World decentralized AI on blockchain with cognitive mining and open markets for data and algorithms – Pandora Boxchain

Summary
The industry of artificial intelligence (machine learning, ML) and big data is at the very core of the 4th Industrial revolution. Today, there exist no decentralized or even centralized open markets for each of the components required for machine learning: big data, ML models and computing power. Our mission is to decentralize and disrupt the whole ML industry by creating open market inclusive for all key players, which will stimulate synergy and speed up development of artificial intelligence. In other words, Pandora aims to create world decentralized artificial intelligence the same way Bitcoin has created world decentralized payments and Ethereum – world decentralized computer.
According to Forbes, big data market was estimated at $122 billions in 2015 and it will grow to more than $187 billions till 2019. Pandora can speed up its growth. Pandora targets to capture most of the market with its disruptive new way to compute ML models, which could bring total Pandora Network capitalization to tens of billions and more in term of 5-8 years. Our core strategy to capture the market is to give its players the ability to do things that they cannot do today: sell their computing power to AI tasks, sell their ML models to a broad community, monetize AI research, monetize datasets on an open market with fair price, easily find and acquire datasets required for training and computing ML models for business and research tasks.
Our team has already self-funded the development of technological description and economic model for the Pandora Network and Proof of Cognitive Work algorithm, as well as proof of concept in code written in Python, Ethereum smart contracts and Javascript that covers complete process cycle. This code is available on GitHub.
We have completed closed funding round and token distribution for 5% of total supply for $500k over the course of July 2017. Raised funds will be used for launching the first testnet version, completion of technological yellow papers and preparation for a large open fundraising at the autumn-end of this year with target set in range of $25-45m.
TL;DR
Pandora aims to create world decentralized artificial intelligence the same way Bitcoin has created world decentralized payments and Ethereum – world decentralized computer.
- “Cognitive mining” using neural networks with proof of cognitive work consensus (section 3.3)
- Stimulate natural evolution of AI towards human+AI, reducing risks of AI-human conflicts (section 1.3)
- New consensus with validation and arbitration algorithms suited for significant extensibility of blockchain-based turing-complete computations (allowing performance of deep learning computing) – can be applied to Ethereum etc. (section 2.4)
- Fundraising scheme protecting all participators from dumps when the token enters main exchanges (section 5.1)
- Awarding AI researchers with 10% of mined tokens using special reward algorithm based on the researcher’s h-index (section 3.4)
- New usage for GPU farms after Ethereum migration on PoS: good ROI on CAPEX for miners
- Finished & working proof of concept on Ethereum smart contracts with TensorFlow & Keras integration (section 4)

1. Project Overview
1.1 Solution
The industry of artificial intelligence (machine learning, ML) and big data is at the very core of the 4th Industrial revolution. Today, there exist no decentralized or even centralized open markets for each of the components required for machine learning: big data, ML models and computing power. Big data are oligopolized by Facebook, Google, IBM, Microsoft, Amazon. Cloud computing for ML tasks is highly centralized by the subset of the same players; there are no working fog computing solutions available: users with notebooks, phones or even mining farms having GPUs suited for ML tasks are left without choice to sell their resource to AI-based computations. Creators of ML kernels and AI architectures have no place to sell their work. We bring them all together and create an open market for all of these segments on the base of decentralized blockchain-based system named “Pandora” ideally suited for Artificial Intelligence computing. This network will supercede existing PoW and PoS consensus models by introducing new Proof of Cognitive Work consensus (PoCW), rewarding owners of hardware used for AI tasks (see section 3.3), and in the future will reward AI developers using Research Work Reward Algorithm (see section 3.4).
Pandora aims to create world decentralized artificial intelligence the same way Bitcoin has created world decentralized payments and Ethereum – world decentralized computer.
Our mission is to decentralize the ML and data industry by creating open market inclusive for all key players, which will stimulate synergy and speed up development of artificial intelligence. This will also disrupt the existing ML industry by the following means:
- Killing corporations’ oligopoly of big data by adding alternative data set and ML models sources.
