强化学习——Q-Learning SARSA 玩CarPole经典游戏

Image from unsplash.com by Ferdinand Stöhr
前文我们讲了如何用Q-learning 和 SARSA 玩推小车上山的游戏,这篇文章我们探讨一下如何完成Carpole平衡杆的游戏。
同样的,为了方便与读者交流,所有的代码都放在了这里:
https://github.com/zht007/tensorflow-practice
1. 环境分析
关于cartPole 游戏的介绍参见之前这篇文章,这里就不赘述了。通过阅读官方文档,Open AI 的 CartPole v0 可以发现,与MountainCar-v0 最大的区别是,CartPole 的状态有四个维度,分别是位置,速度,夹角和角速度。其中,速度和角速度的范围是正负无穷大。我们知道Q-learning 和 SARSA 都依赖有限的表示非连续状态的策略(Q-表),如何将无限连续的状态分割成有限不限连续的状态呢?
这里我们可以使用在神经网络中被曾被广泛应用的 sigmoid 函数,该函数可以将无限的范围投射在0到1之间。所以我们先建立这个 sigmoid 帮助函数。
def sigmoid(x):
return 1 / (1 + np.exp(-x))
2. 建立Q-表
与MountainCar 类似需要将连续的状态切割成离散的状态,不同的是速度和角速度需要用sigmoid 函数投射在有限的范围内。
DISCRETE_OS_SIZE = [Q_TABLE_LEN] * (len(env.observation_space.high))
observation_high = np.array([env.observation_space.high[0],
Q_TABLE_LEN*sigmoid(env.observation_space.high[1]),
env.observation_space.high[2],
Q_TABLE_LEN*sigmoid(env.observation_space.high[3])])
observation_low = np.array([env.observation_space.low[0],
Q_TABLE_LEN*sigmoid(env.observation_space.low[1]),
env.observation_space.low[2],
Q_TABLE_LEN*sigmoid(env.observation_space.low[3])])
discrete_os_win_size = (observation_high - observation_low) / DISCRETE_OS_SIZE
Code from github repo with MIT license
值得注意的是,由于Q-表的维度比较高,这里将其参数直接设置为0,否则随机产生150 * 150 *150 *2 个数需要花费很长时间。另外 Q_TABLE_LEN 我设置的是150 (大约占用6G的内存),过大的Q-表长度会导致内存溢出。
q_table = np.zeros((DISCRETE_OS_SIZE + [env.action_space.n]))
3. Q - Learning 和 SARSA
后面的代码与 MountainCar 几乎一模一样,这里就不赘述了,可参考前文。可以发现两者区别不大,均很好地完成了任务。
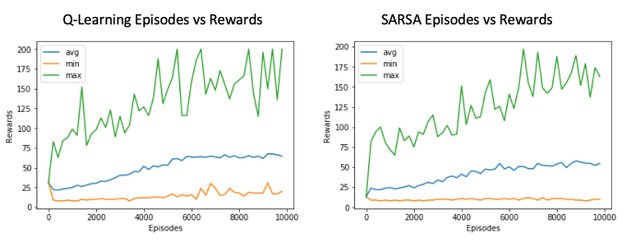
理论上来说,SARSA lambda 也是可以使用的,但是由于智能体每走一步均需要更新整个Q表,然而该表又实在太大实践起来计算量非常之巨大,感兴趣的读者可自行尝试。
参考资料
[1] Reinforcement Learning: An Introduction (2nd Edition)
[2] David Silver's Reinforcement Learning Course (UCL, 2015)
[3] Github repo: Reinforcement Learning
相关文章
强化学习—— SARSA 和 SARSA lambda 玩 MountainCar 爬坡上山
强化学习—— Q-Learning 玩 MountainCar 爬坡上山
AI学习笔记——动态规划(Dynamic Programming)解决MDP(1)
AI学习笔记——动态规划(Dynamic Programming)解决MDP(2)
AI学习笔记——MDP(Markov Decision Processes马可夫决策过程)简介
吃了吗?你好!家中可愛的寵物照想要跟大家分享嗎?或是出去玩拍到一些可愛的動物,別忘了到@dpet分享,可以得到@dpet的獎勵喔!倘若你想让我隐形,请回复“取消”。
Congratulations @hongtao! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPThis post has been voted on by the SteemSTEM curation team and voting trail. It is elligible for support from @curie.
If you appreciate the work we are doing, then consider supporting our witness stem.witness. Additional witness support to the curie witness would be appreciated as well.
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Please consider setting @steemstem as a beneficiary to your post to get a stronger support.
Please consider using the steemstem.io app to get a stronger support.