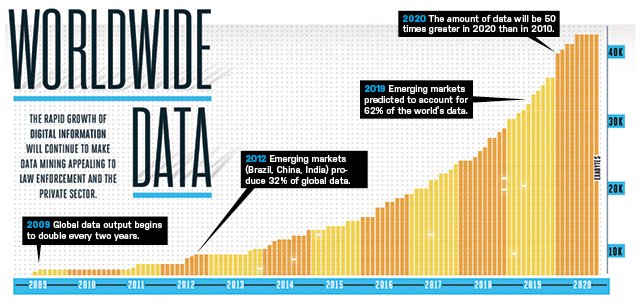
Businesses worldwide generate gigantic data sets, including sales transactions, stock trading records, product descriptions, sales promotions, company profiles and performance, and customer feedback.

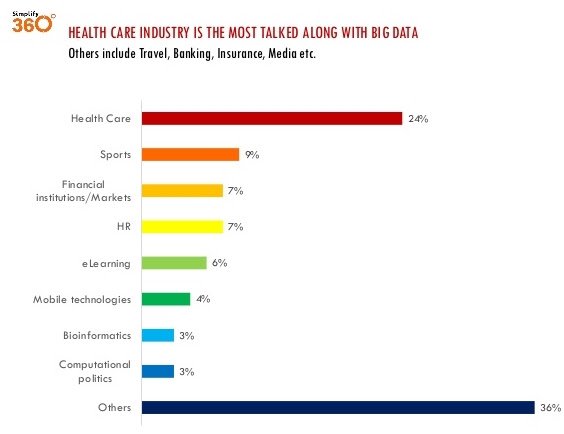
The list of sources that generate huge amounts of data is endless.
This explosively growing, widely available, and gigantic body of data makes our time truly the data age.
Powerful and versatile tools are badly needed to automatically uncover valuable information from the tremendous amounts of data and to transform such data into organized knowledge.
This necessity has led to the birth of data mining.
The field is young, dynamic, and promising. Data mining has and will continue to make great strides in our journey from the data age toward the coming information age.
Example 1 - Data mining turns a large collection of data into knowledge
A search engine (e.g., Google) receives hundreds of millions of queries every day. Each query can be viewed as a transaction where the user describes her or his information need.
(
What novel and useful knowledge can a search engine learn from such a huge collection of queries collected from users over time?
Interestingly, some patterns found in user search queries can disclose invaluable knowledge that cannot be obtained by reading individual data items alone.
For example, Google’s Flu Trends uses specific search terms as indicators of flu activity. It found a close relationship between the number of people who search for flu-related information and the number of people who actually have flu symptoms.
A pattern emerges when all of the search queries related to flu are aggregated. Using aggregated Google search data, Flu Trends can estimate flu activity up to two weeks faster than traditional systems can.
This example shows how data mining can turn a large collection of data into knowledge that can help meet a current global challenge.
History
The research and development in database systems through the years:
- 1960s - database and information technology has evolved systematically from primitive file processing systems to sophisticated and powerful database systems
- 1970s - progress from early hierarchical and network database systems to relational database systems (where data are stored in relational table structures), data modeling tools, and indexing and accessing methods. Efficient methods for online transaction processing (OLTP).
- 1980s - systems incorporate new and powerful data models such as extended-relational, object-oriented, object-relational, and deductive models.
- late 1980s onward - the steady and dazzling progress of computer hardware technology in the past three decades led to large supplies of powerful and affordable computers, data collection equipment, and storage media. Data can now be stored in many different kinds of databases and information repositories
- 1990s - the World Wide Web and web-based databases (e.g., XML databases) began to appear. Internet-based global information bases, such as the WWW and various kinds of interconnected, heterogeneous databases, have emerged and play a vital role in the information industry.
The fast-growing, tremendous amount of data, collected and stored in large and numerous
data repositories, has far exceeded our human ability for comprehension without powerful
Tools.
As a result, data collected in large data repositories become “data tombs”—data archives that are seldom visited. Consequently, important decisions are often made based not on the information-rich data stored in data repositories but rather on a decision maker’s intuition, simply because the decision maker does not have the tools to extract the valuable knowledge embedded in the vast amounts of data.
Efforts have been made to develop expert system and knowledge-based technologies, which typically rely on users or domain experts to manually input knowledge into knowledge bases.
Unfortunately, however, the manual knowledge input procedure is prone to biases and errors and is extremely costly and time consuming. The widening gap between data and information calls for the systematic development of data mining tools that can turn data tombs into “golden nuggets” of knowledge.
What is data mining?
Many people treat data mining as a synonym for another popularly used term, knowledge discovery from data, or KDD, while others view data mining as merely an essential step in the process of knowledge discovery.
