ARTIFICIAL INTELLIGENCE

Everything we love about civilization is a product of intelligence, so amplifying our human intelligence with artificial intelligence has the potential of helping civilization flourish like never before – as long as we manage to keep the technology beneficial.“
From SIRI to self-driving autos, counterfeit consciousness (AI) is advancing quickly. While sci-fi frequently depicts AI as robots with human-like attributes, AI can incorporate anything from Google's hunt calculations to IBM's Watson to self-governing weapons.

Computerized reasoning today is legitimately known as limited AI (or powerless AI), in that it is intended to play out a restricted assignment (e.g. just facial acknowledgment or just web looks or just driving an auto). Be that as it may, the long haul objective of numerous scientists is to make general AI (AGI or solid AI). While limit AI may outflank people at whatever its particular assignment is, such as playing chess or explaining conditions, AGI would beat people at almost every intellectual undertaking.

WHY RESEARCH AI SAFETY?
In the close term, the objective of keeping AI's effect on society valuable spurs examine in numerous zones, from financial aspects and law to specialized points, for example, check, legitimacy, security and control. Though it might be minimal in excess of a minor annoyance if your workstation crashes or gets hacked, it turns into all the more critical that an AI framework does what you need it to do in the event that it controls your auto, your plane, your pacemaker, your robotized exchanging framework or your energy network. Another fleeting test is keeping a staggering weapons contest in deadly self-ruling weapons.
In the long haul, an essential inquiry is the thing that will happen if the mission for solid AI succeeds and an AI framework turns out to be superior to people at all intellectual undertakings. As pointed out by I.J. Great in 1965, outlining more astute AI frameworks is itself a subjective errand. Such a framework could possibly experience recursive self-change, setting off an insight blast abandoning human acumen far. By developing progressive new advances, such a superintelligence may enable us to annihilate war, illness, and neediness, thus the production of solid AI may be the greatest occasion in mankind's history. A few specialists have communicated concern, however, that it may likewise be the last, unless we figure out how to adjust the objectives of the AI to our own before it moves toward becoming superintelligent.
There are some who question whether solid AI will ever be accomplished, and other people who demand that the production of superintelligent AI is ensured to be valuable. At FLI we perceive both of these conceivable outcomes, yet in addition perceive the potential for a manmade brainpower framework to deliberately or unexpectedly cause incredible mischief. We trust look into today will enable us to better get ready for and forestall such conceivably negative outcomes later on, in this way appreciating the advantages of AI while maintaining a strategic distance from traps.

