Tensorflow 2.0 快速入门 —— RNN 预测牛奶产量
前面两篇文章我们通过线性回归和 MINST 手写识别的项目,学习了如何使用 Tensorflow 2.0 解决预测和分类的问题。同时也回顾了神经网络以及 CNN 的套路。这篇文章我们同样通过 RNN 的实例再次巩固一下 Tensorflow 2.0 的使用方法。
1. Keras 方法回顾
如下图所示,数据记录了1962年到1975年一共14年每个月牛奶的产量。
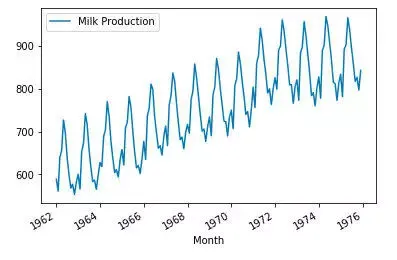
归一化处理之后,我们将数据分成训练和测试两个数据集。前13年为训练集,最后一年保留为测试集。在训练集中我们设计了一个12个月大小的窗口按月平移,产生1212组数据。神经网络模型的输入为每组 前12 月数据,输出是接下来第13个月*的数据。
这里我们使用的是 GRU(Gated Recurrent Unit) 结构的 RNN 神经网络。用Kears 的 Sequential 模型 API 构建 GRU 结构的神经网络也非常简单。不过需要注意 seqlen, cellsize 的大小以及输入输出的Shape 即可。训练起来也非常简单,一个 fit 就搞定了。
模型预测部分稍微有点麻烦,由于是 多对一 的 RNN 神经网络,要获得12个月的数据,模型就需要以平移窗口的形式循环预测12次。具体过程这里就不赘述了,可参考之前的文章。
2. Tensorflow 2.0 方法
回顾 TF2.0 搭建和训练模型,在上篇文章中我们总结了如下几个步骤:
如果手写计算公式或神经网络结构,手动定义并初始化参数,注意每一层参数的 Shape.
如果用 Keras 预先定义的 layers 搭建神经网络,需继承
tf.keras.Model,并建立自己的模型。使用
with tf.GradientTape() as tape:记录计算过程,并在过程中计算 loss 函数使用
tape.gradient对loss 的 参数求偏微分定义 optimizer 并使用
optimizer.apply_gradients自动更新参数
2.1 模型搭建
TF2.0 搭建模型的函数在前文中已经详细介绍过了,搭建 RNN 与 CNN 的方式没有很大的区别,均采用 python 面向对象的编程方法,继承 tf.kears.Model 并创建自己的 Model 类。
class GRUModel(tf.keras.Model):
def __init__(self, batch_size, seq_length, cell_size):
super().__init__()
self.batch_size = batch_size
self.seq_length = seq_length
self.cell_size = cell_size
self.layer1 = tf.keras.layers.Reshape((self.seq_length,1), batch_size = self.batch_size)
self.layer_GRU = tf.keras.layers.GRU(self.cell_size, return_sequences=True)
self.layer_last_GRU = tf.keras.layers.GRU(self.cell_size)
self.layer_dense = tf.keras.layers.Dense(1)
def call(self, inputs):
x = self.layer1(inputs)
x = self.layer_GRU(x)
x = self.layer_last_GRU(x)
output = self.layer_dense(x)
return output
2.2 训练模型
实例化模型之后,选择好合适的 Optimizer 后就可以进入 with tf.GradientTape() as tape: 环节了。注意这里我们处理的是预测问题的 Supervised Learning, 所以这里 loss 函数计算直接使用 reduce_mean 就可以了。
for epoch in range(1000):
with tf.GradientTape() as tape:
y_pred = model(x)
loss = tf.reduce_mean((y_pred - y)**2)
if epoch%100 == 0:
print("epoch: {}, loss: {}".format(epoch, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(zip(grads,model.variables))
3. 模型验证
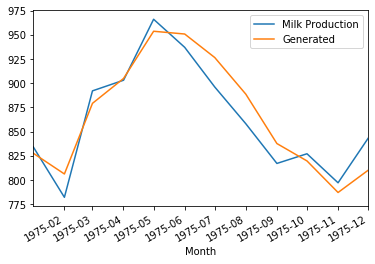
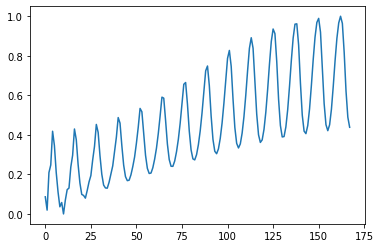
模型验证过程与之前使用 Keras 没有区别,下图为 预测结果与真实结果的比较,效果与使用 Keras Sequential API 的结果没有差别。 下图分别是用模型预测1975年牛奶产量,以及用1962年的牛奶产量预测接下来13年的牛奶产量。
相关文章
Tensorflow 2.0 快速入门 —— 引入Keras 自定义模型
Tensorflow 2.0 快速入门 —— 自动求导与线性回归
Tensorflow入门——Eager模式像原生Python一样简洁优雅
帅哥/美女!快来使用超级好用的steemit客户端---Partiko,这个可是我们华人团队开发的哦。感谢支持。