强化学习实战——MC(蒙特卡洛)玩21点扑克游戏
通过理论和实战,我们知道,在已知的MDP环境下,可以用动态规划(DP)的方法来获得最佳策略,指导智能体(Agent)行动。DP方法要求环境是已知的,然而实际上我们会遇到更多未知的环境,这个时候就需要用其他方法了。之前的文章介绍过MC和TD (Temporal-Defference) 的理论,这篇文章就用MC方法来玩21点扑克牌游戏。
同样的,为了方便与读者交流,所有的代码都放在了这里:
https://github.com/zht007/tensorflow-practice
1. 关于21点游戏
1.1 规则简介
21点的游戏规则详细很容易就能够找到,这里进行简单的介绍。
- 在这里智能体(Agent)扮演玩家(Player),对方是庄家(Dealer)。
- 点数(Score):2-10的点数为牌面数字;J,Q,K是10点;A有两种算法,1或者11,算11总点数不超过21时则必须算成11(usable),否则算作1。
- 庄家需要亮(Show)一张牌,玩家根据自己手中的牌和庄家亮的牌决定是要牌(hits)还是停牌(sticks)。
- 庄家要牌和停牌的规则是固定的,即点数小于17必须要牌,否则停牌。
- 爆牌(goes bust):牌总数操过21点,谁爆牌谁输,谁首先凑到21点谁赢,没有爆牌的时候谁点数大谁赢,同时凑到21点为和局。
1.2 转换成MDP
了解规则后,我们将游戏转换成MDP,MDP的几大要素:状态(S: State),行动(A: Action),奖励(R: Reward),策略Policy,状态值函数V(s): State-Value Function,行动值函数Q(s, a)Action-Value Function。
行动A:要牌(hits)还是停牌(sticks)
状态S:状态是由双方目前牌的点数决定的,但是当玩家点数小于等于11时,当然会毫不犹豫选择要牌,所以真正涉及到做选择的状态是12-21点的状态,此时庄家亮牌有A-10种情况,再加上是否有11的A(usable A),所以21点游戏中所有的状态一共只有200个。
奖励R:玩家赢牌奖励为1,输牌奖励为-1,和局和其他状态奖励为0。
策略Policy:该状态下,要牌和停牌的概率
2. MC策略评估
在给定策略下,为什么我们不用上一篇文章提到的DP方法进行策略评估呢?DP方法需要look one step ahead,假设玩家手里牌点数为14,庄家亮牌为10,你需要计算要牌和停牌之后所有可能性,下一张牌是什么?庄家可能抽到什么?离获得奖励有多远?等等,这几乎是不可能的。
MC可以通过抽样方式,直接根据策略实践,从而获取奖励和学习V(s),克服了DP方法的限制。这里采用首次访问MC方法。大致分为三步:
第一步:根据策略采样,直到游戏结束,获得一个episode的 (S0, A0, R1), (S1, A1, R2), . . . , (ST-1, AT-1, RT)
episode = []
state = env.reset()
for t in range(100):
action = policy(state)
next_state, reward, done, _ = env.step(action)
episode.append((state, action, reward))
if done:
break
state = next_state
该部分代码参考github with MIT license
第二步: 计算首次出现s状态的Reward,直到这个episode结束总共累积的Reward。
states_in_episode = set([tuple(x[0]) for x in episode])
for state in states_in_episode:
# Find the first occurance of the state in the episode
first_occurence_idx = next(i for i,x in enumerate(episode) if x[0] == state)
# Sum up all rewards since the first occurance
G = sum([x[2]*(discount_factor**i) for i,x in enumerate(episode[first_occurence_idx:])])
# Calculate average return for this state over all sampled episodes
returns_sum[state] += G
returns_count[state] += 1.0
该部分代码参考github with MIT license
第三步:若干个epsoide之后,将累积的R平均就得到该s下的V(s)了。
V[state] = returns_sum[state] / returns_count[state]
给定玩家的策略,当分数小于20则要牌,否则停牌
def sample_policy(observation):
"""
A policy that sticks if the player score is >= 20 and hits otherwise.
