利用Tensorboard辅助模型调参

Image source from unsplash by Timothy L Brock
上一篇文章介绍了如何在 Keras 中调用 Tensorboard。这篇文章就来谈谈如何用 Tensorboard 帮助模型调参。
代码repo见这里
https://github.com/zht007/tensorflow-practice
还是用手写数字MINST数据集为例,之前我们通过CNN的模型将识别率提高到了99%,CNN网络中的各个参数是怎么得到的呢,多少层卷积层,多少层全连接层,每层神经网络多少个神经元或者多少个Filter呢?如何调整这些参数以保证模型是具有"识别"手写数字的能力,而并不是仅仅将每个图片对应的数字简单粗暴地"记"下来了呢?
这里我们就需要遍历不同参数的组合,然后使用 Tensorboard 可视化的工具找出最佳的参数组合。
1. 提取模型参数
最容易调节的参数:卷积层层数,每层神经元个数(Filter 数量) 和 全连接层层数,这几个参数分别list三个数。
dense_layers = [0,1,2]
layer_sizes = [32, 64,128]
conv_layers = [1, 2, 3]
2. 建立和训练各个模型
三个参数,三个for循环遍历,一共建立并训练9个模型。注意: tensorboard 需要在循环中调用。
NAME = "{}-conv-{}-notes-{}-dense-{}".format(conv_layer,layer_size,dense_layer,int(time.time()))
tensorboard = TensorBoard(log_dir='gdrive/My Drive/dataML/logs1/{}'.format(NAME))
当然为了提高速度,我们只训练了 30 个epoch.
完整代码如下:
for dense_layer in dense_layers:
for layer_size in layer_sizes:
for conv_layer in conv_layers:
NAME = "{}-conv-{}-notes-{}-dense-{}".format(conv_layer,layer_size,dense_layer,int(time.time()))
tensorboard = TensorBoard(log_dir='gdrive/My Drive/dataML/logs1/{}'.format(NAME))
print(NAME)
model = models.Sequential()
model.add(layers.Conv2D(filters = layer_size, kernel_size=(6,6), strides=(1,1),
padding = 'same', activation = 'relu',
input_shape = (28,28,1)))
for l in range(conv_layer - 1):
model.add(layers.Conv2D(filters = layer_size,kernel_size=(5,5),strides=(2,2),
padding = 'same', activation = 'relu'))
model.add(layers.Flatten())
for l in range(dense_layer):
model.add(layers.Dense(units = layer_size, activation='relu'))
model.add(layers.Dense(units=10, activation='softmax'))
model.summary()
adam = keras.optimizers.Adam(lr = 0.0001)
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=adam,
metrics=['accuracy'])
H = model.fit(x_train, y_train,
batch_size=50,
epochs=30,
verbose=1,
validation_data=(x_test, y_test),
callbacks=[tensorboard])
完整代码见github repo with MIT License
3. 在Tensorboard 中 查看结果
当然我们最关心的是测试集的准确率和损失函数
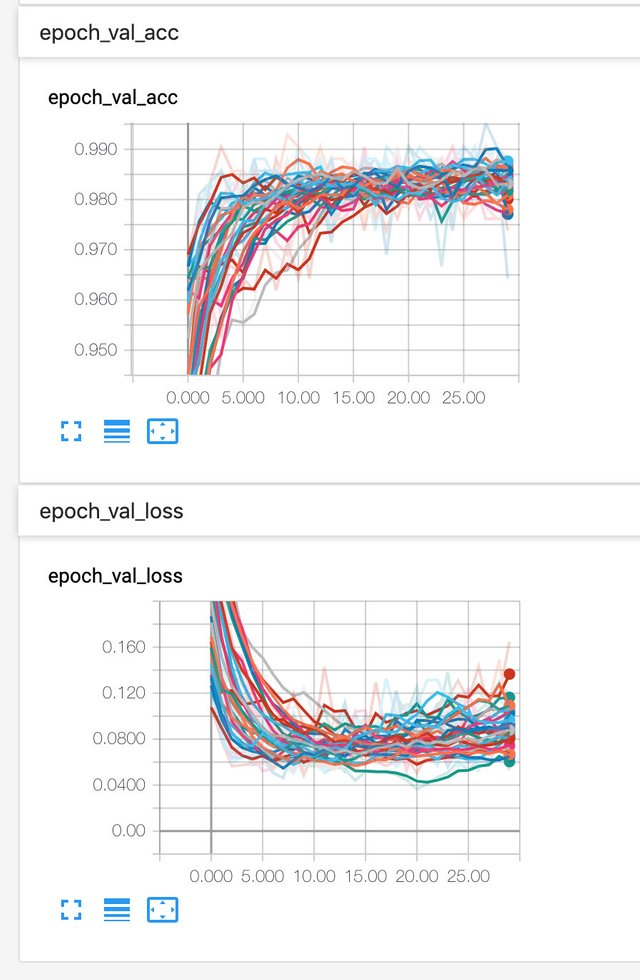
一共9个结果,看起来比较麻烦,可以通过左下角的工具,可以勾选自己想看的结果。通过对比,可以发现卷积层操过三层,神经元或 Filter 数量操过64个,全连接层超过2个,就会出现明显的过拟合现象。
4. 调整参数组合优化模型
通过 Tensorboard 的观察,我们继续优化模型参数,这次可以去掉造成过拟合的参数,增加对batch size的调节。
dense_layers = [1,2]
layer_sizes = [32,64]
conv_layers = [2]
batch_sizes = [50,100,200]
重复上述过程,进一步优化参数,去掉造成过拟合的参数,增加对Learning Rate的调节
dense_layers = [1,2]
layer_sizes = [32,64]
conv_layers = [2]
batch_sizes = [50,100]
learning_rates = [0.0005,0.0001,0.00005]
进一步缩小遍历的参数范围,增加训练的 epoch 数量,最终得到一组自己满意的参数组合
dense_layers = [1]
layer_sizes = [32]
conv_layers = [2]
batch_sizes = [100]
learning_rates = [0.0005]
5. 总结
机器学习模型调参的过程实际上是一个不断尝试的过程,将想要调整的参数列出来一一训练。然后借助 Tensorboard 缩小探索的范围,最终得到一个自己满意的参数组合。
参考资料
[1]https://www.kaggle.com/c/digit-recognizer/data
[2]https://codelabs.developers.google.com/codelabs/cloud-tensorflow-mnist/#0
[3]https://github.com/GoogleCloudPlatform/tensorflow-without-a-phd.git
[4]https://www.tensorflow.org/api_docs/
相关文章
Tensorflow入门——单层神经网络识别MNIST手写数字
Tensorflow入门——多层神经网络MNIST手写数字识别
Tensorflow入门——分类问题cross_entropy的选择
吃了吗?来一份新手村小卖部的美食吧!@teamcn-shop如果不想再收到我的留言,请回复“取消”。
你好鸭,hongtao!
@cnbuddy给您叫了一份外卖!
由 @andrewma 岩哥 迎着台风 开着轮船 给您送来

斋烤鹅
吃饱了吗?跟我猜拳吧! 石头,剪刀,布~
如果您对我的服务满意,请不要吝啬您的点赞~
@onepagex
感谢投稿 :)
修改建议:
代码来自自己的代码仓,已补上标注了哈