VS2019 16.2: 新版本对游戏性能的优化
朋友们,又优化了一点点:%2~%3。
游戏可以说是提升Windows市占率的重量级推手,此次的16.2的版本中,开发团队进一步的对游戏运行时性能进行了优化,如开头所说的,对比之前16.0版本,性能提升了2~3%,虽说不是很多,但是也是值得夸赞一番:你家孩子之前考了95分,这次通过努力,考了98分,是否是一件值得夸赞的事情?我肯定是要夸一下!
吞吐量
在工程链接阶段,16.2大幅提升了编译吞吐量,请参见我之前的关于链接器优化的文章,这里就不赘述了。
新的优化点
之前的C++后端更新的文章中,我们看到了MSVC编译器的一系列优化,今天再来重点的说道说道。下面有一些工程示例,这些例子都是在x64模式下编译,并使用了这些编译选项:/arch:AVX2, /O2, /fp:fash, /c /Fa
在AVX架构下优化循环
下面的一个例子,展示了一个测试两个vector是否偏离一定程度的函数实现。
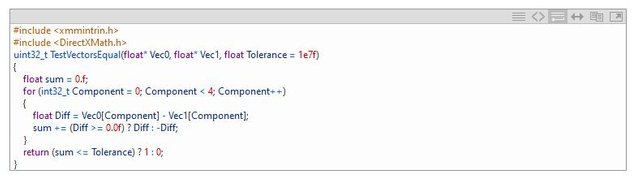
在16.2中,开发团队优化了代码生成,使之可以借助硬件加速来实现优化。我们来看看反汇编代码,左边是16.0版本生成的反汇编,右边是16.2生成的反汇编:
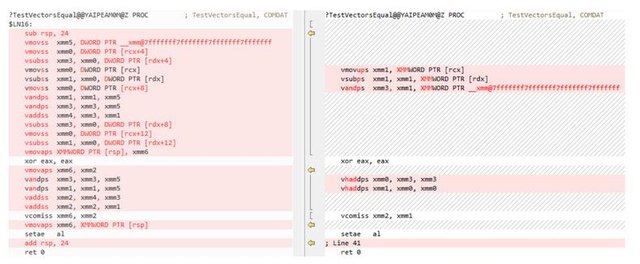
从上图可以看到,在旧版本16.0中,编译器识别到了Reduction Loop,但是却没有进行矢量化操作,而是就地全部展开。而新版本16.2中,编译器识别到了Reduction Loop并对其进行了矢量化,而且使用了horizontal add指令进行求和操作,从而使生成的代码更加紧凑而且性能更优。
在单个vector元素上识别intrinsics
新版本编译器可以在单个最底层元素上优化vector intrinsics。
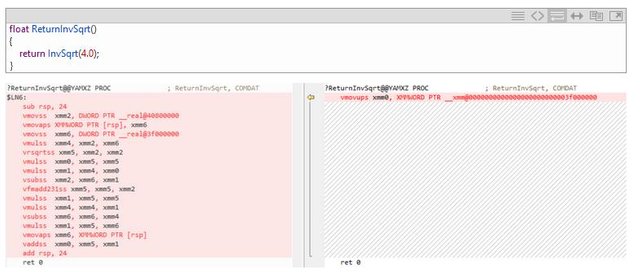
下面的一个例子,是计算平方反比的一个函数实现。这个函数来自虚幻引擎的数学计算库。它在虚幻引擎中,主要用来渲染大部分的游戏对象。
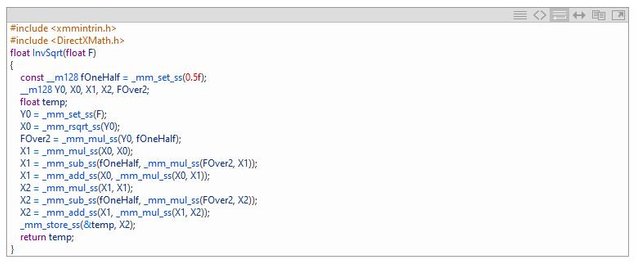
以下是函数的反汇编代码,左边为16.0,右边为16.2。编译为x64模式,开启AVX2选项。
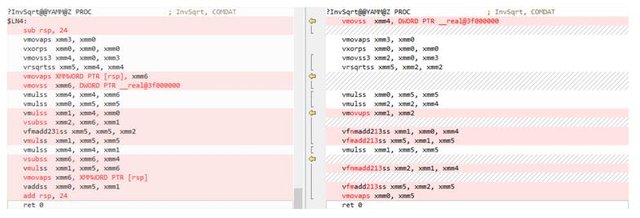
从上图我们可以看到,16.0对所有的intrinsics逐一生成了代码,而16.2可以更加智能的识别intrinsics并将乘法和加法操作合并到FMA指令中去。在将来的16.3/16.4版本中,我们还将看到更多类似的优化点。
即使是现在,对于一个给定的常量,代码生成也会呈现出上述的特征:
VS2019 16.2: 新版本对游戏性能的优化
漫漫开发路 2019-08-18 13:09
朋友们,又优化了一点点:%2~%3。
游戏可以说是提升Windows市占率的重量级推手,此次的16.2的版本中,开发团队进一步的对游戏运行时性能进行了优化,如开头所说的,对比之前16.0版本,性能提升了2~3%,虽说不是很多,但是也是值得夸赞一番:你家孩子之前考了95分,这次通过努力,考了98分,是否是一件值得夸赞的事情?我肯定是要夸一下!