"""
score, dealer_score, usable_ace = observation
return 0 if score >= 20 else 1
该部分代码参考github with MIT license
下图为500,000个epsoide之后的V(s)
V(s)的分布只能告诉我们当前策略下每个状态(你的点数,庄家亮牌,是否有usable A)的价值,我们如何使用V(s)来改进我们的策略,从而获得最大几率获胜的可能性呢?这就是我们下一节要讨论的内容。
3. MC控制
当然我们的目的不仅仅是对当前策略进行评估,我们希望改进策略在游戏中获得最大的收益。与DP一样,MC可以采用评估加改进(Policy Evaluation and Policy Improvement)的方式,迭代更新策略,最终可以收敛到一个最佳的策略。
当然我们在MC控制中采用策略评估的时候,需要加入对行动的评估,即Q(s, a)行动值函数的评估。但是如果我们采用DP中Greedy的方式来改进策略会遇到问题。由于MC是用采样的方式更新Q(s, a),这就意味着我们很可能错过一些状态和行动,而且永远也无法更新该状态和行动的Q函数了。这就是典型的探索利用困境(Explore Exploit Delima)。
解决探索利用困境,我们可以使用epsilon-greedy 方法,或者将探索和利用的policy分开,采用off-policy的方法更新策略。
3.1 On-Policy 的 epsilon-greedy采样法
On-Policy即评估和改进的策略是同一个策略,为避免探索利用困境,我们采用 epsilon-greedy的方法。
第一步:对于21点的游戏,我们定义 epsilon-greedy policy.
def make_epsilon_greedy_policy(Q, epsilon, nA):
def policy_fn(observation):
A = np.ones(nA, dtype=float) * epsilon / nA
best_action = np.argmax(Q[observation])
A[best_action] += (1.0 - epsilon)
return A
return policy_fn
该部分代码参考github with MIT license
其中Q是一个dictionary,为该状态下对应的行动,这样定义epsilon greedy policy 既保证了最优行动的几率最大,同时也让采取其他行动几率为一个非零的小值(epsilon / nA )。这样就保证了智能体在采样的时候能够探索未知的状态和行动。
第二步:与MC评估的第一步一致,根据策略采样,直到游戏结束,获得一个episode的 (S0, A0, R1), (S1, A1, R2), . . . , (ST-1, AT-1, RT)
policy = make_epsilon_greedy_policy(Q, epsilon, env.action_space.n)
episode = []
state = env.reset()
for t in range(100):
probs = policy(state)
action = np.random.choice(np.arange(len(probs)), p=probs)
next_state, reward, done, _ = env.step(action)
episode.append((state, action, reward))
if done:
break
state = next_state
该部分代码参考github MIT license
注意与MC评估不同的是,action无法从policy中直接得出,而是根据概率随机选择的,也就是有可能智能体会"探索"非最优行动。
第三步:计算首次出现该s 和 a 的Reward,直到这个episode结束,总共累积的Reward。平均Reward并更新Q表。Q表更新的同时,Policy也就自动更新了。
sa_in_episode = set([(tuple(x[0]), x[1]) for x in episode])
for state, action in sa_in_episode:
sa_pair = (state, action)
# Find the first occurance of the (state, action) pair in the episode
first_occurence_idx = next(i for i,x in enumerate(episode)
if x[0] == state and x[1] == action)
# Sum up all rewards since the first occurance
G = sum([x[2]*(discount_factor**i) for i,x in enumerate(episode[first_occurence_idx:])])
# Calculate average return for this state over all sampled episodes
returns_sum[sa_pair] += G
returns_count[sa_pair] += 1.0
Q[state][action] = returns_sum[sa_pair] / returns_count[sa_pair]
# The policy is improved implicitly by changing the Q dictionary
return Q, policy
该部分代码参考github MIT license
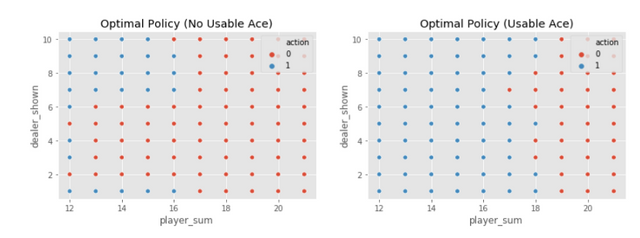
下图是500,000个episode之后Q表中各个状态对应的Action值,Action只有两个值0(停牌)和1(要牌),读者就可以尝试用下图的策略指导玩21点的游戏啦。举个例子,比如你现在手上牌是14点,没有可作为11的A,庄家亮牌为8,那么根据左图所示,最好的策略就是要牌。
3.2 Off-Policy的 Weighted Importance采样法
Off-Policy就是将最终想要得到的目标策略(Target Policy)和用于探索的行为策略(Behavior Policy)分离,对目标策略采取Greedy的改进方式,而对实际行动的行为策略采用随机探索的改进方式从而解决了探索利用困境。当然Off-Policy 还有很多其他的优点比如学习历史经验,学习别人的经验等等。
这部分涉及到的理论比较复杂,可参考[1] [2]中的相关内容。简单解释即首先用Behavior Policy指导智能体进行MC采样,然后用包含Importance Sampling Ratio 函数来更新Target Policy。Importance Sampling Ratio是Target Policy和Behavior Policy在同一路径下的概率比值。
Target Policy的Q(s, a)函数在MC采样下需要平均,这里采用加权平均的方法,包含Importatnce Sampling Ratio的权重简记为 W,最后,我们通过递推的方法更新 W 即可跟新Q(s, a)。
第一步:生成两种policy方法,random policy 用于Behavior Policy,greedy policy用于Target Policy.
