深度强化学习——Policy Gradient 玩转 CartPole 游戏

Image from unsplash.com by helloquence
前面的文章我们介绍了 Q-learning, DQN 等方法都是基于价值的强化学习方法,今天我们介绍的 Policy Gradient 方法是基于策略的强化学习方法。该方法的理论部分已经介绍过了,这里就不赘述了,直接上手项目。
本文的全部代码可在我的 github repo 中查看
https://github.com/zht007/tensorflow-practice
1. 监督学习回顾
为了更好地理解 Policy Gradient 算法,我们用监督学习的分类问题作为类比。
以手写数字识别的项目为例,:
- 将图片作为输入传给神经网络。
- 神经网络会给该图片属于哪一类(数字 0 到 9)给出一个评分(logits)。
- 评分(logits)通过 Softmax 就可以转换为属于每一类(数字 0 到 9)的概率(Probability)。
- 通过 Cross Entropy (交叉商) 对比与真实标签的“距离”
- 最后这个“距离” 就作为loss function (损失函数) 反向传回神经网络进行参数更新。

Image from github repo with Apache-2.0 license
如上图所示 Cross entropy 的公式如下
2. Policy 梯度上升
在强化学习中,我们用神经网络来参数化策略,神经网络扮演策略的角色,在神经网络输入状态,就可以输出策略价值函数,指导智能体的行动。我们在之前的文章中讲到,优化策略函数(神经网络)的过程可以利用用梯度上升(Gradient Ascent)的方法,以获取最价值。然而目标函数的策略梯度与 Cross entropy 非常相似:
定理:对于任何可微的策略π(s,a),对于任何策略的目标函数J(θ)策略梯度都是:
如果 Q(s, a) 作为“标签”的话,上面的公式与 Cross Entropy 公式仅相差一个负号,这个负号的作用恰好可以将反向传播的梯度下降,转换成我们需要的梯度上升。
当然如果觉得这个理论理解起来比较困难,我还有一个更加简单的角度,我们是这样操作的:
- 首先,我们采用蒙特卡洛的方法完成一个完整的 episode 记录其中每一个[s, a, r]:
$$
\left{s_{1}, a_{1}, r_{2}, \dots, s_{T-1}, a_{T-1}, r_{T}\right} \sim \pi_{\theta}
$$
然后,将 s1, s2, ... sT 带入神经网络,预测得到每一个状态下的行动概率。将实际行动作为“标签”带入 corss entropy 的公式。但是这个“标签” 并不是真正的标签,并不能指导神经网络朝正确的方向更新。我们需要乘以奖励r,奖励r 的作用相当于对“标签”的评价,奖励越大神经网络就朝着“标签”的方向更新,反之就向相反的方向更新。
最后,我们再讲这个新的函数作为 loss fuction 传给神经网络进行更新。