吞吐量
在工程链接阶段,16.2大幅提升了编译吞吐量,请参见我之前的关于链接器优化的文章,这里就不赘述了。
新的优化点
之前的C++后端更新的文章中,我们看到了MSVC编译器的一系列优化,今天再来重点的说道说道。下面有一些工程示例,这些例子都是在x64模式下编译,并使用了这些编译选项:/arch:AVX2, /O2, /fp:fash, /c /Fa
在AVX架构下优化循环
下面的一个例子,展示了一个测试两个vector是否偏离一定程度的函数实现。
在16.2中,开发团队优化了代码生成,使之可以借助硬件加速来实现优化。我们来看看反汇编代码,左边是16.0版本生成的反汇编,右边是16.2生成的反汇编:
从上图可以看到,在旧版本16.0中,编译器识别到了Reduction Loop,但是却没有进行矢量化操作,而是就地全部展开。而新版本16.2中,编译器识别到了Reduction Loop并对其进行了矢量化,而且使用了horizontal add指令进行求和操作,从而使生成的代码更加紧凑而且性能更优。
在单个vector元素上识别intrinsics
新版本编译器可以在单个最底层元素上优化vector intrinsics。
下面的一个例子,是计算平方反比的一个函数实现。这个函数来自虚幻引擎的数学计算库。它在虚幻引擎中,主要用来渲染大部分的游戏对象。
以下是函数的反汇编代码,左边为16.0,右边为16.2。编译为x64模式,开启AVX2选项。
从上图我们可以看到,16.0对所有的intrinsics逐一生成了代码,而16.2可以更加智能的识别intrinsics并将乘法和加法操作合并到FMA指令中去。在将来的16.3/16.4版本中,我们还将看到更多类似的优化点。
即使是现在,对于一个给定的常量,代码生成也会呈现出上述的特征:
从上面的反汇编中,我们可以看到:在16.0中,编译器逐一地生成代码,而在16.2中,编译器可以在编译期就计算出值(这里使用了/fp:fast编译选项)。
更多的FMA模式
对于FMA生成,编译器按照如下规则进行代码生成:
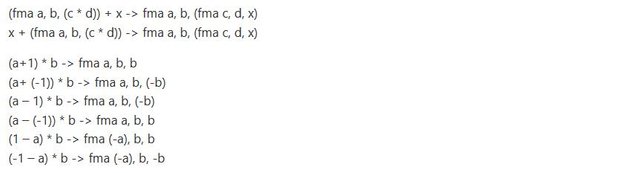
也做了如下的FMA简化:

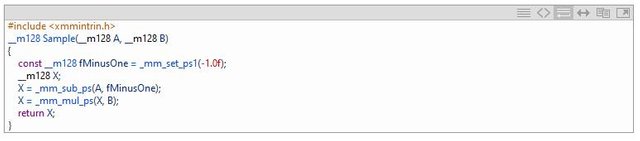
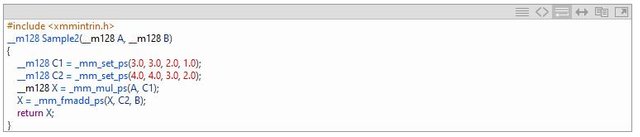
之前的FMA代码生成只能适用于本地的vetor,现在也可以支持全局的vector了。
下面是两个优化的例子:


Memset和初始化
开发团队还优化了对memset的代码生成,具体来说就是将内联展开方式转换为调用更加优化版本的CRT调用。在循环中以相同字节的方式(例如 0xABABABAB)来保存一个常量也将使用CRT版本的memset。对比本机代码生成,在开启了SSE2开关下,调用memset的性能提升将至少快2倍,在AVX2下还会更快。
内联
通过对内联的探索,编译器对包含有控制流的小函数进行了更加激进的内联。
在虚幻引擎中的优化 – Infiltrator示例
Infiltrator基于虚幻引擎,下面的例子使用Infiltrator来模拟真实世界的一款游戏。
游戏的性能通过测试帧率来衡量,帧的渲染耗时越短,则表示帧率越高,也即性能更好。以下的测试基于AMD Zen 2的新款CPU。
具体测试的配置如下:
CPU: AMD64 Ryzen 5 3600 6-Core Processor, 3.6 Ghz, 6 Cores, 12 Logical processors
显卡:Radeon RX 550
内存:16 GB
操作系统:Windows 10 1903
测试结果
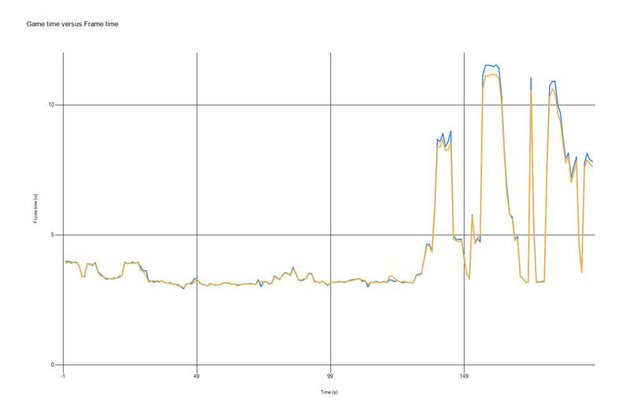
在上面的测试结果中,蓝色线表示使用VS2019旧版本编译,黄色线表示使用VS2019 16.2编译,横轴表示时间,纵轴表示每帧渲染时间。
从上图中我们看到,大部分时间下,我们看到帧率没有大的区别,但是在CPU密集渲染时,我们看到VS2019 16.2有2~3%的性能提升。
总结
大部分人热爱游戏,玩家对游戏的运行时性能也十分敏感,倘若关键时刻,帧率掉下来,丢了个三级头,就比较可惜了。
亲爱的游戏开发者朋友,全新VS2019 16.2,值得你拥有。