Tensorflow入门——多层神经网络MNIST手写数字识别

Image source: unsplash.com by Sergey Pesterev
上一篇文章中,我们用Tensorflow搭建了单层神经网络,该网络对MNIST手写识别率能到达90%。如何进一步提高识别率呢?Let's go deeper, 搭建更多层的神经网络吧。
同样的,为了方便与读者交流,所有的代码都放在了这里:
Repository:
https://github.com/zht007/tensorflow-practice
1. 初始化W和B
权重(Weight)W和偏置(Bias)B的shape,是由每一层神经元的个数决定的,输出层的神经元个数保证与Class的数量一致(10个),输入层和隐藏层的神经元数目是没有固定的要求的。
多层神经网络实际上就像是在单层神经网络的基础上"叠蛋糕"。这里我们设计5层的神经网络,神经元个数从输入到输出分别为200,100,60,30和10个。
L = 200
M = 100
N = 60
O = 30
同样的,首先初始化每一层的权重和偏置。注意这里使用tf.truncated_normal方法随机初始化W。偏置B要尽量选择一个较小的非零数值来初始化,以适应激活函数RELU最有效区间。
W1 = tf.Variable(tf.truncated_normal([784, L], stddev=0.1)) # 784 = 28 * 28
B1 = tf.Variable(tf.ones([L])/10)
W2 = tf.Variable(tf.truncated_normal([L, M], stddev=0.1))
B2 = tf.Variable(tf.ones([M])/10)
W3 = tf.Variable(tf.truncated_normal([M, N], stddev=0.1))
B3 = tf.Variable(tf.ones([N])/10)
W4 = tf.Variable(tf.truncated_normal([N, O], stddev=0.1))
B4 = tf.Variable(tf.ones([O])/10)
W5 = tf.Variable(tf.truncated_normal([O, 10], stddev=0.1))
B5 = tf.Variable(tf.zeros([10]))
该部分代码部分参考[2][3] with Apache License 2.0
2. 搭建神经网络
搭建神经网络类似于"叠蛋糕",copy&paste输出层就好了,与输出层不同的是,在输入层和隐藏层中,我们用了比较流行的RELU激活函数。当然,输入层不要忘了Reshape。
XX = tf.reshape(X,[-1,784])
Y1 = tf.nn.relu(tf.matmul(XX, W1) + B1)
Y2 = tf.nn.relu(tf.matmul(Y1, W2) + B2)
Y3 = tf.nn.relu(tf.matmul(Y2, W3) + B3)
Y4 = tf.nn.relu(tf.matmul(Y3, W4) + B4)
Ylogits = tf.matmul(Y4, W5) + B5
Y = tf.nn.softmax(Ylogits)
该部分代码部分参考[2][3] with Apache License 2.0
Optimizer的选择已经神经网络的训练与单层神经网络没有任何区别,这里就不讨论了,感兴趣的朋友可以去查看源码,接下来我们来看看这个5层神经网络的表现吧。
3. 识别效果
我们用Adam的优化器,0.005的学习速率,100的batch_size,训练了20000个Iteration。最后我们发现训练组的准确率几乎能达到100%,但是验证组的的准确率却始终在97%附近徘徊
Iteration 19900: loss_train=0.000003: loss_val=0.128829: acc_train=1.000000: acc_val=0.978571
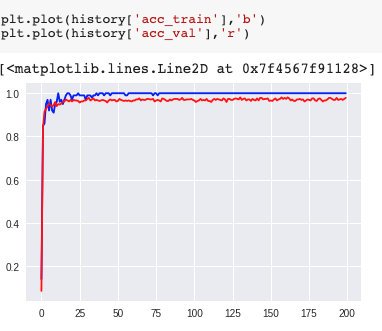
是的,这就是深度学习典型的overfitting问题。
4. 可变学习速率
学习速率决定了梯度下降过程中所迈的步子的大小。可以想象,如果迈的步子太大很有可能一步就跨过了最优点,最后只能在最优点附近不停地徘徊;如果步子迈得太小,下降速度又会太慢,会浪费很多训练时间。
学习速率如果可以改变,就能解决这个问题。我们可以在初始的Iteration中选择比较大的学习速率,之后逐渐减小,这就是Learning Rate Decay.