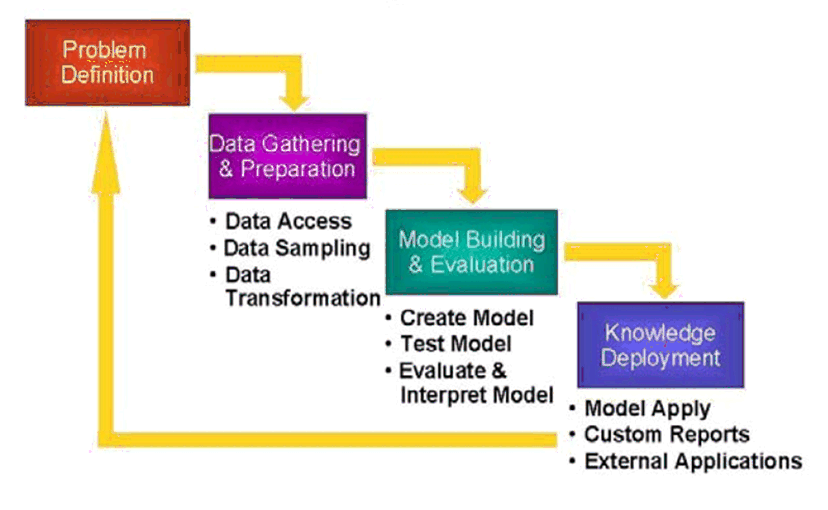
The knowledge discovery process is shown as an iterative sequence of the following steps:
- Data cleaning (to remove noise and inconsistent data)
- Data integration (where multiple data sources may be combined)
- Data selection (where data relevant to the analysis task are retrieved from the database)
- Data transformation (where data are transformed and consolidated into forms appropriate for mining by performing summary or aggregation operations)
- Data mining (an essential process where intelligent methods are applied to extract data patterns)
- Pattern evaluation (to identify the truly interesting patterns representing knowledge
based on interestingness measures) - Knowledge presentation (where visualization and knowledge representation techniques
are used to present mined knowledge to users)
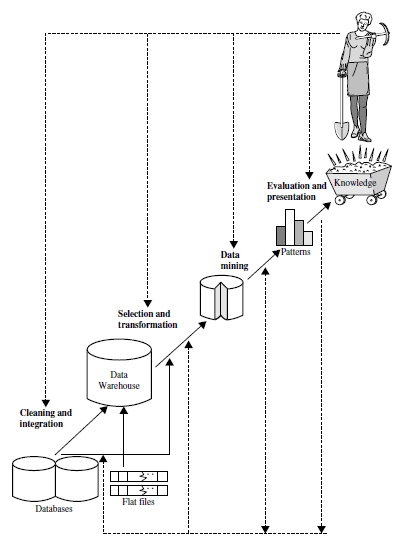
Steps 1 through 4 are different forms of data preprocessing, where data are prepared for mining. The data mining step may interact with the user or a knowledge base. The interesting patterns are presented to the user and may be stored as new knowledge in the knowledge base.
The preceding view shows data mining as one step in the knowledge discovery process,
albeit an essential one because it uncovers hidden patterns for evaluation.
However, in industry, in media, and in the research milieu, the term data mining is often used to refer to the entire knowledge discovery process (perhaps because the term is shorter than knowledge discovery from data).
Therefore, we adopt a broad view of data mining functionality: Data mining is the process of discovering interesting patterns and knowledge from large amounts of data. The data sources can include databases, data warehouses, the Web, other information repositories, or data that are streamed into the system dynamically.
What kind of data can be mined?
As a general technology, data mining can be applied to any kind of data as long as the data are meaningful for a target application.
The most basic forms of data for mining applications are:
- database data
- data warehouse data
- and transactional data
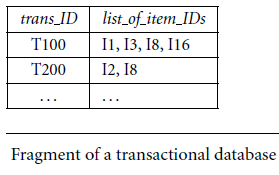
Fragment of a transactional database
The concepts and techniques presented in this blog will focus on such data.
Data mining can also be applied to other forms of data (e.g.,data streams, ordered/sequence data, graph or networked data, spatial data, text data, multimedia data, and the WWW).
Data mining will certainly continue to embrace new data types as they emerge.
Summary
Blog will explore the concepts and techniques of knowledge discovery and data mining.
As a multidisciplinary field, data mining draws on work from areas including statistics, machine learning, pattern recognition, database technology, information retrieval, network science, knowledge-based systems, artificial intelligence, high-performance computing, and data visualization.
I will focus on issues relating to the feasibility, usefulness, effectiveness, and scalability of techniques for the discovery of patterns hidden in large data sets.
I hope that this blog will encourage people with different backgrounds and experiences to exchange their views regarding data mining so as to contribute toward the further promotion and shaping of this exciting and dynamic field.
About the blog
This blog gives quick introductions to database and data mining concepts with particular emphasis on data analysis.
The field is evolving very rapidly, but this blog is a quick way to learn the basic ideas,
and to understand where the field is today.

An important motivation for writing this data mining blog was the need to build a welcoming community for teaching and a platform for helping upcoming generations. A challenging task, owing to the extensive multidisciplinary nature of this fast-developing field.
I hope that this blog post will spark your interest in the young
yet fast-evolving field of data mining.
REFERENCES:
Data Mining Concepts and Techniques, Third Edition, Jiawei Han, Micheline Kamber, Jian Pei
We are living in a simulation. It's either that or we are a colony of bacteria on Mark Zuckerberg's arse.
Am looking for stats on the hourly use of Steemit. So I am going to try and write a python program to data mine the info.
I will be trying to grab hourly post numbers and rewards. Reckon I can just grab it on payouts page.
Am using it as a project to further my learning of python
Keep up the great work @machinelearning
Upvoted
nice post @machinelerning
thanks information
vote done
Thank you.
This is equal parts scary and interesting. Mostly interesting. I hope you're going to dive into Steemit data over time and give us all some interesting insights.
Can you make this a regular thing? It was very interesting read.
Holly molly that was a big post. Learned a few new things from it as well so this definitely deserves my upvote!
Hello, please check out my idea on getting more posts rewarded:
https://steemit.com/steemit/@lorddominik007/my-thoughts-on-steemit-an-idea-to-help-great-posts-be-recognized
Great post! very well explained once again! I hope you will keep making posts one can learn from :)
What will be the next topic?
Keep up the great work @machinelearning
Upvoted