- Reducing costs of computing power and thus enabling SME business and non-profits to easily obtain and process data for ML.
- Providing data scientists and machine learning experts with a tool that helps them monetize their models and knowledge.
- Transforming ML computing from cloud oligopoly into fog computing with decentralization. Making it more invulnerable by removing a central point of failure.
- Direct GPU mining power on usable AI computations, giving miners ability for ROI even after Ethereum migration on PoS.
1.2. Market
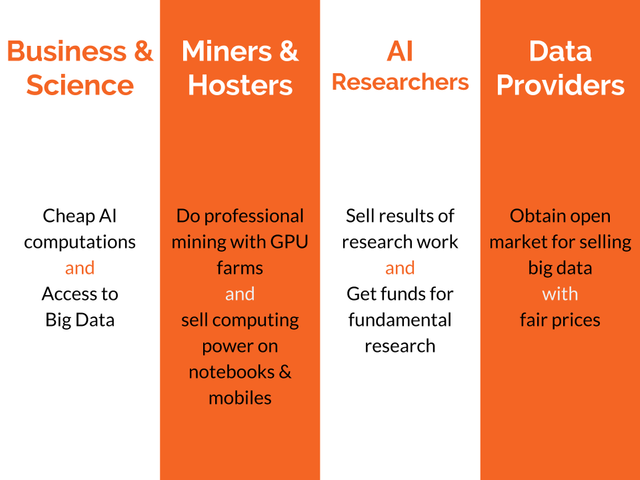
According to Forbes, big data market was estimated at $122 billions in 2015 and it will grow to more than $187 billions till 2019. Pandora can speed up its growth. Pandora targets to capture most of the market with its disruptive new way to compute ML models, which could bring total Pandora Network capitalization to tens of billions and more in term of 3-5 years. Our core strategy to capture the market is to give its players ability to do things that they cannot do today: sell their computing power to AI tasks, sell their ML models to a broad community, monetize AI research, monetize data sets on an open market with fair price, easily find and acquire datasets required for training and computing ML models for business and research tasks. For instance, ML development is highly dependent on availability of big data and computing power. However, after Kaggle was bought by Google there is no place left where data scientists / ML engineers can sell their work, especially in a decentralized way. There is no even AirBNB, Etsy and Uber for ML and data, not to mention decentralized solutions. So, the project providing solution for these basic needs could spread on the market like wildfire.
1.3. The Big Perspective
Decentralizing machine learning and AI industry could not only enhance the market by making it opened and free, but would significantly speed up the development of more efficient forms of AI due to availability of nicer data sets and possibility of ROI for ML research.
Furthermore, blockchain hybridization with AI might give some unexpected long-term synergetic side effects, like bitcoin didn’t just resolve the double-spending problem, but by inventing blockchain it created the basis for massive disruption in distant industries. For introduction one may read this Medium article, look at Slideshare presentation and YouTube presentation video.
Briefly addressing AI evolution we may compare it to human intelligence evolution. In terms of cognitive architectures, human society is a form of multi-agent system, where each “agent” is independent and intelligent (well, at least compared to physical systems), and communication between agents is necessary for their evolution as a whole. A crucial role in human intelligence evolution has been played by adoption of the written language (that’s where the history started). In terms of computer science, written language allows communications that combine persistence and consensus. Consensus means that each agent gets the same sense of a signal as others. If we take nature and humanity evolution as samples, we may say that DNA translation will be the same for bacteria as for a human being, and written text is understood in the same way by all native speakers. Persistence means that sense does not diminish with time. Thus, DNA and chemical molecules are “written languages” both in terms of consensus and persistence — in the same way as our language. So appearance of a glyph (hieroglyph, logogram and letter) was a crucial step in sustained and accelerated progress for the humanity. Another similarity is that in any real-world multi-agent system, communicating agents cannot trust each other: genomes transferring DNA might be “fooled” by viruses and bacteria; chemically communicating cells — by parasites; human society — by plagiarists and populists. So the point is not just to communicate and extract the same sense from communications; not just to persist with information and context, but also to be able to do that in a trustless environment. As you see, all this is perfectly fitted for blockchain. Thus, here is our main secret revealed: blockchain will do for multi-agent AI the same thing that written language did for humans; it should provide means of accelerated evolution towards human- and superhuman AIs. We imagine that in the future Pandora Boxchain computation resource could be used not only by a human/business clients, but also by other AI agents, creating new kernels and collecting data, and evolving themselves further and further, in a decentralized unstoppable environment. At the same time A.I. agents are incentivised to play a “trading game”: a non-zero-sum cooperative strategy, rendering them not alien to humans, but rather cooperative the same way humans can cooperate with non-human legal entities (companies etc).