By what method CAN AI BE DANGEROUS?
Most analysts concur that a superintelligent AI is probably not going to display human feelings like love or despise, and that there is no motivation to anticipate that AI will turn out to be purposefully generous or vindictive. Rather, while considering how AI may turn into a hazard, specialists think two situations in all probability:
The AI is customized to accomplish something pulverizing: Autonomous weapons are computerized reasoning frameworks that are modified to execute. In the hands of the wrong individual, these weapons could without much of a stretch reason mass setbacks. In addition, an AI weapons contest could coincidentally prompt an AI war that additionally brings about mass losses. To abstain from being upset by the foe, these weapons would be intended to be to a great degree hard to just "kill," so people could conceivably lose control of such a circumstance. This hazard is one that is available even with limit AI, however develops as levels of AI knowledge and independence increment.
The AI is customized to accomplish something valuable, yet it builds up a dangerous technique for accomplishing its objective: This can happen at whatever point we neglect to completely adjust the AI's objectives to our own, which is strikingly troublesome. On the off chance that you ask a dutiful savvy auto to take you to the airplane terminal as quick as could be expected under the circumstances, it may get you there pursued by helicopters and canvassed in upchuck, doing not what you needed but rather truly what you requested. On the off chance that a superinte
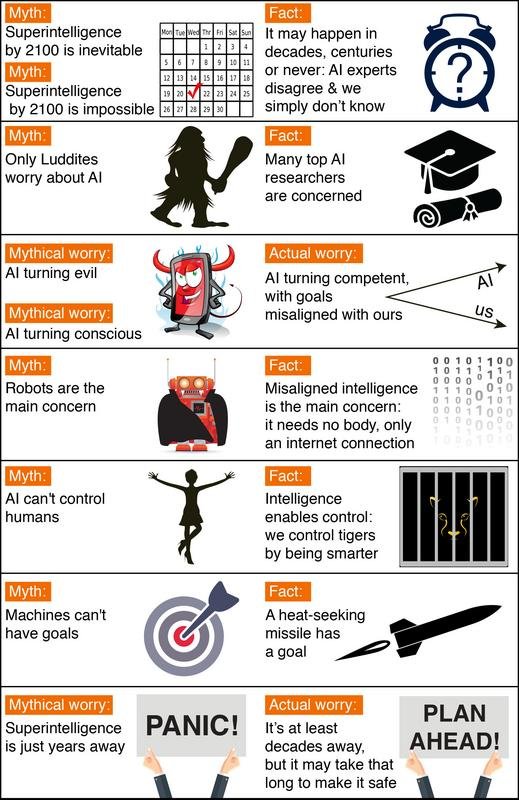
Course of events MYTHS
The principal myth respects the course of events: to what extent will it take until the point when machines enormously supersede human-level knowledge? A typical misinterpretation is that we know the appropriate response with incredible sureness.
One prevalent misconception is that we know we'll get superhuman AI this century. Indeed, history is loaded with innovative over-building up. Where are those combination control plants and flying autos we were guaranteed we'd have at this point? AI has additionally been more than once finished built up previously, even by a portion of the originators of the field. For instance, John McCarthy (who instituted the expression "manmade brainpower"), Marvin Minsky, Nathaniel Rochester and Claude Shannon composed this excessively idealistic figure about what could be expert amid two months with stone-age PCs: "We suggest that a 2 month, 10 man investigation of computerized reasoning be completed amid the mid year of 1956 at Dartmouth College [… ] An endeavor will be made to discover how to influence machines to utilize dialect, shape deliberations and ideas, tackle sorts of issues now held for people, and enhance themselves. We feel that a critical progress can be made in at least one of these issues if a deliberately chose gathering of researchers chip away at it together for a late spring."
Then again, a prevalent counter-myth is that we know we won't get superhuman AI this century. Analysts have made an extensive variety of appraisals for how far we are from superhuman AI, yet we unquestionably can't state with incredible certainty that the likelihood is zero this century, given the horrid reputation of such techno-doubter forecasts. For instance, Ernest Rutherford, apparently the best atomic physicist of his opportunity, said in 1933 — under 24 hours before Szilard's creation of the atomic chain response — that atomic vitality was "moonshine." And Astronomer Royal Richard Woolley called interplanetary travel "articulate bilge" in 1956. The most extraordinary type of this myth is that superhuman AI will never arrive on the grounds that it's physically unimaginable. Nonetheless, physicists realize that a cerebrum comprises of quarks and electrons organized to go about as a capable PC, and that there's no law of material science keeping us from building significantly more clever quark blobs.

