简单几行代码爬取百度实时热点,最后附上源代码!
自从学了Python了之后,不停的在练习,今天就拿百度练下手爬取实时热点,需要用的库有requests_html 非常的简单! 程序运行结果如下图:
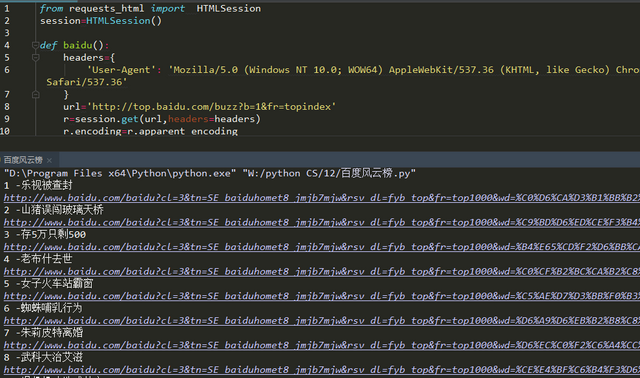
这里要简单说下:用到了css选择器,选择list-title的元素对象,还有需要注意的是这里百度的页面需要编码,因为不是UTF-8的! r.encoding=r.apparent_encoding 用这个即可解决! 获取的链接是一个集合,我们只需要for 遍历输出即可!
下面附上源代码,如有不足的地方欢迎大神指出!
from requests_html import HTMLSession
session=HTMLSession()
def baidu():
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
url='http://top.baidu.com/buzz?b=1&fr=topindex'
r=session.get(url,headers=headers)
r.encoding=r.apparent_encoding
r=r.html.find('.list-title')
top=1
for i in r:
print(top,'-'+i.text)
for x in i.links:
print(x)
top+=1
if __name__ =='__main__':
baidu()