From this large perspective we have chosen the name “Pandora” for our project because it was the first woman created by Zeus to punish humans for the intelligence given to them by Prometheus. We call it ”boxchain” as an allegory for Pandora’s Box, since we believe that the success of the project might trigger a sequence of events leading to the appearance of generic forms of AI on our planet, a new type of intelligence. We also highly appreciate female intelligence and gender equivalence and that’s why have selected Pandora, not Prometheus for the name of our project.
2. Economics Models
2.1. Pandora Economics Overview
Today, there are no decentralized or even centralized open markets for each of the components required for machine learning: big data, ML models and computing power. Pandora will be a fully decentralized platform without central supervision. It will unite three different AI-related markets:
- Big Data: owners of big datasets publish information about their data
- Kernels (NN/DL models): trained DL models
- Hosters: resource market for AI computations with GPU/TPU etc.
Thus, it would resemble a Kaggle analog, but (a) it will be a market, where kernel authors and dataset providers will be able to earn money, (b) it will be decentralized. One may think of Pandora as an “AirBNB” for artificial intelligence industry.
Pandora Boxchain will interconnect the following types of economic agents:
- Big data owners/providers – publish their datasets for rent at a price of their choice. Both algorithms and datasets are cryptographically protected while being used in calculations.
- Creators of ML models (researchers, developers), or Kernel authors – publish their models on open market at a price of their choice for rent to the end-users and earn money for their fundamental research with Research Work Reward Algorithm (see section 3.4 for details).
- Hardware owners (Worker Nodes) – rent their GPU for computations and earn from mining with Proof of Cognitive Work. They will likely accept a task as long as the payment is above the price of electricity, as well as above what they can receive by alternative uses of their hardware, e.g. by mining various coins.
- Validators (Worker Nodes with high stake and reputation) – create the decentralized blockchain consensus by doing the verification of computation results and participating in Arbitration
- Clients, or customers – buy algorithms, datasets, computational power for their research or business tasks.
Who will be earning money in Pandora Boxchain Network:
- Worker Nodes – via mining (proof of cognitive work consensus) and contract execution payments from customers
- Kernel authors – for kernel usage, by customer, and also in a special form of mining called Research Work Reward Algorithm (see section 3.4 for details)
- Data providers – for data usage, by customer
All payments inside Pandora Network would be performed using Pandora AI Network Token (PAN).