def create_random_policy(nA):
A = np.ones(nA, dtype=float) / nA
def policy_fn(observation):
return A
return policy_fn
def create_greedy_policy(Q):
def policy_fn(state):
A = np.zeros_like(Q[state], dtype=float)
best_action = np.argmax(Q[state])
A[best_action] = 1.0
return A
return policy_fn
该部分代码参考github with MIT license
第二步:用Behavior Policy进行MC采样,这里与On-Policy 的方法类似。
target_policy = create_greedy_policy(Q)
for i_episode in range(1, num_episodes + 1):
episode = []
state = env.reset()
for t in range(100):
# Sample an action from our policy
probs = behavior_policy(state)
action = np.random.choice(np.arange(len(probs)), p=probs)
next_state, reward, done, _ = env.step(action)
episode.append((state, action, reward))
if done:
break
state = next_state
该部分代码参考github with MIT license
第三步:递推的方法更新W和Q,Target Policy 也就自动更新了。注意由于是采用递推的方法,该episode是从后往前计算的。
G = 0.0
# The importance sampling ratio (the weights of the returns)
W = 1.0
# For each step in the episode, backwards
for t in range(len(episode))[::-1]:
state, action, reward = episode[t]
# Update the total reward since step t
G = discount_factor * G + reward
# Update weighted importance sampling formula denominator
C[state][action] += W
# Update the action-value function using the incremental update formula (5.7)
# This also improves our target policy which holds a reference to Q
Q[state][action] += (W / C[state][action]) * (G - Q[state][action])
# If the action taken by the behavior policy is not the action
# taken by the target policy the probability will be 0 and we can break
if action != np.argmax(target_policy(state)):
break
W = W * 1./behavior_policy(state)[action]
return Q, target_policy
该部分代码参考github with MIT license
最后,经过500,000 个episod我们得到的最佳策略,与上一节采用On-Policy MC 方法的结果稍有差异,但基本一致。

参考资料
[1] Reinforcement Learning: An Introduction (2nd Edition)
[2] David Silver's Reinforcement Learning Course (UCL, 2015)
[3] Github repo: Reinforcement Learning
相关文章
AI学习笔记——动态规划(Dynamic Programming)解决MDP(1)
AI学习笔记——动态规划(Dynamic Programming)解决MDP(2)
AI学习笔记——MDP(Markov Decision Processes马可夫决策过程)简介
同步到我的简书
https://www.jianshu.com/u/bd506afc6fc1
帅哥/美女!欢迎各位玩drugwars的华人朋友加入Dragon帮会!已经有一群兄弟姐妹在等待你的加入了!如果不想再收到我的留言,请回复“取消”。
文章内容似乎部分出现了两次,可以检查下是什么缘故
谢谢指出,可能是从编辑器中复制粘贴过来的时候出的问题,已修复:)
Posted using Partiko iOS
谢谢,参考资料部分仍有重复
谢谢指出,已修复
Posted using Partiko iOS
This post has been voted on by the SteemSTEM curation team and voting trail. It is elligible for support from @curie.
If you appreciate the work we are doing, then consider supporting our witness stem.witness. Additional witness support to the curie witness would be appreciated as well.
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Please consider setting @steemstem as a beneficiary to your post to get a stronger support.
Please consider using the steemstem.io app to get a stronger support.