数据结构学习笔记(JavaScript 描述)
常用的数据结构包括数组、列表、栈、队列、链表、字典、散列、集合等。每种数据结构都有其自己的特点。很多时候,选择一个恰当的数据结构,可以很大程度简化棘手的问题。
- 数组
- 常用方法
- 二维数组
- 列表
- 栈
- 队列
- 链表
- 字典
- 散列
- 集合
数组
数组的定义是:一个存储元素的线性集合,元素可以通过索引任意存取。索引通常是数字。然而在 JavaScript 中,数组是一种特殊的对象,索引为该对象的属性,而 JavaScript 中对象的属性名必须是字符串类型。看上去很奇怪,不过也正因此,数组可以作为其他数据结构的基础。
常用方法
创建数组的方法有很多,不过一般推荐使用 [] 操作符。
var nums = []
nums.unshift(num) //在开头添加元素
nums.shift(num) //删除开头元素
nums.pop() //删除末尾元素
nums.push(num) //在末尾添加元素
nums.splice(start, n, elements) //在中间 `start` 位置删除 n 个元素,并添加若干个 elements。
nums.reverse() //反序
nums.sort() //将数字从小到大排序
二维数组
按照《JavaScript 精髓》一书中的做法,通过扩展 JavaScript 数组对象实现。
Array.matrix = function(numrows, numcols, initial) {
var arr = []
for (var i = 0; i < numrows; ++i) {
var columns = []
for (var j = 0; j < numcols; ++j) {
columns[j] = initial
}
arr[i] = columns
}
return arr
}
列表
列表是一组有序的数据,适合用于保存的数据不太多时。
列表的抽象数据类型定义:
listSize pos length
insert() append() remove() clear()
front() end() currPos() moveTo()
prev() next() hasPrev() hasNext()
toString() getElement() contains()
栈
栈是一种特殊的列表,栈内的元素只能通过列表的一端访问。遵循后入先出的数据结构。因此,只能访问栈顶的元素,即最后加入的元素。
push() //向栈内压入元素
pop() //删除栈顶元素
peek() //返回栈顶元素而不删除它
队列
队列也是一种列表,不同的是队列遵循先进先出的数据结构,即只能在队尾插入元素,在队首删除元素。
enqueue() //向队尾插入元素,即 push()
dequeue() //删除队首元素,即 shift()
front() //返回队首元素
back() //返回队尾元素
链表
与列表的是,链表的底层数据结构不是数组,而是节点。与数组相比,链表的性能更加优越。缺陷是不方便进行随机访问。数组元素通过位置来进行引用,而链表元素则通过相互关系来引用。每一个节点都包含元素数据和指向下个节点的链接。
// Node 类
function Node() {
this.element = element
this.next = null
}
// 链表类
function LinkedList() {
this.head = new Node("head") //初始化头节点
this.find = find //查找
this.insert = insert //插入节点
this.remove = remove //移除节点
this.display = display //显示
}
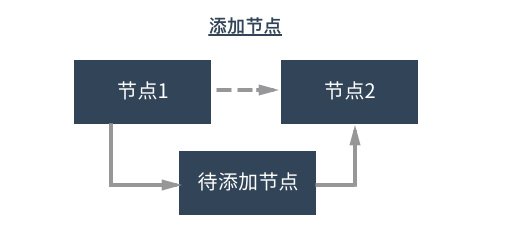
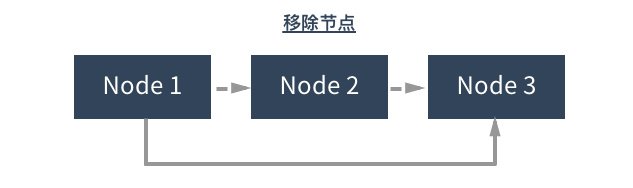
双向链表
为了能够方便的从后往前遍历,为每个节点添加指向前驱的链接。
// Node 类
function Node() {
this.element = element
this.next = null
this.previous = null
}
循环链表
与单向列表相似,唯一的区别在于初始化链表时,头节点的 next 属性指向它本身。这种行为会传导下去,这样,链表的尾节点就会指向头节点。
function LinkedList() {
this.head = new Node("head") //初始化头节点
head.next = head // 头节点 next 属性指向自身
//...
}
字典
字典通过键-值对来存储数据。可以利用 JavaScript Object 类本身的特性来实现 Dictionary 类。使用 () 操作符来引用,而不是 []。
function Dictionary() {
this.datastore = []
this.add = add // add(key, value),即 this.datastore[key] = value
this.find = find
this.remove = remove
this.showAll = showAll
this.count = count
this.clear = clear
}
散列
散列是一种可以快速插入或取用的数据存储技术。散列使用的数据结构称为散列表。使用散列表存储时,通过有个散列函数讲键映射为一个数字,数字范围是 0 到散列表的长度。散列表的长度是预先定义的,一般取质数。当两个值映射到同一个值时则会发生碰撞。
散列算法
除留余数法:最简单的方法。以数组的长度对键取余(当键值为字符串时取其 ASCII 码之和),为了尽量避免结果相等发生碰撞,所以数组长度一般取质数。
霍纳算法:除留余数法很容易会发生碰撞。而霍纳算法则可以更好地避免这个问题。霍纳算法仍然计算字符串中各个字符的 ASCII 码值,不过在求和时每次都要乘一个质数,一般建议使用一个较小的质数。
function HornerHash(string, arr) {
const H = 31
var total = 0
for (var i=0; i<string.length; ++i) {
total += H*total + string.charCodeAt(i)
}
total = total % arr.length
return parseInt(total)
}
碰撞处理
开链法:在实现散列表的底层数组时,每个数组元素又是一个新的数据结构,这样就可以存储多个键了,当两个键散列后的数值相同时,依然可以保存在相同的位置。
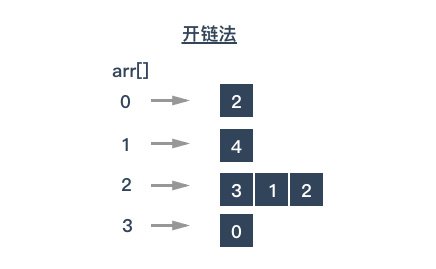
线性探测法:线性探测法属于一种更一般的散列技术:开放寻址散列。当发生碰撞时,线性探测法会检查散列表中下一个位置是否为空,如果为空,则填入数据,否则,继续检查下一个位置,知道找到空位并填入。
一般来说,如果数组的大小是到存储数据个数的1.5倍,则使用开链法。如果数组大小为待存储数据的两倍及以上,则使用线性探测法。
集合
集合是一种包含不同元素的数据结构。集合具有两个特性。首先,集合元素是无序的,其次,集合中不允许相同成员存在。
集合的几个基本操作:并集、交集、补集、子集。
 Originally posted on https://steemit.com . Thanks for reading my post, please feel free to follow, upvote, reply, resteem @hopsken , which will motivate me to create more quality posts.
https://steemit.com 首发。感谢阅读,欢迎follow, upvote, reply, resteem @hopsken 鼓励我创作更多更好的内容。
Originally posted on https://steemit.com . Thanks for reading my post, please feel free to follow, upvote, reply, resteem @hopsken , which will motivate me to create more quality posts.
https://steemit.com 首发。感谢阅读,欢迎follow, upvote, reply, resteem @hopsken 鼓励我创作更多更好的内容。
还是java好啊 ,c中除了数组,其余的都得自己去实现.
emm各有各的优点嘛😂