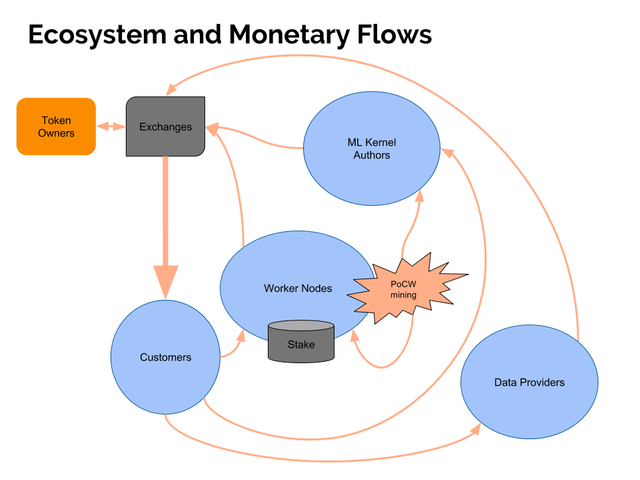
Transactional flow in PANs would be organized as follows:
- Customer buys some PAN on exchange
- Customer selects kernel and data providers on a decentralized market using dApp, accepts their terms and puts sufficient amount of PAN under contract with escrow
- Kernel authors and data providers, as well as Worker Nodes get paid for each part of performed cognitive work from deposited amount (reducing it) under proper consensus with validation and arbitration procedures, which secure such payments
- Additionally to that Worker Nodes will get PoCW reward for block mining in coinbase transactions, which becomes inflationary source for liquidity
- Additionally to that all Kernel authors would get rewards in 10% of mined amount according to Proof of Research Work algorithms proportionally to their modified research h-index (see section 3.4 for the details)
2.2. Reputation and Stakes
Reputation and stakes (collateral tied to ensure the proper behavior of an agent) serve the same purpose of distinguishing the quality of actors, but are not totally interchangeable. The importance of reputation depends on whether it brings consistent profits to sellers. It is therefore very important for kernel and big data markets that verified buyers post positive reviews of the published kernels and datasets and increase sellers credibility and visibility. We expect that these categories of sellers will cherish their reputation similar to e.g. Ebay sellers and that verified buyer reviews are a sufficient mechanism to accomplish it. Quality problems will be solved not by centralized means, but by e.g. third-party search engines. For these markets, the stake required to publish will be very minimal and exists only to avoid spam publishing.
Owners of hardware comprise a very competitive market and the platform will benefit if they are many. Therefore, their minimal stakes need to be moderate to keep the entrance barriers low. In addition to this, reputation role is somewhat limited because only positive reputation matters, as negative reputation consequences can be avoided by sacrificing the stake, destroying and recreating the “node”. Nodes with better reputation may be rewarded with increased chances to receive additional tasks. In addition to reputation, there will be further mechanisms to control the quality of nodes. A small part of each task will be given for computations to a random validating node who has incentives to find whether the results are faulty.
Validating nodes do the most trusted work. These are nodes who have simultaneously high reputation (which they have gained over time by working as nodes or by participating in arbitrations) and high collateral stake.
A node's reputation is earned over time, as node performs calculations which are found true in selective checks done by validators. Any node found to be cheating is destroyed and loses the total of its stake and reputation. Better reputation leads to higher probability to receive calculating work and to receive more high-paying tasks. Therefore, gains in reputation constitute an economic incentive to do calculation tasks properly and often, since applying more effort now leads to higher payoffs in the future. The effect of reputation is nonlinear, so as not to exclude newer nodes from participation in the network.
Reputation cannot be bought, whether with tokens or through other means, and it cannot be granted by someone. It is strictly personal to nodes and not transferable, as it constitutes a meritocratic benchmark of a node's actual contribution to network. Also, reputation is a measure of "suck costs": since nodes with high reputation have invested much time and resources to Pandora network operation and have much to lose if the network is compromised, they are very likely to protect the network and to act in good faith. In the future, when Pandora network matures, the founders are planning to step aside and pass the Pandora Foundation to outstanding members of the community, to nodes with high reputation.
2.3. Economic Incentives
We will use Game Theory to examine ways in which equilibrium is reached and all economic agents contribute to platform’s success while following their own economic interests.
- Kernel authors and dataset owners sell unique products and it is in their interest to provide precise descriptions of their product that will help the buyer to match the product and his business or research task. Dissatisfied verified buyers can leave negative reviews that could disincentivize future buyers, since reviews form the impression about the product and contribute to product’s credibility and visibility, allowing it to stand out from the crowd. Over time, bad products or products with a poorly matching description will be marginalized and will not bring profits. There will also be a fee payable for publishing, very minimal but sufficient to make it costly to flood the platform with junk kernels or datasets.
- Nodes are motivated to do calculations correctly and stay available because they will not be paid and, additionally, will lose their collateral stake when their fault is detected in arbitrage. And the platform is built in a way that faults will practically always be detected. In addition, a moderate collateral stake is useful to prevent creation of fake nodes who could burden the network.