There have been various studies asking AI specialists how long from now they think we'll have human-level AI with no less than half likelihood. All these reviews have a similar conclusion: the world's driving specialists dissent, so we essentially don't have the foggiest idea. For instance, in such a survey of the AI scientists at the 2015 Puerto Rico AI meeting, the normal (middle) answer was by year 2045, however a few specialists speculated several years or more.
There's additionally a related myth that individuals who stress over AI believe it's just a couple of years away. Truth be told, a great many people on record agonizing over superhuman AI get it's still at any rate decades away. However, they contend that insofar as we're not 100% beyond any doubt that it won't occur this century, it's brilliant to begin security inquire about now to get ready for the projection. Huge numbers of the wellbeing issues related with human-level AI are hard to the point that they may take a long time to fathom. So it's reasonable to begin inquiring about them now as opposed to the night prior to a few software engineers drinking Red Bull choose to switch one on.
Debate MYTHS
Another normal misinterpretation is that the main individuals harboring worries about AI and supporting AI security examine are luddites who don't know much about AI. At the point when Stuart Russell, writer of the standard AI course reading, said this amid his Puerto Rico talk, the group of onlookers chuckled noisily. A related misguided judgment is that supporting AI wellbeing research is tremendously dubious. Indeed, to help a humble interest in AI security examine, individuals don't should be persuaded that dangers are high, only non-irrelevant — similarly as an unassuming interest in home protection is advocated by a non-unimportant likelihood of the home burning to the ground.
It might be that media have influenced the AI security to face off regarding appear to be more dubious than it truly is. All things considered, fe
Videos
Stuart Russell – The Long-Term Future of (Artificial) Intelligence
Humans Need Not Apply
Nick Bostrom on Artificial Intelligence and Existential Risk
Stuart Russell Interview on the long-term future of AI
Value Alignment – Stuart Russell: Berkeley IdeasLab Debate Presentation at the World Economic Forum
Social Technology and AI: World Economic Forum Annual Meeting 2015
Stuart Russell, Eric Horvitz, Max Tegmark – The Future of Artificial Intelligence
Talks from the Beneficial AI 2017 conference in Asilomar, CA
Jaan Tallinn on Steering Artificial Intelligence
Media Articles
Concerns of an Artificial Intelligence Pioneer
Transcending Complacency on Superintelligent Machines
Why We Should Think About the Threat of Artificial Intelligence
Stephen Hawking Is Worried About Artificial Intelligence Wiping Out Humanity
Artificial Intelligence could kill us all. Meet the man who takes that risk seriously
Artificial Intelligence Poses ‘Extinction Risk’ To Humanity Says Oxford University’s Stuart Armstrong
What Happens When Artificial Intelligence Turns On Us?
Can we build an artificial superintelligence that won’t kill us?
Artificial intelligence: Our final invention?
Artificial intelligence: Can we keep it in the box?
Science Friday: Christof Koch and Stuart Russell on Machine Intelligence (transcript)
Transcendence: An AI Researcher Enjoys Watching His Own Execution
Science Goes to the Movies: ‘Transcendence’
Our Fear of Artificial Intelligence
Essays by AI Researchers
Stuart Russell: What do you Think About Machines that Think?
Stuart Russell: Of Myths and Moonshine
Jacob Steinhardt: Long-Term and Short-Term Challenges to Ensuring the Safety of AI Systems
Eliezer Yudkowsky: Why value-aligned AI is a hard engineering problem
Eliezer Yudkowsky: There’s No Fire Alarm for Artificial General Intelligence
Open Letter: Research Priorities for Robust and Beneficial Artificial Intelligence
Research Articles
Intelligence Explosion: Evidence and Import (MIRI)
Intelligence Explosion and Machine Ethics (Luke Muehlhauser, MIRI)
Artificial Intelligence as a Positive and Negative Factor in Global Risk (MIRI)
Basic AI drives
Racing to the Precipice: a Model of Artificial Intelligence Development
The Ethics of Artificial Intelligence
The Superintelligent Will: Motivation and Instrumental Rationality in Advanced Artificial Agents
Wireheading in mortal universal agents
Research Collections
Bruce Schneier – Resources on Existential Risk, p. 110
Aligning Superintelligence with Human Interests: A Technical Research Agenda (MIRI)
MIRI publications
Stanford One Hundred Year Study on Artificial Intelligence (AI100)
Preparing for the Future of Intelligence: White House report that discusses the current state of AI and future applications, as well as recommendations for the government’s role in supporting AI development.
Artificial Intelligence, Automation, and the Economy: White House report that discusses AI’s potential impact on jobs and the economy, and strategies for increasing the benefits of this transition.
IEEE Special Report: Artificial Intelligence: Report that explains deep learning, in which neural networks teach themselves and make decisions on their own.
Case Studies
The Asilomar Conference: A Case Study in Risk Mitigation (Katja Grace, MIRI)
Pre-Competitive Collaboration in Pharma Industry (Eric Gastfriend and Bryan Lee, FLI): A case study of pre-competitive collaboration on safety in industry.
Blog posts and talks
AI control
AI Impacts
No time like the present for AI safety work
AI Risk and Opportunity: A Strategic Analysis
Where We’re At – Progress of AI and Related Technologies: An introduction to the progress of research institutions developing new AI technologies.
AI safety
Wait But Why on Artificial Intelligence
Response to Wait But Why by Luke Muehlhauser
Slate Star Codex on why AI-risk research is not that controversial
Less Wrong: A toy model of the AI control problem
What Should the Average EA Do About AI Alignment?
Waking
Congratulations @yoyo4you! You received a personal award!
Click here to view your Board of Honor
Congratulations @yoyo4you! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Vote for @Steemitboard as a witness to get one more award and increased upvotes!