Image from github repo with Apache-2.0 license
最后,还需要注意的是,这里的奖励 R 即 r1, r2, ... rT 在送入上式进行反向传播之前是需要进行,discount 和 normalize 两步处理。discount 很好理解,即离结束越远的奖励需要 discount 越多,离结束回合越近需要 discount 越少。同时,normalize 的目的是为了鼓励那些正确地动作,因为特别是在游戏初期,在大多数的随机行动中,正确步伐所获得的奖励往往会容易被淹没在众多的随机行动所带来的奖励了。
3. Tensorflow 代码实践
关于 CartPole 的游戏之前已经介绍够多了,初始化就不多说了,与之前相似。重点是构建 PGAgent 对象。
3.1 Agent 神经网络大脑
对于神经网络,self.states, self.actions 和 self.discounted_episode_rewards 即前面介绍的输入,“标签”,和处理后的奖励。self.sample_op 的作用是根据概率选择行动
def _build_net(self):
self.states = tf.placeholder(tf.float32, [None,OBSERVATION_SPACE_SIZE])
self.actions = tf.placeholder(tf.int32, [None,])
self.discounted_episode_rewards = tf.placeholder(tf.float32, [None,])
fc1 = tf.layers.dense(
inputs = self.states,
units = 10,
activation = tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1)
)
act_logits = tf.layers.dense(
inputs = fc1,
units = ACTION_SPACE_SIZE,
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
)
self.actions_prob = tf.nn.softmax(act_logits)
#sample an action from predicted probabilities
self.sample_op = tf.multinomial(logits=act_logits, num_samples=1)
neg_log_prob = tf.reduce_sum(-tf.log(self.actions_prob) * tf.one_hot(self.actions, ACTION_SPACE_SIZE),axis =1)
loss = tf.reduce_mean(neg_log_prob * self.discounted_episode_rewards)
self.train_op = tf.train.AdamOptimizer(0.001).minimize(loss)
Code from github repo with MIT license
3.2 Discount and Normalize Rewards
正如之前提到的,Rewards需要经过 discount 和 normalize 两个步骤,函数如下:
def discount_rewards(self, rewards):
discount_rewards = np.zeros_like(rewards)
running_add = 0
for t in reversed(range(len(rewards))):
running_add = running_add * GAMMA + rewards[t]
discount_rewards[t] = running_add
mean = np.mean(discount_rewards)
std = np.std(discount_rewards)
discount_rewards = (discount_rewards - mean)/std
return discount_rewards
3.4 训练过程
训练过程分为三个步骤
首先,初始化每个episode (回合) 的 states, actions 和 rewards。
episode_states, episode_actions, episode_rewards = [],[],[] #Reset single step reward episode_reward = 0然后, 通过agent 的“大脑“ 选择行动得到该行动的 state, action 和 reward
action = agent.choose_action(current_state) next_state, reward, done, _ = env.step(action)接着,将s, a 和 r 收集到 states, actions 和 rewards 中
episode_states.append(current_state) episode_actions.append(action) episode_rewards.append(reward)最后,将收集到的 states, actions 和 rewards 传回 agent “大脑” 进行学习
agent.train(np.vstack(episode_states), np.array(episode_actions), np.array(episode_rewards))
Code from github repo with MIT license
3.5 训练结果
Policy Gradient 的训练时间还是蛮久的,经过30000 个回合的训练,最大,平均和最小奖励都在稳步上升。对于最大奖励在5000 个回合之后奖励就基本稳定在最大奖励200了,平均奖励和最小奖励在训练过程中都有上下起伏,但是总体上是在收敛和上升的。
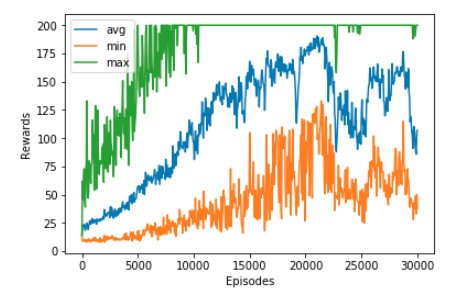
Image crested by @hongtao
4. 总结
本文介绍的 Policy Gradient 方法是深度学习与强化学习结合的一个非常典型的案例,由于跟监督学习非常相似,所以比起 Q-learning 来说更加容易理解。Policy Gradient 作为基于策略的强化学习方法如何与基于价值的Q learning 相结合呢? 这将是我们接下来研究的问题。
参考资料
[1] Reinforcement Learning: An Introduction (2nd Edition)
[2] David Silver's Reinforcement Learning Course (UCL, 2015)
[3] Github repo: Reinforcement Learning
相关文章
AI学习笔记——动态规划(Dynamic Programming)解决MDP(1)
AI学习笔记——动态规划(Dynamic Programming)解决MDP(2)
AI学习笔记——MDP(Markov Decision Processes马可夫决策过程)简介
你今天过的开心吗?来 @steemgg 玩游戏吧,决战到天亮倘若你想让我隐形,请回复“取消”。