- Validating nodes have the incentive to check and report truthfully any discrepancies in the results of calculations, because they gain when they catch a faulty node and because they lose their stake and reputation in arbitrage if they slander a node that did no mistake.
- Clients are motivated to leave true reviews, just like generally in marketplaces like Ebay or Amazon. Since calculations are precluded from being a source of bad results, it becomes easier to place the responsibility on kernel or dataset, although confusion between these two sources is still possible. Only verified buyers, i.e. those who have paid for work can leave a review, and this prevents mass-publishing of false reviews. It could be possible to publish false reviews at the cost of paying for calculations, but this strategy is relatively expensive and not viable long-term, since dissatisfied customers will add negative reviews over time.
2.4. Validation and Arbitration
After the calculation results are published, there are 3 rounds of testing the validity of calculations.
- Small, randomly chosen portions of the task are given for recalculation to a randomly chosen “validator” (a node with a high reputation and stake). If the validator confirms the result, no arbitration is required. If the validator questions the result, the node is destroyed, losing its stake and reputation, unless it raises the stake and proceeds to arbitration.
- For arbitration, 3 random validators are chosen. The client who has paid for the task is allowed to veto any of them and randomly select a new one. Then, these 3 validators check the results. If the 3 validators could not agree, then we go to the second (final) round of arbitration. If all three validators reach the same result, the arbitration has reached a verdict. The node or the validator of the previous stage that was found to be faulty is destroyed and its stake is distributed among all true participants, unless it raises the stake and proceeds to second arbitration.
- In the second arbitration, which is final, validation is crowdsourced: participation is open to any node in the network who has either high reputation or high stake. Participation there is a great way for high-stake nodes to gain reputation quickly; the main reward here is reputation and not payment. Any last-minute huge influx of nodes will prolong the arbitration for a while, so that the community gets the time to react. If 75% of the participants reach the same result in a predetermined amount of time, the verdict is reached. Any faulty participants at all stages are destroyed, losing their stake and reputation, and their stakes are distributed among true participants. If it is impossible to reach 75% consensus, all participants are penalized by losing a part (not all) of their stake and reputation and the task is returned to the client unsolved or reenters the queue anew.
Economic incentives and motivation during the validation of calculations.
- The initial validator receives a significant reputational gain if a) it discovers a nod’s fault in calculations and b) this will not be questioned by other validators in further arbitration. Therefore the best strategy is to do the checking truthfully. If it lies, the affected node will proceed to arbitration where the faulty validator will lose its stake and reputation.
- The 3 validators that do the arbitration receive the same gains for declaring faulty the node (with its stake raised to proceed to arbitration) as for declaring faulty the first stage validator. In order to receive these gains they must all report the same result. At the same time, they are risking their stake and reputation if they lie. Therefore, even if they could communicate and collude between themselves, it would be too risky and non-rewarding. They have the motivation to coordinate by reporting the truth.
- In the final round of arbitration, collusion between validators would be hard because there is uncertainty about the number and the identity of validators that will choose to participate; high participation could crush any potential colluding attackers who would then lose valuable stakes and reputation. High participation in arbitration is expected because it’s a rare chance to gain reputation quickly. Another level of protection is that if participating validators do not reach a 75% consensus, nobody gains and everyone is slightly penalized. Therefore, the best strategy is to do the checking of calculations and report it truthfully for reputational gain. When an massive attack is perceived, there is motivation for validators to join arbitration and protect the network, gaining both in reputation and stake.
Concluding, at all stages of validation the actors are motivated by positive gains to report truthfully. They are disincentivized from lying by the risk to be discovered and lose their stake and reputation (or at least part of it, if a major collusion is present).
As an analogy of the proposed algorithm one can take the “consensus algorithms” of all mathematicians in the world, where each mathematician does not replicate all computations of the whole world mathematics but still uses them with trust because of peer reviewing and scientific reputation. Here, peer reviewing will be equivalent to the described validation and arbitrations process, and reputation – to Worker Nodes reputation in Pandora Network.
