强化学习—— SARSA 和 SARSA lambda 玩 MountainCar 爬坡上山

Image from unsplash.com by Jonatan Pie
上一篇文章我们介绍了用 Q-learning 的算法完成了小车爬坡上山的游戏,这篇文章我们来讲讲如何用 SARSA 算法完成同样挑战。
1. Q-Learning 和 SARSA 异同
Q - Learning 和 SARSA 有很多相似之处,他们均属于单步Temporal Difference (时间差分TD(0)算法,其通用的更新公式为
其中 td_target - Q[s,a] 部分又叫做 TD Error.
SARSA算法:
Q-learning:
不同之处在于,SARSA 是On-policy 的算法,即只有一个策略指挥行动并同时被更新。Q - Learning 是 Off-Policy 的算法, 探索的时候采用max 的策略来更新Policy(Q表),但行动的时候未必会走 max 奖励的那条路 (epsilon greedy 策略)。
由于两者的相似度很高,在代码中仅需要小小的改动即可实现 SARSA 算法。
同样的,为了方便与读者交流,所有的代码都放在了这里:
https://github.com/zht007/tensorflow-practice
3. SARSA 算法实现
Q表的建立,帮助函数等都与Q-Learning 一模一样,这里就不赘述了。仅仅在训练阶段有所不同。
首先,在初始化环境(state = env.reset()) 的同时,需要初始化 action (action = take_epilon_greedy_action(state, epsilon))
其次,获取 next_action (next_action = take_epilon_greedy_action(next_state, epsilon))
然后,依据前面的公式, td_target 中的 max 部分由下一个状态的 q[next_sate, next_action] 替换。
最后,action = next_action 将本循环中的 next_action 带入到下一个循环中
完整核心代码如下
for episode in range(EPISODES):
state = env.reset()
action = take_epilon_greedy_action(state, epsilon)
done = False
while not done:
next_state, reward, done, _ = env.step(action)
ep_reward += reward
next_action = take_epilon_greedy_action(next_state, epsilon)
if not done:
td_target = reward + DISCOUNT * q_table[get_discrete_state(next_state)][next_action]
q_table[get_discrete_state(state)][action] += LEARNING_RATE * (td_target - q_table[get_discrete_state(state)][action])
elif next_state[0] >= 0.5:
q_table[get_discrete_state(state)][action] = 0
state = next_state
action = next_action
Code from Github Repo with MIT license
4. SARSA lambda 算法
Q learning 和 SARSA 都是单步更新(TD(0))的算法。单步跟新的算法缺点就是在没有到达目标之前的那些『原地打转』的行动也被记录在案,每走一步,脚下的Q-表也被更新了,虽然这些行动是毫无意义的。
SARSA Lambda(λ), 即引入 λ 这个衰减系数,来解决这个问题。与γ用来衰减未来预期Q的值一样,λ是当智能体获得到达目标之后,在更新Q表的时候,给机器人一个回头看之前走过的路程的机会。相当于,机器人每走一步就会在地上插一杆旗子,然后机器人每走一步旗子就会变小一点。
于是我们需要另一个表,来记录每一个 state 的查旗子的状态(大小),这就需要一个与Q-表相同的eligibility trace 表 (E表)。
LAMBDA = 0.95
e_trace = np.zeros((DISCRETE_OS_SIZE + [env.action_space.n]))
与Q learning 和 SARSA 智能体每走一步仅更新脚下的Q表 (当前状态的Q(S, A))不同,SARSA lambda 每走一步,整个Q 表(和 E 表)都会被更新。完整算法如下:

Image from [1] by Sutton R.S.
