Tokenizer: Get a better understanding of what counts as a token (Grok)
In the context of Large Language Models (LLMs), a token is a unit of text that the model processes. Tokens can represent whole words, subwords, characters, or even punctuation, depending on the tokenisation method used.
How Tokens Work in LLMs
- Tokenisation: Before processing text, LLMs convert input text into tokens using a tokeniser. This step breaks text into manageable pieces based on predefined rules.
- Vocabulary: LLMs have a fixed vocabulary of tokens they can understand. If a word isn't in the vocabulary, it may be split into multiple subword tokens.
- Processing: Each token is assigned a numerical representation (embedding), which the model processes to generate output.
Examples of Tokenisation
Word-based: "Hello world!" → ["Hello", "world", "!"]
Subword-based (Byte-Pair Encoding, BPE, used in GPT models):
- "unhappiness" → ["un", "happiness"]
- "running" → ["run", "ning"]
Character-based (used in some models):
- "Hello" → ["H", "e", "l", "l", "o"]
Why Tokens Matter
- Cost: LLMs charge based on token usage (e.g., OpenAI models like GPT-4 have pricing based on tokens).
- Context Length: Models have a maximum number of tokens they can process in a single request (e.g., GPT-4 Turbo has a 128K token limit).
- Processing Speed: More tokens mean longer processing times and higher computational costs.
Grok Tokenizer
You can click the Tokenizer in Grok
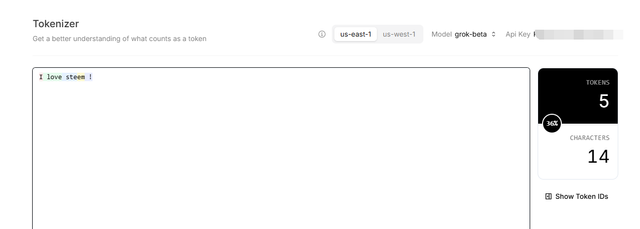
To have a rough idea of the tokens - IMHO, they are similar to words!

Steem to the Moon🚀!
- You can rent Steem Power via rentsp!
- You can swap the TRON:TRX/USDT/USDD to STEEM via tron2steem!
- You can swap the STEEM/SBD to SOL Solana via steem2sol!
- You can swap the STEEM/SBD to ETH Ethereum via steem2eth!
- You can swap the STEEM/SBD to Tether USDT (TRC-20) via steem2usdt!
- You can swap the STEEM/SBD to TRX (TRON) via steem2trx!
- You can swap the STEEM/SBD to BTS (BitShares) via steem2bts!
- Register a free STEEM account at SteemYY!
- Steem Block Explorer
- ChatGPT/Steem Integration: You can type !ask command to invoke ChatGPT
- Steem Witness Table and API
- Other Steem Tools