Described validation and arbitration process can be used outside of the scope of Pandora Project and AI-based computations and can be applied to any deterministic computing, including those used in Turing-complete smart contracts like in Ethereum network. Under such conditions only small part of all computations will be performed by more than one node, reducing total load for network from O(n*c) to O(c), where n is a number of computing nodes in network and c is an amount of computations in all smart contracts.
2.5. Token Emission
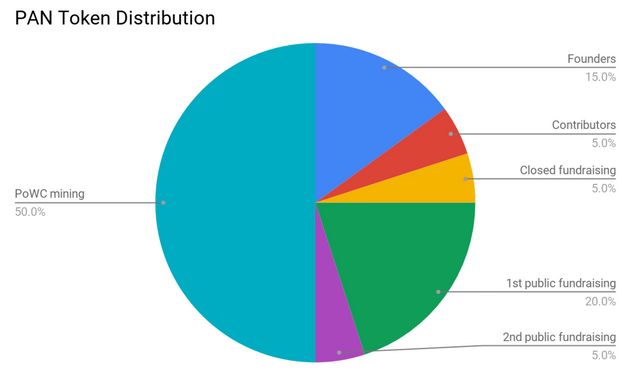
Pandora (PAN) is the local currency of Pandora Boxchain. The total supply is fixed at 10.000.000 PAN.
Half (50%, 5.000.000 PAN) of the supply is pre-mined and reserved for the team members, contributors and fundraising. The other half (50%, 5.000.000 PAN) will be mined with PoWC (section 3.3) over the period of 20 years.
Premined funds (50%) will be distributed as follows:
- 1.500.000 PAN (15% of supply) – founders
- 500.000 PAN (5% of supply) – KPI-based grants for contributors
- 500.000 PAN (5% of supply) – non-public donators during the current funding round (see section 2.4 pt. 2)
- 2.000.000 PAN (20% of supply) – public donators in the first phase of crowdfunding (see section 2.4 pt. 3)
- 500.000 PAN (5% of supply) – public donators in the second phase of crowdfunding (see section 2.4 pt. 4)
2.6. Mining Schedule
The system will update amount of mined tokens per day every 10 days.
Start reward per block - 0.01
Start variable A = 14.35445273
Start variable B = 1
Every 2000 block reward (R) is recalculated:
Ai = SQRT(Ai-1)
Bi = Bi - 0.00005
R = Ri-1 * Ai * Bi
3. Technology
3.1. Technology Overview
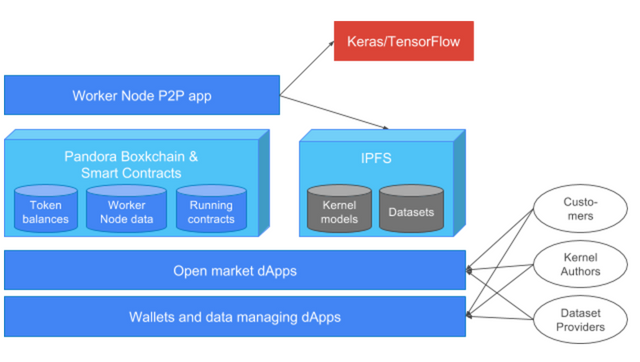
Pandora Network is build of Nodes that can be of two types: Workers and Witness. Worker Nodes have hardware suited for neural network computations and perform that computations upon request according to the consensus mechanism (see below). Worker Nodes must allocate a stake in PAN (there is minimal stake limit) as a collateral and also have reputation assigned (see section 2.2 for the details of stakes and reputation). Worker Nodes with high stake and reputation can participate in validation and arbitration as a part of consensus algorithm described in section 2.4. Such Worker Nodes are called Validating Nodes. Witness Nodes contain Pandora Boxchain and do not participate in computations; they can provide data for light and normal clients and host dApps.
Pandora Network participants (described in section 2.1) interact with its decentralized market by using dApps. For instance, via dApps creators of ML models and data providers can upload and assign prices for their propositions; clients can browse existing ML models and data, create job contracts (processed later by network Working Nodes) and write reviews.
