Understanding Artificial Intelligence! Blog post #1 - Deep Learning
Almost every technology that let you wonder "How do they know that?" deploy deep learning algorithms - the secret sauce of artificial intelligence. They can identify your voice, a picture of you, and can do much more.
If you would like to have an basic understanding of how deep learning works in general, you should read this blog post series. This is the first part.

Generally — Deep Learning is a field of Artificial Intelligence (AI) that uses several processing steps, also known as layers, to learn and subsequently recognize the representations of data within these processing steps. These methods have dramatically improved the state of the art in speech recognition, visual object recognition, and many other domains.
The Deep Learning architectures called convolutional neural networks (CNNs) are especially interesting because they have brought about breakthroughs in processing video and images. And in the same time, they are relatively straight forward to understand . Their quick off-the-shelf use is enabled by open source libraries such as TensorFlow and Caffe.
At the end of this blog post, I aim especially at accelerating the learning process by parallelizing it on accelerator cards.
1. About Deep Learning
Deep Learning is based on a set of algorithms that attempt to model high-level abstractions in data by using multiple processing layers. For example, images can be represented in many ways such as a vector of intensity values per pixel, or in an abstract way, as a set of edges, and regions of paricular shape. Numerous scientists around the world are researching actively in this topic area to develop efficient training algorithms for deep neural networks (DNNs).
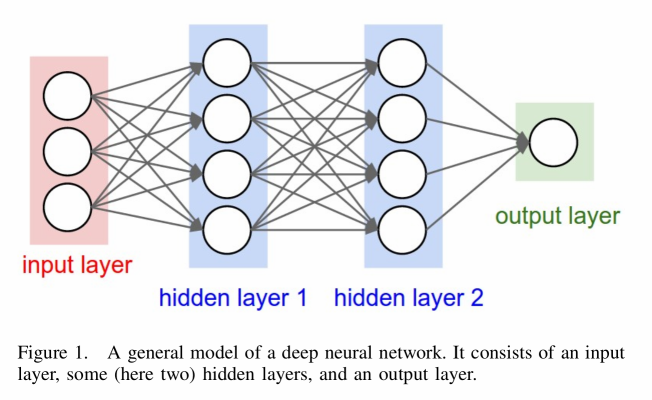
DNNs are the underlying architectures, which, in contrast to neural networks (NNs), consist of multiple hidden layers. Figure 1 shows a general model of a DNN, where the processes, the number, and the order of hidden layers vary according to the architecture.
The first NN was developed in 1943 by McCulloch and Pitts and consisted of only one neuron that summed up input weights. Its output was either 1, if a threshold was crossed, or 0 otherwise.
However, NNs had been of minor interest until around the year 2005. Since then, GPUs have been used to boost computational power by orders of magnitude, and new training techniques have been developed. Particularly noteworthy are the new techniques of G. Hinton, Y. LeCun, and Y. Bengio which use unlabelled training data for unsupervised learning and labelled training data supervised fine-tuning. This is also called the backpropagation of errors. (Basically just updating the deciding weights of the network. Backpropagation of errors is at least a blog post on its own. Questions? Ask!)
Moreover, the US market-research institute tractica forecasts that annual software revenue for enterprise applications of Deep Learning will reach 10.4 billion US dollars in 2024, up from 150 million US dollars this year. Thus, it can be seen that Deep Learning is attracting a lot of attention and Deep Learning components can be critical to a company’s product.
2. The different Kinds of Deep Learning Networks
Since Deep Learning is fast-growing, numerous deep architectures already exist and new ones appear every few weeks. They can be classified into architectures for generative models, architectures for discriminative models and a combination of these to hybrid architectures.
The fundamental difference between the two models is the following: if you have some input data x and you want to label it into classes y, a generative model will learn the joint probability P (x, y), while a discriminative model will learn the conditional probability P (y|x). Generally speaking, a generative model is a full probabilistic model of all variables, whereas a discriminative model provides a model only for the target variables conditional on the observed variables. Both approaches can be converted into one another easily. (Questions? Ask!)

In Figure 2 the classification tree is shown. It is not very strict, since some architectures, e.g. deep recurrent neural networks (RNNs), can be used for both generative and discriminative models.
Deep convolutional neural networks (CNNs) are discriminative models, because they are used in image, video, speech, and audio processing, which requires discriminative behaviour in sampling target weights conditional on the observed quantities.
In this blog post series I put a special emphasis on convolutional neural networks.
NEXT PART: CNNs and its layers - simplified explanation.
I hope this format was good for you. If not, leave me a comment and I will work on it.
Further questions? Ask!
It will be probably a blog post series of around 4 posts. So, stay tuned!
If you liked it so far, then like, resteem and follow me: @martinmusiol !
Thank you!
P.S.: This is me now:

HERE YOU CAN FIND THE FOLLOW-UP POST: https://steemit.com/technology/@martinmusiol/understanding-artificial-intelligence-blog-post-2-how-does-ai-identify-objects-in-images
indeed this is interesting never know it worked like this. Thanks for the post!
you are welcome
Nice post, looking forward to more. Hopefully you will consider also providing some articles for those interested in additional reading.
I will, thank you : )
Interesting post... So this is how AI exhibits its high level of intelligence? Deep learning... Am eager to learn more about this technological feat. Thanks for this educative information. I am following your account henceforth.
please accept this gift
Thanks. Exactly, this is the big picture. There is of course much more to it. :)