当然我们这里要增加两个palceholder,一个用来存放训练速率,另一个用来存储当前的步数(literation数) ,并最后在Seesion中通过 feed_dict 传到训练中去。
lr = tf.placeholder(tf.float32)
step = tf.placeholder(tf.int32)
Tensorflow 提供Learning rate decay的方法,这个表示训练速率随着Iteration的增加从0.003一指数形式下降到0.0001。
lr = 0.0001 + tf.train.exponetial_decay(0.003, step, 2000, 1/math.e)
5. Dropout
对付overfitting,我们可以在训练中Dropout掉一定的神经元。在Tensorflow中使用Dropout只需要在相应层中"增加"一个Dropout层。
比如第四层
Y4 = tf.nn.relu(tf.matmul(Y3d, W4) + B4)
Y4d = tf.nn.dropout(Y4, rate = drop_rate)
注意在验证的时候,drop rate要设置为0
加上learning rate decay 和 dropout之后的训练sesssion如下
history = {'acc_train':list(),'acc_val':list(),
'loss_train':list(),'loss_val':list(),
'learning_rate':list()}
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = ch.next_batch(100)
sess.run(train, feed_dict={X: batch[0], Y_true: batch[1], step: i, drop_rate: 0.25})
# PRINT OUT A MESSAGE EVERY 100 STEPS
if i%100 == 0:
# Test the Train Model
feed_dict_train = {X: batch[0], Y_true: batch[1], drop_rate: 0.25}
feed_dict_val = {X:ch.test_images, Y_true:ch.test_labels, drop_rate: 0}
matches = tf.equal(tf.argmax(Y,1),tf.argmax(Y_true,1))
acc = tf.reduce_mean(tf.cast(matches,tf.float32))
history['acc_train'].append(sess.run(acc, feed_dict = feed_dict_train))
history['acc_val'].append(sess.run(acc, feed_dict = feed_dict_val))
history['loss_train'].append(sess.run(cross_entropy, feed_dict = feed_dict_train))
history['loss_val'].append(sess.run(cross_entropy, feed_dict = feed_dict_val))
history['learning_rate'].append(sess.run(lr, feed_dict = {step: i}))
print("Iteration {}:\tlearning_rate={:.6f},\tloss_train={:.6f},\tloss_val={:.6f},\tacc_train={:.6f},\tacc_val={:.6f}"
.format(i,history['learning_rate'][-1],
history['loss_train'][-1],
history['loss_val'][-1],
history['acc_train'][-1],
history['acc_val'][-1]))
print('
')
saver.save(sess,'models_saving/my_model.ckpt'
6. 训练效果
可以看到通过dropout 和 learning rate decay 之后,神经网络对MNIST手写数字的识别率已经能提高到98%了,如何进一步提高识别率呢?我们就必须会引入卷积神经网络了。
参考资料
[1]https://www.kaggle.com/c/digit-recognizer/data
[2]https://codelabs.developers.google.com/codelabs/cloud-tensorflow-mnist/#0
[3]https://github.com/GoogleCloudPlatform/tensorflow-without-a-phd.git
[4]https://www.tensorflow.org/api_docs/
相关文章
Tensorflow入门——单层神经网络识别MNIST手写数字
Tensorflow入门——分类问题cross_entropy的选择
同步到我的简书
你今天过的开心吗?想一展歌喉吗?好声音@cn-voice欢迎你~如果不想再收到我的留言,请回复“取消”。
Congratulations @hongtao! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Do not miss the last post from @steemitboard:
本文的部分代码(如1、2节中)与Deep Learning with TensorFlow中的部分代码相似度较高。
对此的相关问题:
(1)如果本文中的代码参考了此书或其他源代码、文档或书籍,请注明引用;
(2)如果代码确有引用书籍或其他文档或代码仓库中代码,请确认源代码的版权说明或开源协议,是否能够引用?
没有参考该书,参考的是google 官方教程, 在参考资料中已列出
https://codelabs.developers.google.com/codelabs/cloud-tensorflow-mnist/#0
Posted using Partiko iOS
已将该教程的代码仓补充到了文中
Posted using Partiko iOS
谢谢,该项目的license是Apache License 2.0,故而可以用于商业引用与出版。如有必要,可在文中说明此点。
在引用代码、图片、文字等他人作品时,请都务必具有版权意识、并表示对原作者工作的尊重。Freedom is not free。我们在享受开源世界带来便利的同时,也需理解开源精神的内涵,向原作者的工作致谢哦 :)
谢谢提醒,会更加注意的:-)
This post has been voted on by the SteemSTEM curation team and voting trail in collaboration with @curie.
If you appreciate the work we are doing then consider voting both projects for witness by selecting stem.witness and curie!
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!