首先,每一个回合均需要将 eligibility trace 表初始化为0。
其次,用 delta 来表示下一个状态的Q值和当前状态Q值的差值,并在当前状态"插旗"(E(S,A) += 1)。
最后,更新Q表和E表。
完整核心代码如下:
for episode in range(EPISODES):
state = env.reset()
action = take_epilon_greedy_action(state, epsilon)
# reset e_trace IMPORTANT
e_trace = np.zeros(DISCRETE_OS_SIZE + [env.action_space.n])
done = False
while not done:
next_state, reward, done, _ = env.step(action)
ep_reward += reward
next_action = take_epilon_greedy_action(next_state, epsilon)
if not done:
delta = reward + DISCOUNT * q_table[get_discrete_state(next_state)][next_action] - q_table[get_discrete_state(state)][action]
e_trace[get_discrete_state(state)][action] += 1
q_table += LEARNING_RATE * delta * e_trace
e_trace = DISCOUNT * LAMBDA * e_trace
elif next_state[0] >= 0.5:
q_table[get_discrete_state(state)][action] = 0
state = next_state
action = next_action
# Decaying is being done every episode if episode number is within decaying range
if END_EPSILON_DECAYING >= episode >= START_EPSILON_DECAYING:
epsilon -= epsilon_decay_value
Code from Github Repo with MIT license
4. Q-Learning, SARSA, SARSA lambda 对比
为了方便对比,我们将初始Q表的值均设置为0,表的长度均为20,跑10,000个回合, 每200个回合计算一下最小,平均和最大奖励。结果如下图所示:
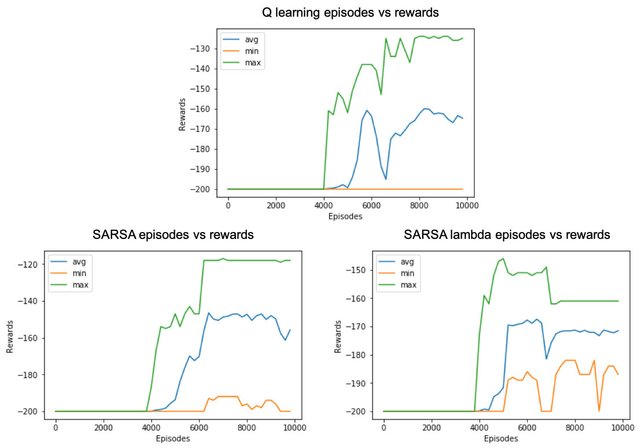
可以看出,三个算法均在4000 个回合开始 Converge。 但是由于是 Off - Policy 的算法,Q-learning 在最小奖励的表现不如SARSA算法,说明Q-learning 的智能体,更加大胆,勇于探索最大化奖励,SARSA 算法表现得更加谨慎,时刻遵守Policy的指导,平均奖励优于Q-learning.
参考资料
[1] Reinforcement Learning: An Introduction (2nd Edition)
[2] David Silver's Reinforcement Learning Course (UCL, 2015)
[3] Github repo: Reinforcement Learning
相关文章
AI学习笔记——动态规划(Dynamic Programming)解决MDP(1)
AI学习笔记——动态规划(Dynamic Programming)解决MDP(2)
AI学习笔记——MDP(Markov Decision Processes马可夫决策过程)简介
牛人👍👍👍
Posted using Partiko Android
谢谢夸奖😉
Posted using Partiko iOS
帅哥/美女!这是哪里?你是谁?我为什么会来这边?你不要给我点赞不要点赞,哈哈哈哈哈哈。假如我的留言打扰到你,请回复“取消”。
This post has been voted on by the SteemSTEM curation team and voting trail. It is elligible for support from @curie.
If you appreciate the work we are doing, then consider supporting our witness stem.witness. Additional witness support to the curie witness would be appreciated as well.
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Please consider setting @steemstem as a beneficiary to your post to get a stronger support.
Please consider using the steemstem.io app to get a stronger support.
Hi @hongtao,
这个网站似乎是在抄袭你的文章,虽然不知道他为何这样做: https://www.lizenghai.com/archives/20955.html
搜索一些资料时偶然发现的。如果你已经授权,请无视。