3.2. Workflow Details
- Researchers and developers of ML models register model provider accounts in Pandora Boxchain. They publish their Keras or TensorFlow batches that include neural network architecture in JSON format (exported from Keras or TensorFlow) and trained weights in HDF5 format.
- Data owners/providers publish their data in HDF5 format and define prices for their usage. Data are split into small batches and uploaded into IPFS with file hashes saved into Boxchain.
- Client with a business need that requires machine learning facilities goes to a decentralized (Web3) market, where he sees available machine learning kernels and data sets like goods in Amazon etc. They have reviews and ratings attached. Client searches by dataset descriptions, ratings/reviews and prices and selects kernels and dataset (instead of selecting a dataset, the client can provide his own and thus not pay for data).
- Client selects level of Quality Control he wants to use (similar to gas limit in Ethereum) and adds premium for it.
- Client pays deposit in PAN to the newly created Pandora сomputing contract.
- Within Pandora Boxchain a deterministic lottery happens (for instance based on Pandora contract creation date, data/kernel file hashes, block numbers etc), where chances of a Worker Node to win are proportional to its stake and reputation. Results of this lottery define the Worker Nodes allocated to computing the specific contract.
- Worker Nodes perform computation, upload results in form of HDF5 files into IPFS and submit hashes of their work into Boxchain.
- Upon completion of all work second lottery happens which will define Validating Nodes to perform Quality Control. Probability of winning lottery is coupled with Validators reputation and stake. Number of batches to be validated are defined by the user-selected quality control level (pt. 4), each batch is validated by separate Validating Node.
- Upon completion of validation and possible arbitration (as described in section 2.4) the client receives his computed data in form of HDF5 files in IPFS and all participants receive their rewards according to section 2.1.
3.3. Proof of Cognitive Work (PoCW)
Pandora Boxchain uses two levels for consensus:
- Blockchain-level consensus that secures network non-computational transactions (PAN transfers, publication of kernels and datasets, computation request contracts etc). No Pandora-specific mining happens here. Some external blockchain may be used for this first level; at the initial stage we will use the Ethereum blockchain.
- Boxchain consensus with PoCW algorithm. This level of consensus secures AI computations and performs mining of PAN tokens upon completion of cognitive work.

Cognitive work is a work of finalized, successful and correct computations on users datasets performed with artificial neural networks. Mining, based on cognitive work (PoCW) represents much more efficient form of consensus than usual PoW algorithms producing no useful result.
PoCW is secured with specific validation and arbitration process, described in details in section 1.2.4, which ensures that all computations are done with strong incentives for the nodes to perform computations correctly.
3.4. Researchers’ Reward Algorithm
While 90% of mined PAN tokens with PoWC are awarded to the mining Worker Node account, 10% are distributed to the accounts of all creators of ML kernels using special Researchers Reward Algorithm.
Using special oracles ML kernels will be linked to scientific works and a Hirsch index will be computed based on the amount of references of the specific research work. This index would be used as a “researcher reputation”, and 10% of mined PAN tokens will be distributed to all researches proportionally to their reputation. This way we would like to stimulate AI research and in the future we will develop specific anti-plagiarism algorithms on top of this system.
4. State of the Project
Our team has already self-funded the development of technological description and economic model for the Pandora Network and Proof of Cognitive Work algorithm, as well as proof of concept in code written in Python, Ethereum smart contracts and Javascript that covers the complete process cycle. Code is available on GitHub. Our proof of concept code allows deployment of AI computation contract with IPFS-stored ML kernels and datasets and performance of automatic neural network deployment and computations on the Worker Node using standard Keras and TensorFlow libraries.
5. More About the Project
You can follow our updates and monitor project progress using following media and social profiles:
You can also view video presentation of the project (in Russian)
Maybe we can talk about this project more in our Discord http://discord.me/adsactly
bagaimana cara menambang coin tersebut?
Congratulations @pandoraboxchain! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPGood!